Lokale-KI in der Shell
Der 'Ollama Split-Shell Companion' revolutioniert die Kommandozeile


Die Integration von Künstlicher Intelligenz in den Arbeitsalltag technischer Experten hat sich in den letzten Jahren rasant entwickelt. Während viele Tools primär auf den Austausch von Textinformationen setzen, entsteht ein wachsender Bedarf an tiefergehenden, interaktiven Lösungen.
Über gemini-cli hatte ich bereits berichtet, und meine Enttäuschung darüber, dass Gemini nicht auf Remote-Servern arbeiten möchte.

Das führte zum Start eines eigenen kleinen Projektes.
Der folgende Artikel beleuchtet, wie mein speziell entwickeltes Python-Skript weit über herkömmliche CLI-LLM-Clients hinausgeht und eine nahtlose, interaktive Arbeitsumgebung schafft, die Effizienz und Produktivität neu definiert.
gemini-cli und die Grenzen des reinen Text-Chats
Standardisierte Kommandozeilen-Schnittstellen (CLI) für Large Language Models (LLMs), wie beispielsweise gemini-cli, konzentrieren sich primär auf die textbasierte Interaktion. Ein Benutzer stellt eine Frage oder gibt einen Befehl in Textform ein, und die KI antwortet ebenfalls in Textform. Dies ist zweifellos nützlich für die Informationsbeschaffung, das Generieren von Code-Snippets oder die Ideenfindung.
Jedoch stoßen diese Ansätze schnell an ihre Grenzen, sobald die Aufgaben komplexer und interaktiver werden.
Der Ollama Split-Shell Companion: Eine integrierte Arbeitsumgebung
Hier setzt das vorliegende Python-Skript, der Ollama Split-Shell Companion, an und bietet eine radikal andere Herangehensweise. Es ist nicht einfach nur ein weiterer Text-Chatbot, sondern eine vollwertige, interaktive Arbeitsumgebung. Das Skript kombiniert die Intelligenz eines lokalen LLMs (Ollama) mit einem voll funktionsfähigen Pseudo-Terminal (PTY) in einem ansprechenden Text User Interface (TUI). Diese Integration ermöglicht eine direkte Kommunikation zwischen der KI und der Shell-Umgebung, wodurch vorgeschlagene Befehle nicht nur visualisiert, sondern nach Bestätigung auch direkt ausgeführt werden können.
Der sichtbare Unterschied: TUI und Split-Screen-Ansicht
Einer der offensichtlichsten Vorteile des Ollama Split-Shell Companion gegenüber rein textbasierten CLI-Tools ist die Benutzeroberfläche.
Statt einer simplen Eingabezeile in einem Standard-Terminal bietet das Skript eine zweigeteilte Ansicht, realisiert mit dem Python-Framework Textual:
- Chat-Ansicht: Im oberen Bereich findet die gesamte Kommunikation mit der KI statt. Fragen des Benutzers und Antworten des LLMs werden übersichtlich dargestellt, inklusive Syntax-Highlighting für Code-Blöcke.
- Konsolen-Ansicht: Der untere Bereich beherbergt ein echtes Pseudo-Terminal, in dem Shell-Befehle ausgeführt und deren Ausgaben live verfolgt werden können.
Im unteren Fenster kann ich mich so auf einem anderen System einloggen und die KI dort weiterarbeiten lassen, um mich z.B. bei der Hardwarekonfiguration in einem LXC-Container zu unterstützen. Das könnte aber auch eine Fortigate-Firewall oder ein Cisco-Router sein, auf dem es ein Konfigurationsproblem zu lösen gibt.
Diese Split-Screen-Architektur eliminiert den Bedarf an separaten Terminalfenstern und dem ständigen Wechsel zwischen diesen. Der Benutzer hat Chat und Konsole stets im Blick, was den Kontextwechsel minimiert und die Konzentration auf die eigentliche Aufgabe fördert. Die visuellen Hinweise, wie zum Beispiel farbige Statusmeldungen oder die hervorgehobene Darstellung von Befehlen, tragen maßgeblich zur Benutzerfreundlichkeit bei.
