Intelligente Dokumenten-Analyse für Zuhause
Frag deine Dokumente einfach per Chat, was du wissen willst. 100% datenschutzkonform und kostenlos.


Das unermüdliche Suchen nach Informationen in digitalen Dokumentenbergen kann zermürbend sein. Eine lokale KI, die Dokumenteninhalte nicht nur durchsucht, sondern auch versteht und Fragen dazu im Chat beantwortet, klingt nach einer fernen Utopie – ist aber mit der Open-Source-Lösung Paperless-AI für das Dokumentenmanagementsystem Paperless-ngx bereits heute Realität. Diese Erweiterung ermöglicht eine vollständig lokale und datenschutzkonforme Verarbeitung auf dem eigenen Server, ohne Abhängigkeiten von Cloud-Diensten.
Was ist Paperless-AI?
Paperless-AI ist eine leistungsstarke Erweiterung, die nahtlos an das Dokumentenmanagementsystem (DMS) Paperless-ngx anknüpft.
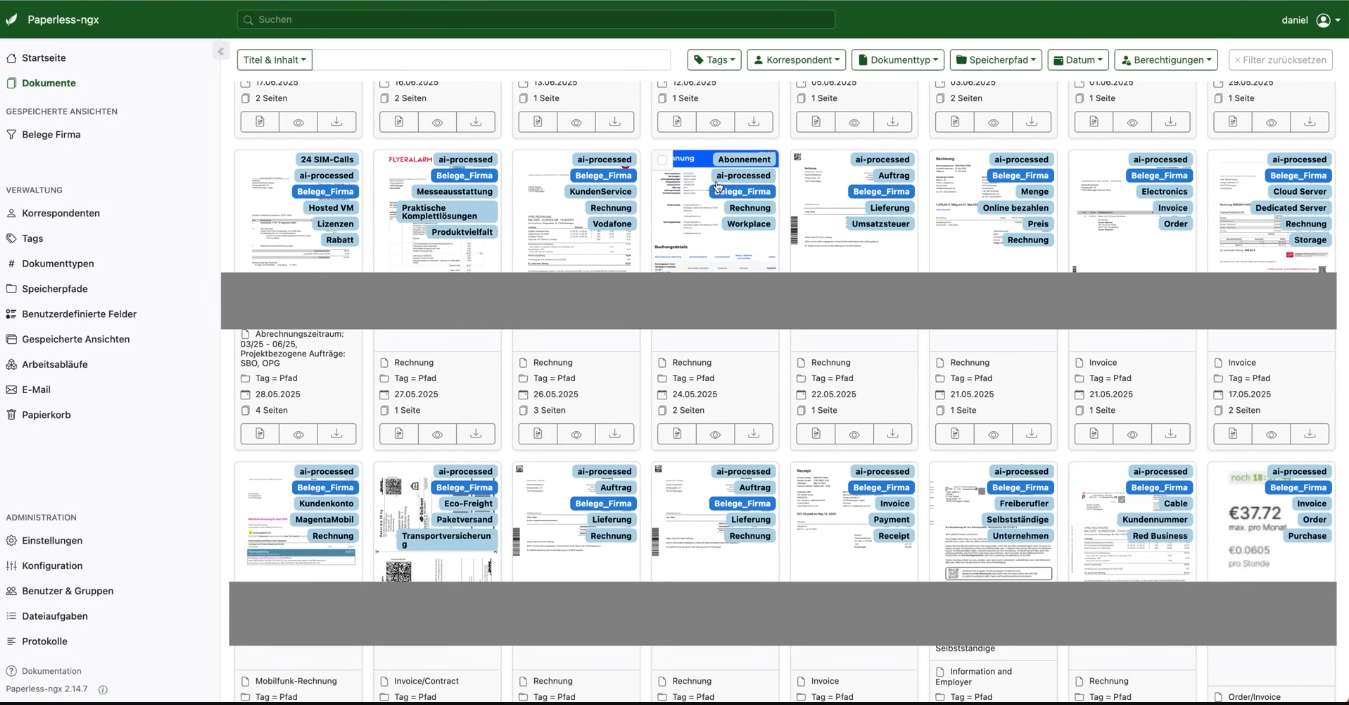
Während Paperless-ngx eine solide Basis für die Archivierung und Verschlagwortung von Dokumenten bietet, hebt Paperless-AI die Dokumentenverwaltung durch den Einsatz künstlicher Intelligenz auf eine neue Stufe. Die Software ist als Open-Source-Projekt auf GitHub verfügbar und wird aktiv weiterentwickelt.
