Linux Namespaces: Das Geheimnis hinter der Container-Sicherheit
Verstehen, warum Container keine VMs sind und welche Linux-Kernel-Technologien die Grundlage ihrer Isolation bilden.

Die moderne IT-Landschaft ist ohne Container kaum vorstellbar. Sie sind das Rückgrat zahlreicher Anwendungen, von kleinen Webdiensten bis hin zu komplexen Microservice-Architekturen. Doch was verbirgt sich wirklich hinter der scheinbar magischen Isolation eines Docker-Containers? Dieser Artikel beleuchtet die tiefgreifenden Mechanismen des Linux-Kernels, die Container erst ermöglichen, und klärt das Missverständnis auf, Container seien lediglich schlankere virtuelle Maschinen.

Die trügerische Isolation: Erste Indizien
Betrachtet man einen Container von außen und von innen, fallen schnell interessante Ungereimtheiten auf. Innerhalb eines Containers kann man beispielsweise als Benutzer michael mit der User-ID 1000 agieren. Erstellt man nun eine Datei, gehört sie diesem Benutzer. Blickt man jedoch vom Host-System auf dasselbe geteilte Verzeichnis, gehört die Datei möglicherweise einem anderen Benutzer, etwa user, obwohl auch dieser die User-ID 1000 besitzt. Hier zeigt sich eine erste Illusion: Gleiche User-ID, aber unterschiedliche Namen. Dies liegt daran, dass der angezeigte Benutzername aus der /etc/passwd des jeweiligen Kontexts gelesen wird, während die eigentliche User-ID dieselbe sein kann.
Noch deutlicher wird die Diskrepanz bei der Prozessverwaltung. Führt man im Container ein Tool wie watch ps ax aus, wird man den watch-Prozess selbst sowie weitere container-spezifische Prozesse wie ynetd (ein beispielhafter Dienst in einem Challenge-Container) mit niedrigen Prozess-IDs (PIDs) sehen – typischerweise beginnend bei PID 1.
# Innerhalb des Containers
michael@container:/$ watch -n 2 ps ax
Every 2.0s: ps ax container: Wed Oct 26 13:37:00 2023
PID TTY STAT TIME COMMAND
1 ? Ss 0:00 /sbin/init
78 ? S 0:00 ynetd
79 ? R 0:00 watch -n 2 ps ax
80 ? R 0:00 ps axGleichzeitig wird vom Host-System aus eine viel größere Anzahl von Prozessen sichtbar sein. Sucht man hier nach dem eben gestarteten watch-Prozess, wird er überraschenderweise gefunden – jedoch mit einer völlig anderen, viel höheren PID:
# Auf dem Host-System
user@host:~$ ps ax | grep "watch -n 2 ps ax"
12675 ? Sl 0:00 watch -n 2 ps axDieser Umstand ist der erste, unmissverständliche Beweis dafür, dass Docker-Container keine virtuellen Maschinen sind. Sie teilen sich den Kernel des Host-Systems, und ihre Prozesse sind letztlich nur reguläre Prozesse auf dem Host, die jedoch in einem isolierten Kontext laufen. Die scheinbare Isolation ist eine sorgfältig konstruierte Blase.
Um die Zusammenhänge noch klarer zu visualisieren, kann der Prozessbaum des Host-Systems mittels pstree untersucht werden. Ein watch-Prozess, der in einem Container gestartet wurde, ist dort nicht direkt als unabhängiger Prozessbaum unter PID 1 zu finden. Stattdessen verbirgt er sich als Kindprozess von containerd-shim, welches wiederum ein Kind von containerd ist, das vom initialen systemd (PID 1 auf dem Host) gestartet wurde.
# Auf dem Host-System (auszugsweise)
systemd───containerd───containerd-shim───bash───watchDies offenbart die Schichten der Container-Architektur und führt uns direkt zur Frage, wie diese “Blase” überhaupt erzeugt wird.
