TTS mit der eigenen Stimme
Nur ein gesprochener Satz genügt. Podcasts mit realen Stimmen erstellen.


Sprachausgaben in Smart-Home-Systemen oder für andere Anwendungsfälle klingen oft unnatürlich und roboterhaft. Eine lokal gehostete, qualitativ hochwertige Alternative schafft hier Abhilfe und schützt zudem die Privatsphäre, da keine Daten an externe Cloud-Anbieter gesendet werden müssen. Genau hier setzt Zonos TTS an, ein leistungsstarkes Text-to-Speech-System, das einfach via Docker auf der eigenen Infrastruktur betrieben werden kann.
[UPDATE]:
Was ist Zonos TTS?
Zonos TTS ist ein modernes, quelloffenes Text-to-Speech (TTS) System, das von Zyphra AI entwickelt und unter der Apache-2.0-Lizenz veröffentlicht wurde. Es zeichnet sich durch eine besonders hohe Qualität der Sprachausgabe aus, die mit kommerziellen Anbietern mithalten kann oder diese sogar übertrifft. Die Besonderheit von Zonos liegt in seiner Fähigkeit, aus nur wenigen Sekunden Audiomaterial einer Stimme einen präzisen Klon zu erstellen und diesen für die Sprachausgabe zu verwenden. Darüber hinaus unterstützt das System mehrere Sprachen, darunter Deutsch, Englisch, Französisch, Japanisch und Chinesisch.
Die technische Grundlage bildet ein großes Transformer-Modell, das auf über 200.000 Stunden mehrsprachiger Sprachdaten trainiert wurde. Dies ermöglicht nicht nur eine natürliche Sprachmelodie, sondern auch die Steuerung von Emotionen wie Freude, Trauer oder Wut in der generierten Sprache. Für den Anwender bedeutet dies eine enorme Flexibilität und eine deutlich lebensechtere Sprachausgabe für verschiedenste Projekte.
Die Voraussetzungen für den Betrieb
Um Zonos TTS lokal zu betreiben, sind einige grundlegende Systemanforderungen zu erfüllen. Die Installation wird durch den Einsatz von Docker erheblich vereinfacht, da alle Abhängigkeiten in einem Container gekapselt sind.
Hardware-Anforderungen:
- GPU: Für eine optimale und schnelle Verarbeitung wird eine NVIDIA-Grafikkarte mit mindestens 6 GB VRAM empfohlen. Der Betrieb ist zwar auch auf einer CPU möglich, jedoch deutlich langsamer und für interaktive Anwendungen weniger geeignet.
- Arbeitsspeicher (RAM): Es sollten mindestens 16 GB RAM zur Verfügung stehen.
- Speicherplatz: Es wird ausreichend Speicherplatz für das Docker-Image und die heruntergeladenen Sprachmodelle benötigt. Das Basismodell allein ist bereits mehrere Gigabyte groß.
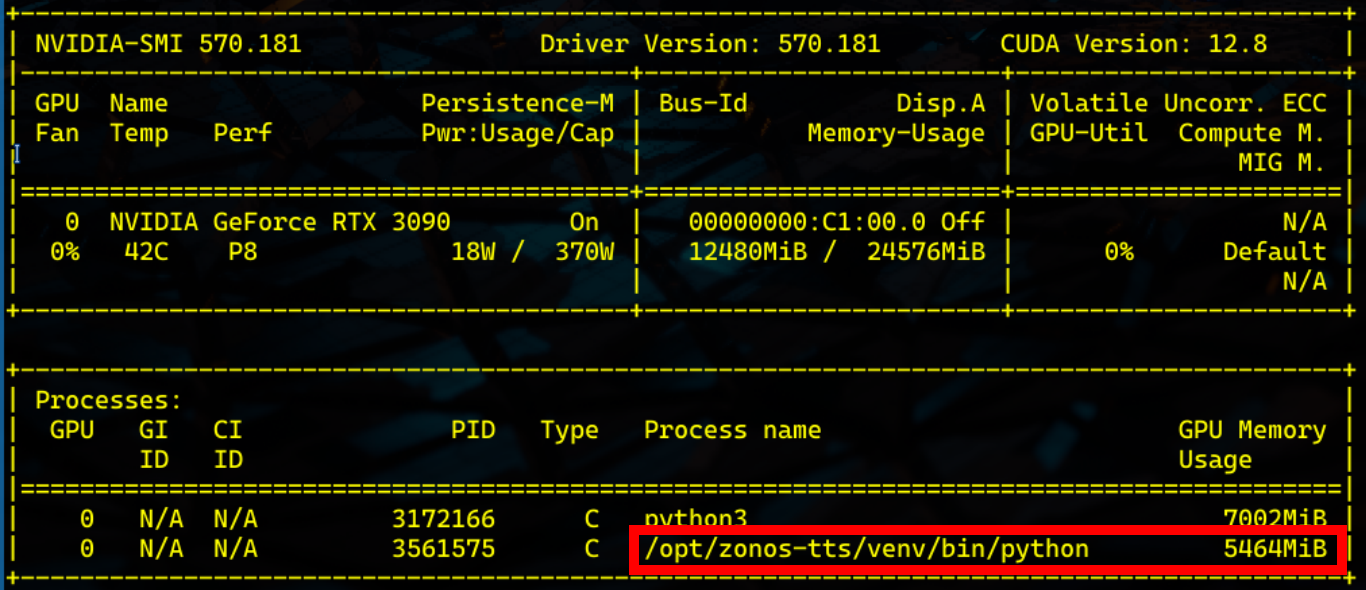
Auf meinem Homelab-Server nutzte zonos-tts unter 6GB, was jedoch im Betrieb stark schwankt.