Ein vereinfachter Blick auf die Textual-Struktur des Skripts zeigt die grundlegende Aufteilung:
# M. Meister
from textual.app import App, ComposeResult
from textual.containers import Vertical
from textual.widgets import Header, Footer
# ... (Definition von ChatView und ConsoleView) ...
class AICompanionApp(App):
# ... (weitere Initialisierungen) ...
def compose(self) -> ComposeResult:
"""Erstellt das Layout der App und fügt die Kind-Widgets hinzu."""
yield Header()
yield ChatView() # Der obere Bereich für den Chat
yield ConsoleView() # Der untere Bereich für die Shell
yield Footer()
# ... (Rest der App-Logik) ...Souveränität und Flexibilität: Ollama als lokaler KI-Motor
Ein weiterer entscheidender Unterschied liegt in der Wahl des KI-Backends. Während gemini-cli naturgemäß auf Google Gemini (einen Cloud-Dienst) angewiesen ist, setzt mein Ollama Split-Shell Companion auf Ollama. Ollama ermöglicht es, eine Vielzahl von Large Language Models – in diesem Fall das qwen3-coder:latest – lokal auf eigener Hardware zu betreiben.
Die Vorteile dieser Architektur sind vielfältig:
- Datenschutz: Sensible Befehle, Systemkonfigurationen oder Code-Ausschnitte verlassen niemals die eigene Infrastruktur. Dies ist in sicherheitskritischen Umgebungen von unschätzbarem Wert.
- Offline-Fähigkeit: Sobald das Modell heruntergeladen ist, funktioniert der Companion auch ohne aktive Internetverbindung. Ideal für Arbeiten in isolierten Umgebungen oder unterwegs.
- Kontrolle und Anpassbarkeit: Die Wahl des LLMs liegt beim Benutzer. Es können spezialisierte Modelle (wie
qwen3-coderfür Programmieraufgaben) eingesetzt oder sogar eigene, feinabgestimmte Modelle verwendet werden. - Kostenkontrolle: Keine nutzungsbasierten Kosten, da die Rechenleistung lokal erbracht wird.
Im Skript wird der Ollama-Dienst über http://ai:11434 angesprochen. Eine solche lokale Installation lässt sich beispielsweise mit einem einfachen ollama run qwen3-coder starten, nachdem Ollama gemäß der offiziellen Dokumentation auf dem System eingerichtet wurde.
Revolutionäre Interaktion: Befehlsausführung im Pseudo-Terminal (PTY)
Das eigentliche Herzstück und Alleinstellungsmerkmal des Skripts ist die direkte, interaktive Ausführung von KI-generierten Befehlen in einem Pseudo-Terminal (PTY). Ein PTY kann man sich wie einen “virtuellen Telefonisten” vorstellen, der eine normale Shell-Sitzung in einem Programm kapselt. Statt dass das Programm die Shell direkt aufruft und auf das Ende der Ausführung wartet, interagiert es mit dem PTY so, als wäre es ein Benutzer, der an einem echten Terminal tippt. Die Kommunikation erfolgt also über STDIN/STDOUT und STDERR. Dies ermöglicht:
- Live-Interaktion: Befehle können ausgeführt und deren Ausgaben in Echtzeit erfasst werden.
- Fortlaufende Sitzungen: Ein Prozess kann im PTY laufen, während das Python-Skript weiterhin aktiv ist und mit der KI kommuniziert.
Das Skript ist intelligent genug, um Code-Blöcke (eingefasst in bash oder sh) in den Antworten der KI zu identifizieren. Der hierfür verwendete reguläre Ausdruck (re.findall) extrahiert den Inhalt dieser Blöcke:
# M. Meister
import re
# ...
def parse_and_handle_commands(self, text: str):
# Sucht nach Bash- oder Shell-Code-Blöcken im KI-Text
commands = re.findall(r"```(?:bash|sh)?\n(.*?)\n```", text, re.DOTALL)
if not commands:
return False
self.pending_command = commands[0].strip()
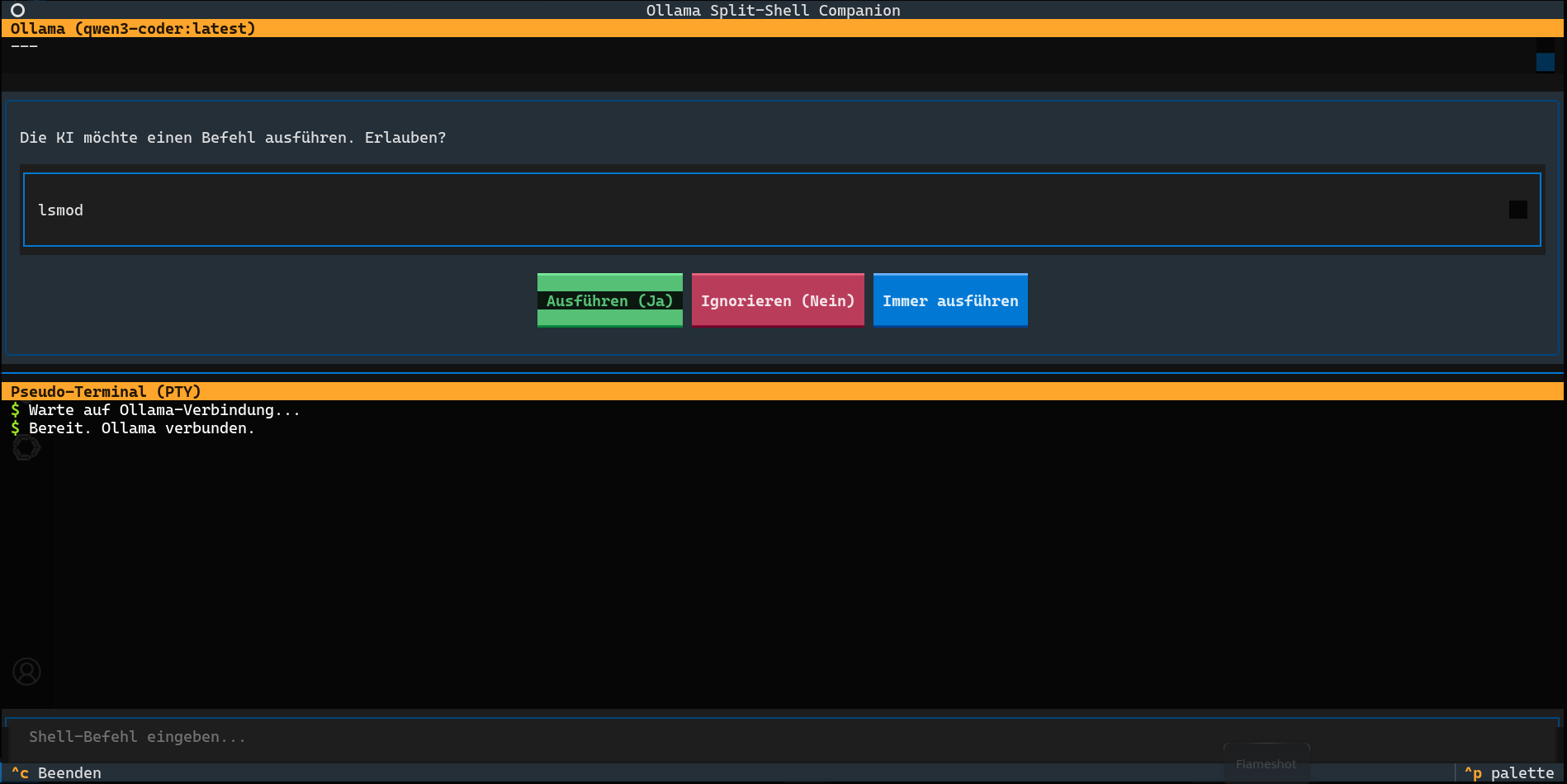
# ... (weiterer Code für die Freigabe) ...Wird ein solcher Befehl erkannt, bietet das Skript eine interaktive Freigabeaufforderung (PermissionPrompt) an. Dies ist ein entscheidender Sicherheitsmechanismus: Die KI kann nicht einfach Befehle ausführen, ohne dass der Benutzer explizit zustimmt. Es gibt drei Optionen:
- Ausführen (Ja): Der vorgeschlagene Befehl wird einmalig im PTY ausgeführt.
- Ignorieren (Nein): Der Befehl wird verworfen.