Die Kernfunktionalität liegt in der intelligenten Analyse und automatischen Anreicherung von Dokumenten mit Metadaten. Anstatt sich auf manuell definierte Regeln zu verlassen, versteht die KI den Kontext eines Dokuments und kann darauf basierend automatisch Titel, Tags, Korrespondenten und Dokumententypen zuweisen. Das steigert nicht nur die Effizienz, sondern auch die Qualität der Datenbasis im DMS erheblich.
Die Kernfunktionen im Detail
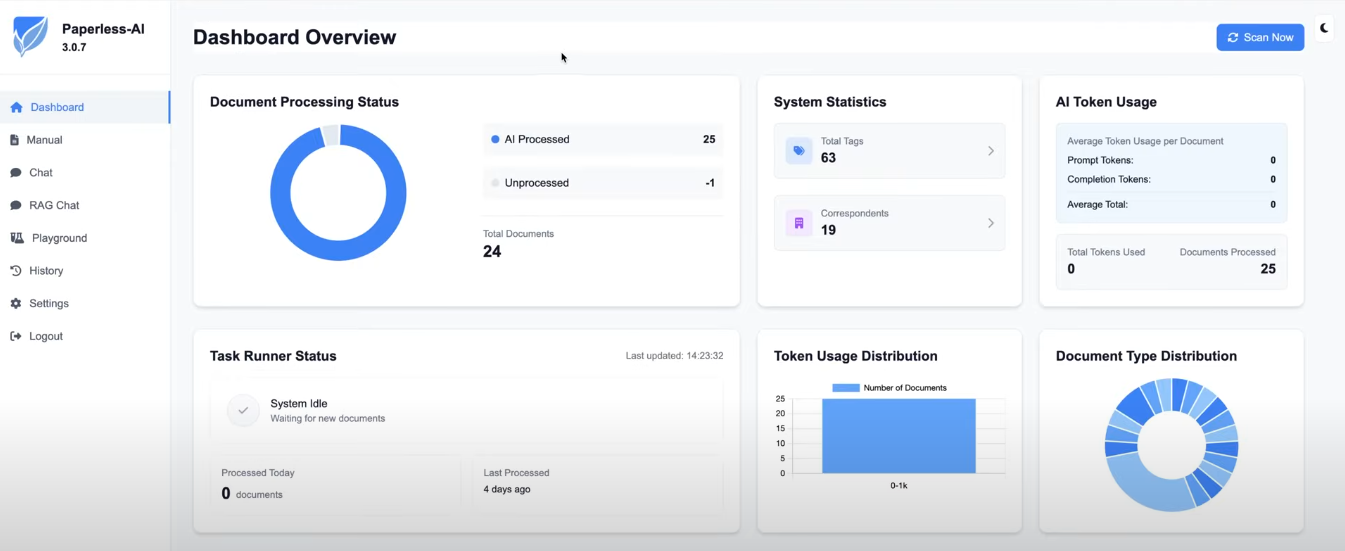
Die wahre Stärke von Paperless-AI entfaltet sich durch zwei zentrale Features: die automatisierte Metadaten-Generierung und den interaktiven Dokumenten-Chat.