Software-Anforderungen:
- Ein lauffähiges Linux-System wird empfohlen.
- Docker und Docker Compose müssen installiert sein. Dies ist die bevorzugte Methode für eine einfache Bereitstellung.
Installation und Konfiguration mittels Docker
Die Installation von Zonos TTS erfolgt am einfachsten über Docker Compose. Hierzu wird eine docker-compose.yml-Datei erstellt, die den Dienst konfiguriert und startet.
Zuerst wird das offizielle Git-Repository geklont, um an die notwendigen Konfigurationsdateien zu gelangen:
git clone https://github.com/Zyphra/Zonos.git
cd Zonos
Innerhalb dieses Verzeichnisses befindet sich bereits eine docker-compose.yml, die für den Start des Gradio-Webinterfaces vorgesehen ist. Diese Webschnittstelle ist ideal für erste Tests und zur Demonstration der Fähigkeiten, inklusive des Voice-Clonings.
Die docker-compose.yml sieht typischerweise wie folgt aus:
services:
zonos:
build:
context: .
dockerfile: Dockerfile
network_mode: "host" # Ermöglicht einfachen Zugriff, unter Windows "ports: - 7860:7860" verwenden
runtime: nvidia # Diese Zeile für NVIDIA-GPUs verwenden, ansonsten entfernen. [9]
ipc: host
ulimits:
memlock: -1
stack: 67108864
volumes:
- .:/Zonos/
Wichtige Hinweise zur Konfiguration:
- GPU-Nutzung: Der Eintrag
runtime: nvidiaist für die Nutzung der GPU essenziell. Sollte es hierbei zu Fehlern kommen oder keine NVIDIA-GPU vorhanden sein, kann diese Zeile entfernt werden. - Netzwerk:
network_mode: "host"funktioniert auf Linux-Systemen reibungslos. Auf Windows oder macOS sollte stattdessen eine Port-Zuweisung wieports: - "7860:7860"verwendet werden. - Daten-Download: Beim ersten Start lädt der Container das Sprachmodell herunter, was je nach Internetverbindung einige Zeit in Anspruch nehmen kann (ca. 3.6 GB).
Der Dienst wird mit folgendem Befehl im Zonos-Verzeichnis gestartet:
docker compose up -d
Nachdem der Download und der Startvorgang abgeschlossen sind, ist die Weboberfläche von Zonos TTS über http://localhost:7860 im Browser erreichbar.
Der erste Test: Funktioniert die Sprachausgabe?
Die einfachste Methode für einen ersten Test ist die Nutzung der eben gestarteten Gradio-Weboberfläche. Hier kann Text direkt in ein Feld eingegeben, eine Referenz-Audiodatei für das Klonen einer Stimme hochgeladen und verschiedene Parameter wie Sprechgeschwindigkeit oder Emotionen angepasst werden. Ein Klick auf "Generate" erzeugt die Audiodatei, die anschließend abgespielt oder heruntergeladen werden kann.