Das Docker-Ökosystem: Eine Schichtung der Verantwortlichkeiten
Bevor die eigentliche Magie des Linux-Kernels ergründet wird, ist es hilfreich, die Architektur von Docker zu verstehen. Wenn ein Befehl wie docker build oder docker run ausgeführt wird, interagiert das docker client-Tool nicht direkt mit dem Kernel. Stattdessen sendet es Befehle an den Docker-Daemon (dockerd). Dieser Daemon ist ein langlebiger Hintergrunddienst, der die Hauptlast der Container-Verwaltung trägt. Die Kommunikation zwischen Client und Daemon erfolgt über eine HTTP REST API oder einen UNIX-Socket.
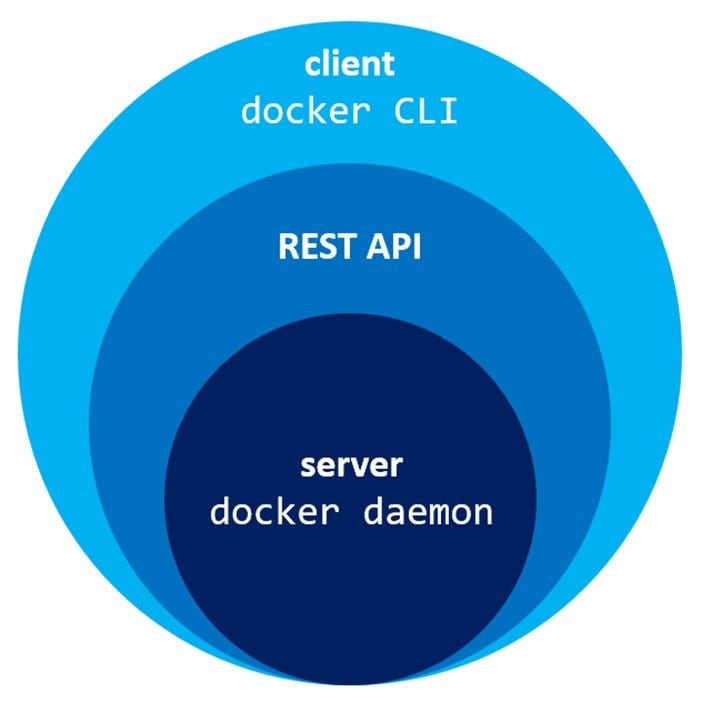
Der dockerd ist jedoch nicht das unterste Glied in der Kette. Standardmäßig startet der Docker-Daemon selbst eine weitere Komponente: containerd. containerd ist eine hochgradig spezialisierte Container-Runtime, die sich um den gesamten Lebenszyklus eines Containers kümmert: Bildtransfer und -speicherung, Container-Ausführung und -Überwachung. Dabei delegiert containerd die tatsächliche Erstellung und Ausführung eines Containers an noch tieferliegende Werkzeuge.
Für das Spawnen und Ausführen von Containern gemäß der Open Container Initiative (OCI) Spezifikation greift containerd auf runc zurück. runc ist im Grunde ein Kommandozeilen-Tool, das die direkte Schnittstelle zum Linux-Kernel darstellt, um Container zu starten. Diese gestaffelte Architektur bietet Vorteile in Bezug auf Standardisierung, Modularität und Trennung der Verantwortlichkeiten. Es ist ein elegantes Zusammenspiel, bei dem jeder Akteur eine klare Rolle hat, bevor die eigentliche Kernarbeit beginnt.
Der Blick unter die Haube
Um die tatsächliche Funktionsweise zu ergründen, muss man dem containerd-Prozess mit strace auf die Finger schauen. strace ist ein mächtiges Linux-Tool, das alle Systemaufrufe eines Prozesses und seiner Kinder verfolgt.