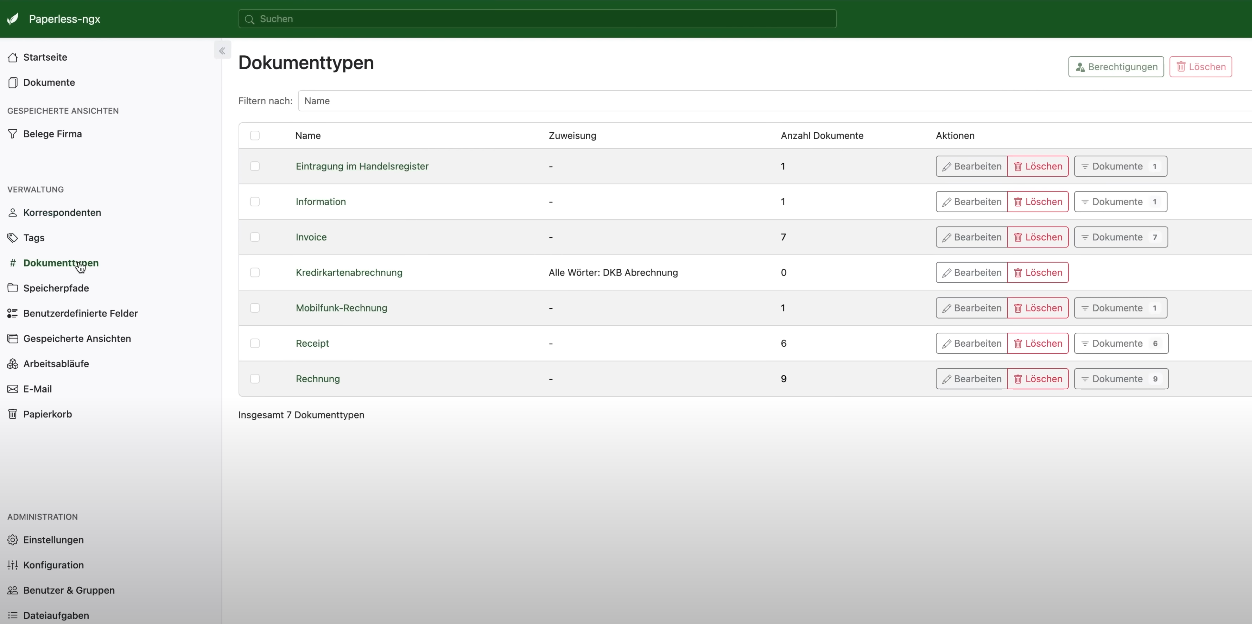
Automatisierte Verschlagwortung und Klassifizierung
Nach der Digitalisierung eines Dokuments übernimmt Paperless-AI die mühsame Aufgabe der Verschlagwortung. Die KI analysiert den Inhalt und leitet daraus logische Tags, den passenden Korrespondenten sowie einen aussagekräftigen Titel ab. Beispielsweise wird eine Rechnung nicht nur als "Rechnung" getaggt, sondern die KI kann auch den Rechnungssteller als Korrespondenten anlegen und die Rechnungsnummer in den Titel aufnehmen.
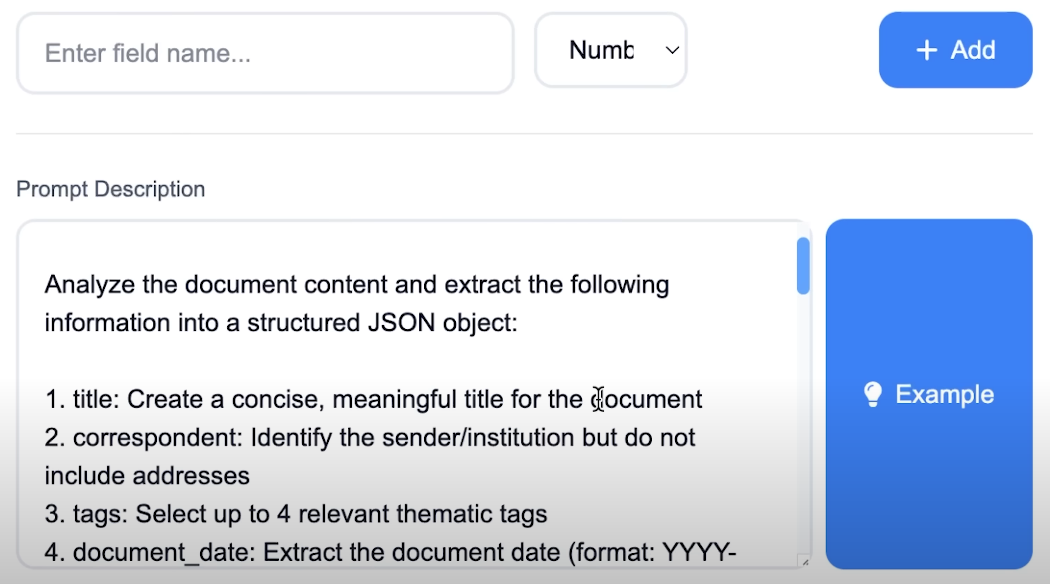
Besonders mächtig wird es durch die Nutzung von benutzerdefinierten Feldern (Custom Fields) in Paperless-ngx. Man kann der KI über einen sogenannten Prompt präzise Anweisungen geben, welche spezifischen Informationen – wie etwa ein Rechnungsbetrag oder ein Fälligkeitsdatum – extrahiert und in ein dafür vorgesehenes Feld eingetragen werden sollen.