Für eine programmatische Nutzung, beispielsweise in Automatisierungsskripten, bietet Zonos eine API. Und nach einem ersten Versuch ist bereits mit den Werkseinstellungen ein brauchbares Ergebnis entstanden:
Eigene Sprache
Auch dieses Mal habe ich wieder schnell am Laptop ins Mikrofon gesprochen, da mein Homelab strikt von meinem Tonstudio getrennt ist. Erstaunlich ist, wie wenig Material ausreicht, um bereits eine deutliche Ähnlichkeit zur eigenen Stimme zu erzeugen.
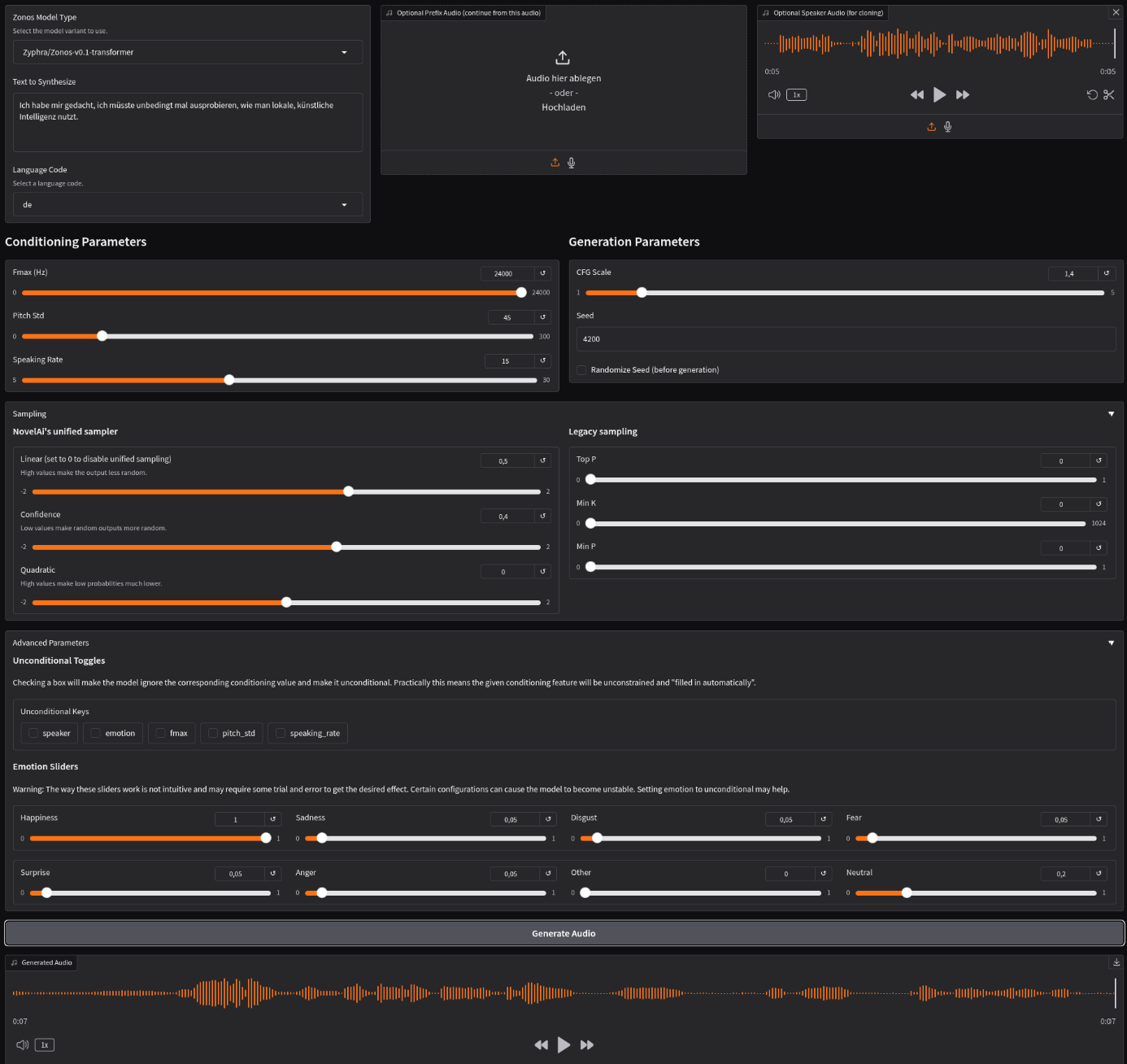
Folgendes habe ich eingesprochen:
Dann habe ich möglichst den gleichen Text generieren lassen, um einen Vergleich zu haben:
Mit nur einem Satz klingt das Ergebnis bereits besser als das Original.