Zunächst muss die PID des containerd-Prozesses ermittelt werden:
# Auf dem Host-System
user@host:~$ pidof containerd
1234Danach kann strace gestartet werden, um die Systemaufrufe aufzuzeichnen:
# Auf dem Host-System
user@host:~$ sudo strace -f -o containerd_trace.log -p 1234Anschließend wird ein neuer Container gestartet:
# Auf dem Host-System, in einem neuen Terminal
user@host:~$ docker run -d --name new-container alpine/git sleep infinityNun kann die Logdatei containerd_trace.log analysiert werden. Eine Suche nach runc offenbart den ersten wichtigen Schritt: containerd führt das runc-Binary aus, oft über ein containerd-shim-Prozess. Doch der eigentliche Star der Show ist ein spezifischer Systemaufruf, der die Isolation initiiert: unshare().
Innerhalb des strace-Logs findet man Einträge, die prctl und unshare zeigen:
...
[pid 29865] prctl(PR_SET_NAME, "runc:[1:0-containerd-shim]", 0, 0, 0) = 0
[pid 29865] unshare(CLONE_NEWPID|CLONE_NEWNS|CLONE_NEWUTS|CLONE_NEWIPC|CLONE_NEWNET) = 0
...Der unshare()-Systemaufruf ist das Fundament der Container-Isolation. Er ermöglicht es einem Prozess, Teile seines Ausführungskontextes, die normalerweise mit anderen Prozessen geteilt werden, zu “entkoppeln”. Die übergebenen Flags, wie CLONE_NEWPID, CLONE_NEWNS oder CLONE_NEWNET, bestimmen, welche Bereiche isoliert werden sollen.
Besonders faszinierend ist CLONE_NEWPID. Dieses Flag bewirkt, dass der aufrufende Prozess einen neuen PID-Namespace für seine Kinder erhält. Das bedeutet, dass der erste Kindprozess, der in diesem neuen Namespace erzeugt wird, die Prozess-ID 1 erhält und die Rolle des init-Prozesses in diesem isolierten Kontext übernimmt – genau wie systemd auf dem Host.
Nach dem unshare()-Aufruf wird bald darauf ein weiterer wichtiger Systemaufruf sichtbar: clone(). clone() wird verwendet, um neue Child-Prozesse zu erstellen. Im Kontext eines neuen PID-Namespaces ist der Rückgabewert von clone() auf dem Host zwar die Host-PID des neuen Prozesses, innerhalb des Namespaces wird dieser Prozess jedoch als PID 1 wahrgenommen.
...
[pid 29865] clone(child_stack=0x7f..., flags=CLONE_NEWPID|CLONE_NEWNS|CLONE_NEWUTS|CLONE_NEWIPC|CLONE_NEWNET|SIGCHLD) = 29866
...Der Prozess mit PID 29866 auf dem Host ist nun der init-Prozess im neuen Container-Namespace (d.h., er sieht sich selbst als PID 1). Dieser Prozess wird dann oft seinen Namen in INIT ändern und weitere Kindprozesse starten, die ihrerseits PIDs ab 2 im Container-Namespace erhalten, während sie auf dem Host wiederum andere, hohe PIDs tragen. Es entstehen gewissermaßen zwei parallele Universen: Die Prozesse leben im Host-Universum, sehen sich aber innerhalb ihrer Blase als Teil eines eigenen, unabhängigen Systems.
Die vielfältige Welt der Namespaces: Mehr als nur PIDs
Neben dem PID-Namespace gibt es weitere essentielle Namespaces, die zur robusten Isolation von Containern beitragen:
CLONE_NEWNS(Mount Namespace): Dies isoliert die Liste der Einhängepunkte (Mount Points), die von Prozessen in einem Namespace gesehen werden. Das bedeutet, dass ein Container sein eigenes Dateisystem, seine eigenentmpfs-Bereiche und Pseudo-Dateisysteme wieprocfsbesitzt und Änderungen daran nicht das Host-Dateisystem beeinträchtigen. Ohne diese Isolation könnten Container auf kritische Host-Dateien zugreifen oder diese verändern.CLONE_NEWNET(Network Namespace): Dieser Namespace isoliert Netzwerk-Ressourcen. Jeder Container erhält einen eigenen Satz von Netzwerkgeräten, IP-Adressen, Routing-Tabellen und Port-Bindungen. Dadurch kann ein Container sein eigenes Netzwerk konfigurieren, ohne mit dem Host-Netzwerk oder anderen Containern in Konflikt zu geraten.