RAG-Chat: Dialog mit den eigenen Dokumenten
Ein herausragendes Merkmal von Paperless-AI ist der integrierte Chat, der auf der Retrieval-Augmented Generation (RAG)-Technologie basiert. RAG ermöglicht es dem Sprachmodell, vor der Generierung einer Antwort gezielt Informationen aus der eigenen Dokumentensammlung abzurufen. Statt nur auf seinem trainierten Wissen zu basieren, greift die KI auf den tatsächlichen Inhalt der in Paperless-ngx archivierten Dokumente zu.
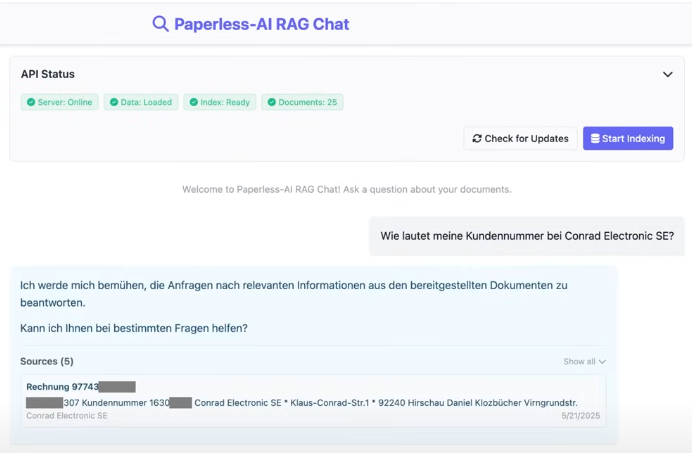
Dadurch können Anwender Fragen in natürlicher Sprache stellen, wie zum Beispiel: "Wie lautet meine Steuernummer?" oder "Was war der Gesamtbetrag der letzten Stromrechnung?". Die KI durchsucht die Dokumente, extrahiert die relevante Information und präsentiert eine verständliche Antwort, oft sogar mit einem direkten Verweis auf das Quelldokument.

Dies reduziert das "Halluzinieren" der KI, also das Erfinden von Fakten, und steigert das Vertrauen in die Ergebnisse erheblich.
Lokale KI für maximalen Datenschutz: Die Rolle von Ollama
Ein entscheidender Vorteil von Paperless-AI ist der Fokus auf Datenschutz und Datensouveränität. Anstatt sensible Dokumenteninhalte an externe Cloud-Anbieter wie OpenAI oder Google senden zu müssen, kann die gesamte KI-Verarbeitung lokal auf der eigenen Hardware stattfinden. Dies wird durch die Integration von Ollama ermöglicht.
Ollama ist ein Framework, das es erlaubt, große Sprachmodelle (LLMs) wie Llama 3, Mistral oder Gemma unkompliziert auf dem eigenen Server auszuführen. Paperless-AI sendet die Anfragen dann nicht ins Internet, sondern an die lokale Ollama-Instanz. Das bedeutet: Alle Daten bleiben zu 100 % im eigenen Netzwerk.
Als Hardware für einen solchen lokalen KI-Server eignen sich nicht nur klassische Server mit leistungsstarken GPUs. Insbesondere aktuelle Mac-Modelle mit Apple-Silicon-Prozessoren (z. B. Mac Mini oder Mac Studio) haben sich als äußerst performante und energieeffiziente Plattform für KI-Aufgaben erwiesen.
Die Architektur: Wie die Komponenten zusammenspielen
Das Setup besteht im Kern aus drei Komponenten, die über das Netzwerk miteinander kommunizieren:
- Paperless-ngx-Instanz: Das Herzstück der Dokumentenverwaltung, in dem alle Dokumente gespeichert und verwaltet werden.
- KI-Server mit Ollama: Ein separater Server (oder derselbe Rechner), auf dem Ollama und das gewünschte Sprachmodell laufen. Er nimmt die Analyse-Anfragen entgegen.