Anwendungsgebiete
Vielleicht erinnern sich noch einige an meinen Signalbot.

Da ich gelegentlich Sprachnachrichten erhalte, kann ich diese nun von meiner lokalen KI abhören lassen und mit Zonos sogar direkt eine Antwort zurückschicken. Dafür muss ich jedoch zunächst eine bessere Audiodatei als Referenz hinterlegen.
Erstellen von Podcasts mit realen Stimmen
Ich habe bereits darüber berichtet, wie ich meine Podcasts erstelle. Allerdings sind die Texte in der Regel deutlich länger, als es die Obergrenze von Zonos zulässt.

Daher mache ich dabei folgendes:
- Das Skript liest zum Beispiel "Sara: Hallo Matthias! Willkommen bei Selfhosted-Tech! Ich freue mich sehr, dass du heute hier bist."
- Es erkennt den Sprecher "Sara".
- Es teilt den Text in drei Sätze auf:
- "Hallo Matthias!"
- "Willkommen bei Selfhosted-Tech!"
- "Ich freue mich sehr, dass du heute hier bist."
- Es ruft dreimal die Zonos-API mit sara.wav als Referenz auf, einmal für jeden dieser Sätze.
- Das gleiche Verfahren wird für die Zeilen von Matthias wiederholt.
- Am Ende werden alle kleinen Satz-Audiodateien in der richtigen Reihenfolge zu mein_podcast_final.mp3 zusammengefügt.
Das verantwortliche Script dazu sieht folgendermaßen aus:
# ==============================================================================
#
# Funktion: generate_podcast_from_transcript
#
# by Michael Meister
#
# Wandelt ein Dialog-Transkript in eine MP3-Audiodatei um, indem es jeden
# einzelnen Satz separat mit einer lokalen Zonos-Instanz umwandelt.
# Die korrekte Referenz-Stimme wird für jeden Satz beibehalten.
#
# Verwendung:
# generate_podcast_from_transcript "$podcast_transcript" "podcast_output.mp3"
#
# Parameter:
# $1: Eine Variable, die das Transkript enthält.
# $2: Der gewünschte Dateiname für die finale MP3-Ausgabe.
#
# ==============================================================================
generate_podcast_from_transcript() {
# --- VALIDIERUNG UND KONFIGURATION ---
if ! command -v curl &> /dev/null || ! command -v jq &> /dev/null || ! command -v ffmpeg &> /dev/null; then
echo "Fehler: Die benötigten Tools (curl, jq, ffmpeg) sind nicht installiert." >&2
return 1
fi
local transcript="$1"
local output_mp3="$2"
if [[ -z "$transcript" ]] || [[ -z "$output_mp3" ]]; then
echo "Fehler: Transkript und Ausgabedateiname müssen angegeben werden." >&2
return 1
fi
local zonos_url="http://aiav:7860"
local ref_sara="sara.wav"
local ref_matthias="matthias.wav"
if [[ ! -f "$ref_sara" ]] || [[ ! -f "$ref_matthias" ]]; then
echo "Fehler: Eine oder beide Referenzdateien ($ref_sara, $ref_matthias) nicht gefunden." >&2
return 1
fi
local temp_dir
temp_dir=$(mktemp -d)
trap 'rm -rf -- "$temp_dir"' EXIT
local concat_list_file="$temp_dir/concat_list.txt"
local sentence_counter=0
# --- HELFERFUNKTION ZUR VERARBEITUNG EINES EINZELNEN SATZES ---
process_sentence() {
local speaker="$1"
local sentence_text="$2"
# Überspringe leere oder nur aus Leerzeichen bestehende Sätze
if [[ -z "${sentence_text// }" ]]; then
return
fi
((sentence_counter++))
echo "Verarbeite Satz $sentence_counter für '$speaker': \"$sentence_text\""
local current_ref_file=""
if [[ "$speaker" == "Sara" ]]; then
current_ref_file="$ref_sara"
elif [[ "$speaker" == "Matthias" ]]; then
current_ref_file="$ref_matthias"
else
echo "Warnung: Unbekannter Sprecher '$speaker'. Überspringe."