Weitere Namespaces umfassen:
CLONE_NEWUTS(UTS Namespace): Isoliert den Hostnamen und die NIS-Domänennamen.CLONE_NEWIPC(IPC Namespace): Isoliert Inter-Prozess-Kommunikationsressourcen wie System-V-Semaphoren und POSIX-Message-Queues.CLONE_NEWCGROUP(Cgroup Namespace): Isoliert die Control Group-Hierarchie.
Ergänzend zu den Namespaces sind Control Groups (cgroups) ein weiterer entscheidender Mechanismus des Linux-Kernels, der Container-Ressourcenmanagement ermöglicht. Während Namespaces die Sichtbarkeit und Isolation von Ressourcen regeln, steuern cgroups die Verfügbarkeit von Ressourcen. Mit cgroups kann festgelegt werden, wie viel CPU-Zeit, Arbeitsspeicher, Netzwerkbandbreite oder I/O-Leistung einem Container maximal zugewiesen wird. Zusammen bilden Namespaces und cgroups das Fundament der Container-Isolation und -Ressourcenkontrolle.
User Namespaces: Die Wurzel der Privilegien-Illusion
Ein besonders mächtiger und oft missverstandener Namespace ist der User Namespace (CLONE_NEWUSER). Er ermöglicht es, User- und Group-IDs innerhalb eines Namespaces anders abzubilden als auf dem Host-System. Das bedeutet, ein Prozess kann innerhalb des Containers die User-ID 0 (Root) besitzen, während er auf dem Host tatsächlich einem unprivilegierten Benutzer (z.B. User-ID 1000) zugeordnet ist.
Dies ist eine elegante Sicherheitsfunktion: Ein Angreifer, der aus dem Container ausbricht, landet auf dem Host als unprivilegierter Benutzer, anstatt direkt Root-Rechte zu erlangen. Im eingangs beschriebenen Beispiel, bei dem die User-IDs innerhalb und außerhalb des Containers identisch waren (1000), wurde offensichtlich kein User Namespace verwendet. Die Diskrepanz in den angezeigten Benutzernamen resultierte lediglich aus unterschiedlichen /etc/passwd-Dateien, die die numerische User-ID einem alphanumerischen Namen zuordnen. Die tatsächliche Berechtigungsebene blieb die gleiche.
Ein Exkurs ins procfs
Die Existenz und Isolation von Namespaces lässt sich im procfs (dem Pseudo-Dateisystem unter /proc) nachvollziehen. Für jeden Prozess existiert dort ein Verzeichnis /proc/<PID>/ns/, das Symlinks zu den verschiedenen Namespaces enthält, in denen der Prozess läuft. Jeder Symlink zeigt auf eine eindeutige Inode-Nummer, die den jeweiligen Namespace identifiziert.