- Immer ausführen: Der Befehl wird ausgeführt, und alle zukünftigen Befehle werden ebenfalls ohne weitere Nachfrage ausgeführt (bis zum Neustart der App oder manueller Änderung des Modus). Diese Option bietet maximale Effizienz für vertrauenswürdige Workflows.
Beispiel eines typischen Ablaufs:
- Ein Benutzer fragt die KI: “Wie kann ich die Prozesse mit dem höchsten Speicherverbrauch finden?”
- Die KI antwortet mit einer Erklärung und schlägt den Befehl
ps aux --sort=-%mem | head -n 5vor. - Im Chat-Fenster erscheint ein
PermissionPrompt, das den vorgeschlagenen Befehl anzeigt und zur Bestätigung auffordert. - Der Benutzer wählt “Ausführen (Ja)”.
- Der Befehl wird im PTY im unteren Konsolen-Fenster ausgeführt.
- Die Ausgabe des Befehls erscheint live in der Konsole, die von der KI mitgelesen wird.
Dies überbrückt die Lücke zwischen Empfehlung und Aktion auf eine Weise, die mit reinen Text-Chatbots unmöglich ist.
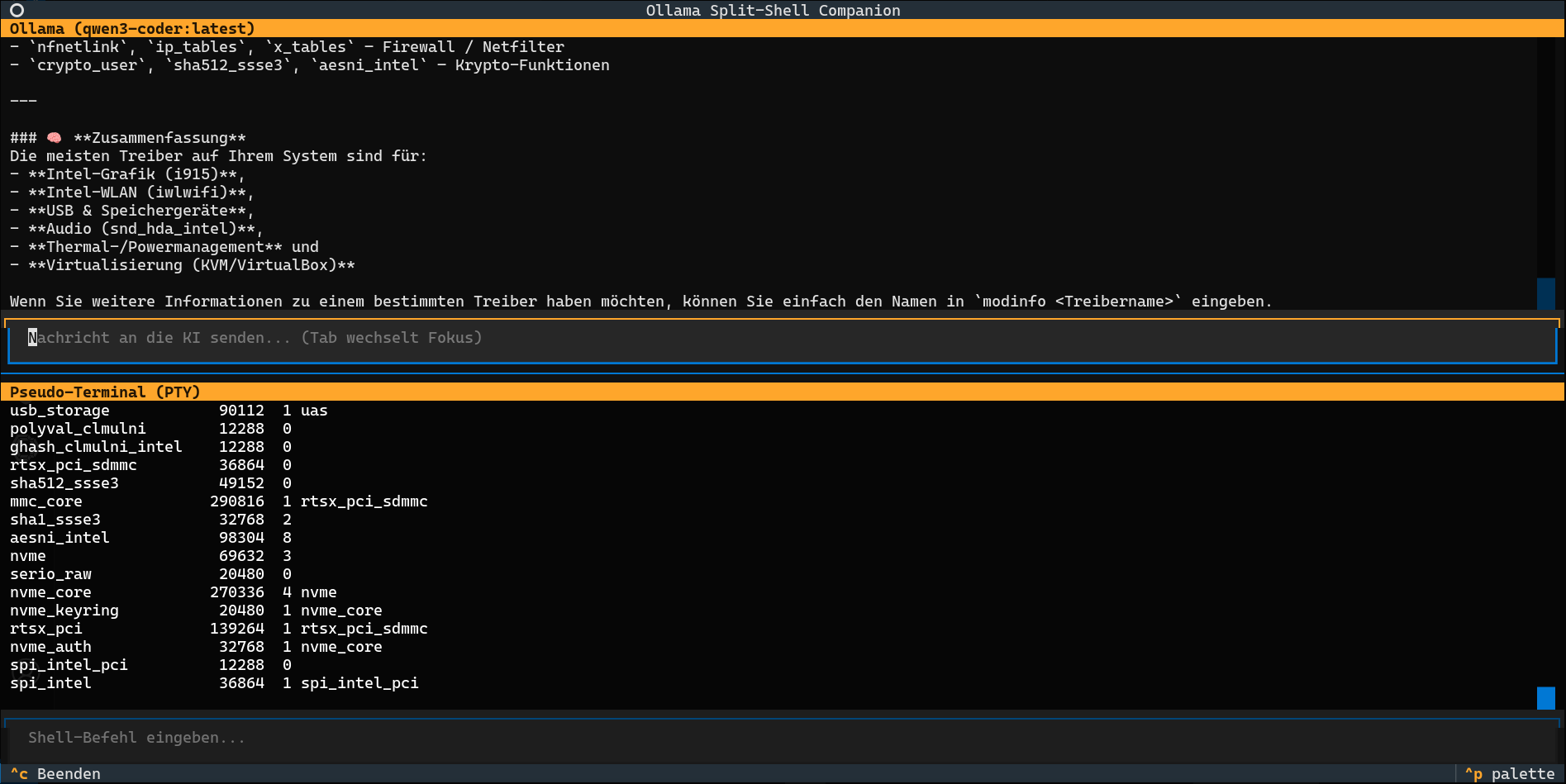
Intelligente Kontextualisierung: Die KI lernt aus der Shell-Ausgabe
Der Ollama Split-Shell Companion geht noch einen Schritt weiter: Die gesamte Ausgabe des Pseudo-Terminals wird kontinuierlich in einem Puffer (self.console_context_buffer) gesammelt. Bevor eine neue Anfrage an die KI gesendet wird, wird dieser Konsolen-Output als zusätzlicher Kontext in den Chat-Verlauf aufgenommen.
Das bedeutet, dass die KI nicht nur “blind” Befehle vorschlägt, sondern auch deren Ergebnisse aktiv wahrnimmt und in ihre weiteren Überlegungen einbezieht. Stellt die KI beispielsweise einen Befehl zur Fehlerbehebung bereit und dieser schlägt fehl oder liefert unerwartete Ausgaben, kann der Benutzer einfach nachfragen: “Der letzte Befehl hat nicht funktioniert. Was könnte die Ursache sein?” Die KI hat dann den fehlerhaften Output bereits als Kontext vorliegen und kann fundiertere Folgevorschläge machen oder falls man der KI erlaubt hat, immer Befehle auszuführen, bis zum Erfolg weiterzuarbeiten.