return
fi
# 1. Referenz-Audio hochladen
local upload_response temp_ref_path
upload_response=$(curl -s -X POST -F files=@"$current_ref_file" "$zonos_url/upload")
temp_ref_path=$(echo "$upload_response" | jq -r '.[0]')
if [[ -z "$temp_ref_path" || "$temp_ref_path" == "null" ]]; then
echo "Fehler beim Hochladen der Referenzdatei für Satz $sentence_counter." >&2
return
fi
# 2. TTS-Anfrage senden
local predict_payload
predict_payload=$(jq -n --arg text "$sentence_text" --arg ref_path "$temp_ref_path" '{
"fn_index": 0, "data": [ $text, null, { "name": $ref_path, "data": null, "is_file": true }, "de", null, false, 1, 0, 1, 0.5, null, null ]
}')
local predict_response generated_file_info generated_file_path
predict_response=$(curl -s -X POST -H "Content-Type: application/json" -d "$predict_payload" "$zonos_url/api/predict/")
# 3. Generierte Audiodatei herunterladen
generated_file_info=$(echo "$predict_response" | jq -r '.data[0]')
generated_file_path=$(echo "$generated_file_info" | jq -r '.name')
if [[ -z "$generated_file_path" || "$generated_file_path" == "null" ]]; then
echo "Fehler beim Generieren des Audios für Satz $sentence_counter." >&2
return
fi
local output_wav="$temp_dir/sentence_${sentence_counter}.wav"
curl -s -o "$output_wav" "$zonos_url/file=$generated_file_path"
echo "file '$output_wav'" >> "$concat_list_file"
}
# --- HAUPTLOGIK: TRANSKRIPT PARSEN UND IN SÄTZE AUFTEILEN ---
local current_speaker=""
while IFS= read -r line; do
if [[ -z "$line" ]]; then continue; fi
local dialog_text=""
# Überprüfen, ob die Zeile einen neuen Sprecher definiert
if [[ "$line" =~ ^([^:]+):[[:space:]]*(.*)$ ]]; then
current_speaker="${BASH_REMATCH[1]}"
dialog_text="${BASH_REMATCH[2]}"
else
# Andernfalls ist es eine Fortsetzungszeile für den aktuellen Sprecher
dialog_text="$line"
fi
if [[ -z "$current_speaker" ]]; then
echo "Warnung: Zeile ohne definierten Sprecher gefunden. Überspringe: '$line'"
continue
fi
# Zerlege den Dialogtext der Zeile in Sätze und verarbeite jeden einzeln.
# Ersetzt Satzzeichen (. ! ?) durch sich selbst plus einen Zeilenumbruch.
# Dies ermöglicht es, die Sätze mit einer einfachen 'while read'-Schleife zu lesen.
echo -n "$dialog_text" | sed -E 's/([.!?]) ?/\1\n/g' | while IFS= read -r sentence; do
process_sentence "$current_speaker" "$sentence"
done
done <<< "$transcript"
# --- ZUSAMMENFÜGEN UND KONVERTIEREN ---
if [[ ! -f "$concat_list_file" ]] || [[ ! -s "$concat_list_file" ]]; then
echo "Fehler: Keine Audiodateien zum Zusammenfügen erstellt. Überprüfen Sie das Transkript." >&2
return 1
fi
echo "Füge Sätze zusammen und konvertiere direkt zu MP3: $output_mp3"
ffmpeg -f concat -safe 0 -i "$concat_list_file" -acodec libmp3lame -q:a 2 "$output_mp3" -loglevel error
echo "Fertig! Die Datei wurde unter '$output_mp3' gespeichert."
}Ethische Bedenken
Wie bei allen zuvor vorgestellten Sprachkloning-Tools gilt auch hier: Jedes Werkzeug lässt sich sowohl zum Guten als auch zum Schlechten einsetzen. Ob Axt oder TTS-Modell – man kann damit einen Podcast aufnehmen oder die Stimme des Vorgesetzten seines Vorgesetzten klonen, um seinen Chef in eine bestimmte Richtung zu beeinflussen.

Gerade die Möglichkeit, der geklonten Stimme Emotionen mitgeben zu können, erweitert die Anwendungsgebiete.
Fazit
Mit Zonos TTS lässt sich ein extrem leistungsfähiges und recht natürlich klingendes Text-to-Speech-System auf der eigenen Hardware betreiben. Die Installation mittels Docker ist auch für weniger erfahrene Anwender gut zu bewältigen und bietet eine enorme Aufwertung für jedes Smart Home oder andere Projekte, die eine hochwertige Sprachausgabe erfordern. Die Möglichkeit des Voice-Clonings und die feingranulare Steuerung der Ausgabe machen Zonos zu einer beeindruckenden, quelloffenen Alternative zu kommerziellen Cloud-Diensten.