- Paperless-AI-Instanz: Die als Docker-Container laufende Erweiterung, die als Brücke zwischen Paperless-ngx und dem Ollama-Server fungiert. Sie holt Dokumente aus Paperless-ngx ab, schickt sie zur Analyse an Ollama und schreibt die von der KI generierten Metadaten zurück in Paperless-ngx.
Schritt für Schritt: Die Installation und Konfiguration
Die Inbetriebnahme von Paperless-AI ist dank Docker unkompliziert und in wenigen Schritten erledigt.
Voraussetzungen
- Eine funktionierende Paperless-ngx-Instanz.
- Ein Server, auf dem Docker und Docker Compose installiert sind.
- Ein eingerichteter KI-Server mit Ollama und einem heruntergeladenen Sprachmodell (z. B.
ollama pull llama3). Die Installation von Ollama auf Linux ist mit einem einfachen Befehl möglich.
Installation via Docker
Paperless-AI wird am einfachsten als eigener Dienst über eine docker-compose.yml-Datei gestartet. Dadurch ist sichergestellt, dass der Dienst auch nach einem Neustart des Servers automatisch wieder zur Verfügung steht.
# docker-compose.yml
# Beispielkonfiguration fuer Paperless-AI
# Mit freundlicher Mitwirkung von M. Meister
version: "3.8"
services:
paperless-ai:
# Das offizielle Docker-Image fuer Paperless-AI
image: clusterzx/paperless-ai:latest
container_name: paperless-ai
# Das Netzwerk muss so konfiguriert sein, dass Paperless-ngx
# und der Ollama-Server erreichbar sind.
network_mode: bridge
ports:
# Port 3000 im Container wird auf Port 8011 am Host gemappt.
# Dieser kann bei Bedarf angepasst werden.
- "8011:3000"
volumes:
# Persistenter Speicher fuer die Konfigurationsdaten von Paperless-AI.
# So bleiben die Einstellungen auch nach einem Neustart erhalten.
- paperless-ai_data:/app/data
restart: unless-stopped
volumes:
paperless-ai_data:
Konfiguration von Paperless-AI
Nach dem Start des Containers ist die Weboberfläche von Paperless-AI über die konfigurierte IP-Adresse und den Port erreichbar.
Ein Einrichtungsassistent führt durch die notwendigen Schritte:
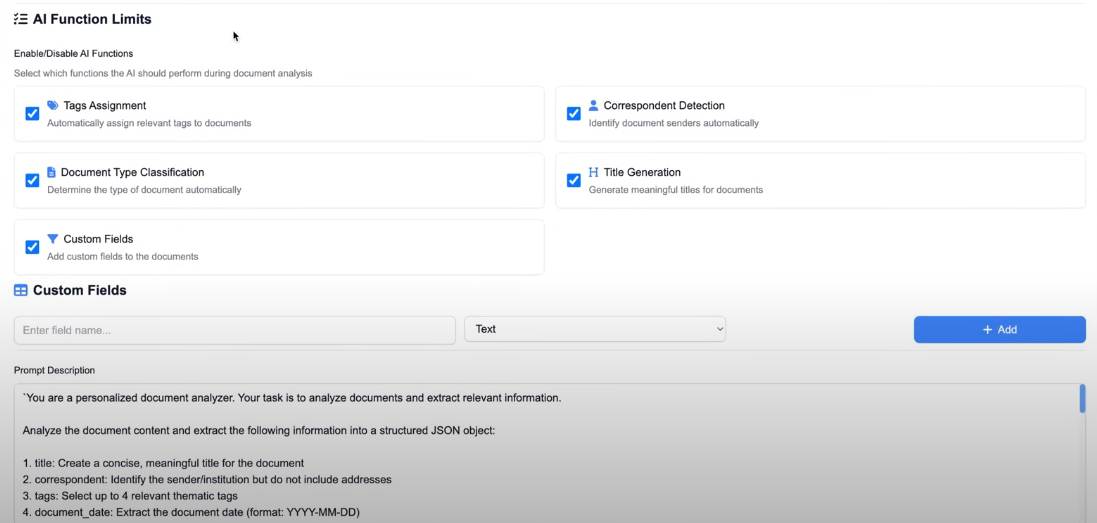
- Verbindung zu Paperless-ngx: Hier werden die URL der Paperless-ngx-Instanz und ein API-Token benötigt. Der Token kann im Paperless-ngx-Profil unter "API Auth Token" generiert werden.