Diese Fähigkeit zur iterativen Problembehandlung und intelligenten Beobachtung der Shell-Interaktion macht das Skript zu einem äußerst mächtigen Assistenten für Debugging, Systemadministration und explorative Entwicklung. Man könnte sagen, die KI erhält damit eine rudimentäre Form des “Sehens und Handelns” im System.
Praktischer Nutzen: Anwendungsfälle und unschlagbare Vorteile
Die Kombination aus TUI, lokaler LLM-Integration und interaktiver PTY-Steuerung resultiert in einer Reihe von unschlagbaren Vorteilen für technisch versierte Anwender:
- Höhere Produktivität: Reduzierung des Kontextwechsels und Eliminierung manueller Schritte beim Ausführen von Befehlen.
- Effizientes Debugging: KI-unterstützte Fehlersuche, bei der die KI die Ergebnisse ihrer eigenen Vorschläge analysiert.
- Schnelles Prototyping: Schnelle Iteration bei der Entwicklung von Skripten oder Konfigurationen.
- Lernunterstützung: Neue Befehle und Konzepte können direkt im Kontext ausprobiert und die Ergebnisse mit der KI diskutiert werden.
- Erhöhte Sicherheit: Die manuelle Freigabe vor der Ausführung bietet eine wichtige Kontrollinstanz.
- Datensouveränität: Sensible Informationen bleiben auf dem eigenen System.
Fazit
Mein Prototyp Ollama Split-Shell Companion stellt für mich einen signifikanten Fortschritt in der Interaktion mit Large Language Models im technischen Bereich dar. Er überwindet die passiven Grenzen reiner Text-Chats durch eine intelligente Integration von TUI, einem lokalen KI-Backend und einem interaktiven Pseudo-Terminal. Dieses Tool transformiert die KI von einem bloßen Ratgeber zu einem aktiven, sicheren und hochproduktiven Kollaborationspartner direkt in der Kommandozeile, was die Effizienz in Entwicklung und Systemadministration nachhaltig steigert - auch auf Remote-Systemen.