Nehmen wir an, der watch-Prozess im Container hat auf dem Host die PID 12675. Die Namespace-Dateien können dann so aussehen:
# Auf dem Host-System
user@host:~$ ls -l /proc/12675/ns/
total 0
lrwxrwxrwx 1 user user 0 Oct 26 13:45 ipc:[4026531839]
lrwxrwxrwx 1 user user 0 Oct 26 13:45 mnt:[4026532009] <───
lrwxrwxrwx 1 user user 0 Oct 26 13:45 net:[4026532010] <───
lrwxrwxrwx 1 user user 0 Oct 26 13:45 pid:[4026532011] <───
lrwxrwxrwx 1 user user 0 Oct 26 13:45 user:[4026531837]
lrwxrwxrwx 1 user user 0 Oct 26 13:45 uts:[4026532008]Vergleicht man dies mit den Namespaces des Host-systemd (PID 1) oder einer normalen Shell-Sitzung ($$ repräsentiert die PID der aktuellen Shell):
# Auf dem Host-System
user@host:~$ ls -l /proc/1/ns/ # systemd
total 0
lrwxrwxrwx 1 root root 0 Oct 26 13:45 ipc:[4026531839]
lrwxrwxrwx 1 root root 0 Oct 26 13:45 mnt:[4026531840] <───
lrwxrwxrwx 1 root root 0 Oct 26 13:45 net:[4026531956] <───
lrwxrwxrwx 1 root root 0 Oct 26 13:45 pid:[4026531836] <───
lrwxrwxrwx 1 root root 0 Oct 26 13:45 user:[4026531837]
lrwxrwxrwx 1 root root 0 Oct 26 13:45 uts:[4026531838]
user@host:~$ ls -l /proc/$$/ns/ # Aktuelle Shell
total 0
lrwxrwxrwx 1 user user 0 Oct 26 13:45 ipc:[4026531839]
lrwxrwxrwx 1 user user 0 Oct 26 13:45 mnt:[4026531840] <───
lrwxrwxrwx 1 user user 0 Oct 26 13:45 net:[4026531956] <───
lrwxrwxrwx 1 user user 0 Oct 26 13:45 pid:[4026531836] <───
lrwxrwxrwx 1 user user 0 Oct 26 13:45 user:[4026531837]
lrwxrwxrwx 1 user user 0 Oct 26 13:45 uts:[4026531838]Man erkennt, dass die Inode-Nummern für pid, mnt und net des Container-Prozesses von denen der Host-Prozesse abweichen. Dies bestätigt die Existenz separater Namespaces. Interessant ist, dass im Beispiel der user-Namespace identisch ist, da, wie bereits erwähnt, CLONE_NEWUSER nicht unbedingt standardmäßig verwendet wurde.
Isolation verstehen
Das Verständnis der Namespace-Architektur ist entscheidend für die Beurteilung der Sicherheit von Containern. Da Container den gleichen Kernel wie der Host verwenden und nur durch Systemaufrufe wie unshare() isoliert sind, sind sie nicht mit virtuellen Maschinen (VMs) gleichzusetzen. Eine VM emuliert oder virtualisiert vollständige Hardware und betreibt einen eigenen, unabhängigen Kernel. Die Isolation einer VM ist daher in der Regel robuster, da Angriffe auf den Gast-Kernel den Host-Kernel nicht direkt betreffen.
Bei Containern ist die Situation anders: Ein erfolgreicher Kernel-Exploit innerhalb eines Containers könnte potenziell das gesamte Host-System kompromittieren. Daher ist es von größter Bedeutung, Container sorgfältig zu konfigurieren, um die Isolation nicht zu untergraben. Unnötige Privilegien, schlecht konfigurierte Mount-Punkte oder unzureichende Netzwerk-Isolation können zu gefährlichen “Container-Ausbrüchen” führen. Daher versteht sich auch hier wieder von selbst, warum die Aktualität des Kernels eine enorm wichtige Rolle spielt.
Der Linux-Kernel hat in den letzten Jahren enorme Fortschritte bei der Härtung von Namespaces gemacht. Dennoch bleibt Wachsamkeit geboten, und ein tiefes Verständnis der zugrundeliegenden Mechanismen ist der beste Schutz. Für eine umfassendere Einführung in die Thematik der Namespaces kann der LWN-Artikel “Namespaces in operation, part 1: namespaces overview” als Ausgangspunkt dienen, auch wenn sich seit seiner Veröffentlichung im Jahr 2013 einige Details weiterentwickelt haben.
Fazit
Docker-Container sind keine schlanken VMs, sondern hochentwickelte, isolierte Prozessgruppen, die tief im Linux-Kernel verankert sind. Die Magie ihrer Isolation wird primär durch Linux Namespaces – insbesondere PID-, Mount- und Netzwerk-Namespaces – in Kombination mit Control Groups ermöglicht. Durch Systemaufrufe wie unshare() und clone() wird eine präzise Blase um Container-Prozesse gelegt, die ihnen eine eigene Welt vorgaukelt, während sie doch Teil des Host-Systems bleiben. Dieses fundamentale Verständnis ist unerlässlich, um Container sicher und effektiv in modernen IT-Infrastrukturen einzusetzen.