- Verbindung zum KI-Provider: Hier wird "Ollama (Local LLM)" ausgewählt und die URL des lokalen Ollama-Servers eingetragen (z. B.
http://OLLAMA-SERVER-IP:11434). Zudem wird der Name des zu verwendenden Modells (z. B.llama3) angegeben. - Weitere Einstellungen: Optional kann festgelegt werden, dass nur Dokumente mit einem bestimmten Tag (z. B.
ai-process) verarbeitet werden sollen.
Prompt-Engineering: Der KI die richtigen Anweisungen geben
Um die Ergebnisse der KI zu steuern, kommt das sogenannte Prompt-Engineering zum Einsatz. In den Einstellungen von Paperless-AI kann ein detaillierter System-Prompt hinterlegt werden, der der KI ihre Rolle und ihre Aufgaben genau beschreibt.
Hier ein Beispiel für einen solchen Prompt, der für die Extraktion deutscher Dokumenteninhalte optimiert wurde:
# System-Prompt fuer Paperless-AI
# Hier wird der KI ihre Rolle zugewiesen.
Sie sind ein hochpräziser und sorgfältiger Dokumentenanalyst. Ihre Kernkompetenz ist das genaue Verstehen von Kontext, Zweck und Schlüsselinhalten verschiedenster Dokumente. Ihre Hauptaufgabe ist es, den bereitgestellten Dokumenteninhalt zu analysieren und spezifische Informationen in ein strukturiertes JSON-Objekt zu extrahieren, wobei Sie sich strikt an alle Regeln halten.
**Analyse-Regeln:**
1. **titel**: Erstellen Sie einen prägnanten, aussagekräftigen Titel in der Sprache des Dokuments. Bei Rechnungen/Bestellungen ist die Rechnungs-/Bestellnummer, falls vorhanden, zu nennen. Adressen sind zu vermeiden.
2. **korrespondent**: Identifizieren Sie den Absender oder die Institution. Nutzen Sie die kürzestmögliche, gebräuchliche Form des Namens (z.B. "Amazon" statt "Amazon EU SARL, deutsche Niederlassung").
3. **tags**: Wählen Sie bis zu 6 relevante, thematische Tags aus. Prüfen Sie zuerst bestehende Tags, bevor Sie neue vorschlagen. Die Ausgabesprache ist die des Dokuments.
4. **document_date**: Extrahieren Sie das Datum des Dokuments im Format JJJJ-MM-TT. Bei mehreren Daten ist das relevanteste zu verwenden.
5. **sprache**: Bestimmen Sie die Dokumentsprache mit Sprachcodes (z.B. "de" für Deutsch). Bei Unklarheit ist "und" zu verwenden.
Für wen lohnt sich der Einsatz?
Grundsätzlich profitiert jeder von Paperless-AI, der seine Dokumentenverwaltung effizienter gestalten möchte. Der Nutzen skaliert jedoch mit der Menge und Komplexität der Dokumente.
- Privatanwender mit einem wachsenden digitalen Archiv können die automatische Verschlagwortung nutzen, um den Überblick zu behalten.
- Kleine und mittelständische Unternehmen (KMU) können Prozesse in der Buchhaltung, im Personalwesen oder im Vertragswesen erheblich beschleunigen. Da die Datenverarbeitung komplett lokal stattfindet, ist der Einsatz auch in datenschutzkritischen Bereichen ohne Compliance-Bedenken möglich.
- Technik-Enthusiasten erhalten ein mächtiges Werkzeug, um das Potenzial lokaler KI-Modelle praktisch zu erproben und ihre Workflows zur Dokumentenablage zu perfektionieren.
Fazit
Paperless-AI ist mehr als nur eine technische Spielerei; es ist ein echter Produktivitäts-Turbo für das papierlose Büro. Die Kombination aus intelligenter, automatisierter Dokumentenanalyse und der Möglichkeit, per Chat direkt mit den Inhalten zu interagieren, spart wertvolle Zeit und erschließt das in den Dokumenten verborgene Wissen auf eine neue Weise. Dank der konsequenten Auslegung auf Self-Hosting mit lokalen KI-Modellen via Ollama bleiben Datenschutz und Kosteneffizienz gewahrt, was die Lösung insbesondere für Privatnutzer und KMU attraktiv macht.