Kostenlose API für Gemini 2.5
Analyse von Google Gemini 2.5 Flash: Preisgestaltung, Leistung, kostenloser Zugang und praktische Anwendungsbeispiele.


Die Einführung von Gemini 2.5 Flash stellt einen bedeutenden Schritt in der Entwicklung von KI-Modellen dar und wird weitgehend als Antwort auf Modelle wie OpenAIs GPT-4o Mini verstanden. Dieses Modell zeichnet sich durch seine bemerkenswerte Wirtschaftlichkeit und seine integrierten Denkfähigkeiten aus, was es zu einer attraktiven Option für eine breite Palette von Anwendungsfällen macht.
Der Kostenlose Zugang
Ein herausragender Aspekt ist der kostenlose Zugang zu Gemini 2.5 Flash. Das Modell kann kostenfrei über Google AI Studio genutzt werden, wobei hier keine Ratenbegrenzungen existieren. Ich hatte bereits über die Nutzung mit VS-Code berichtet.

Wie kann man die API in eigenen Scripten nutzen
Wie üblich fängt alles mit einem API-Key an. Dieser lässt sich auf der Webseite des AI-Studios von Google leicht erhalten:
Hier kann man auch gleich ein paar Code-Beispiele anschauen. Im API Plan Billing kann man sich die Preise ansehen:
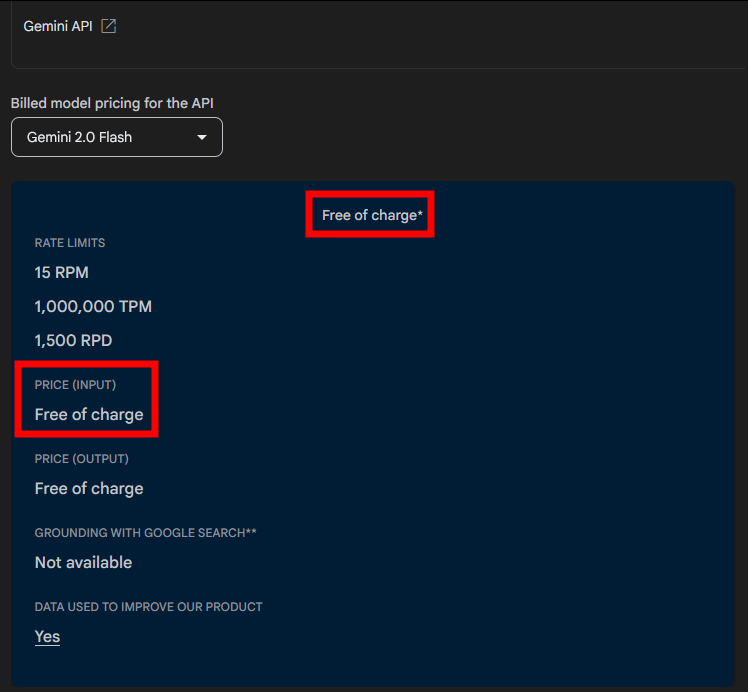
Dies senkt die Einstiegshürde erheblich und ermöglicht es Nutzern, die Fähigkeiten des Modells ausgiebig zu testen. Zusätzlich weist die kostenlose API sehr großzügige Limits auf: 1500 Anfragen pro Tag, 15 Anfragen pro Minute und 1.000.000 Tokens pro Minute. Diese Limits erlauben es den meisten Anwendern, das Modell für ihre Zwecke kostenfrei zu nutzen, inklusive der vollen 24.000 Token Denkfähigkeit innerhalb der Limits. Mir kommt die Begrenzung auf Volumen mehr entgegen, als die zeitliche Begrenzung bei OpenAI.
Kleine Test-Funktion
Ich habe mir testweise eine BASH-Funktion schreiben lassen, mit der ich an der Konsole schnell eine Frage beantworten lassen kann:
ask_ai_gemini() {
GEMINI_MODEL="gemini-2.0-flash"
API_BASE_URL="https://generativelanguage.googleapis.com/v1beta/models"
API_URL="${API_BASE_URL}/${GEMINI_MODEL}:generateContent?key=${GEMINI_API_KEY}"
# Von der PROMPT Variable wird erwartet, dass sie vor dem Aufruf der Funktion gesetzt ist
# Konstruiere das JSON-Payload für die Gemini API
# Die Struktur ist anders als bei Ollama
payload=$(jq -n \
--arg prompt "$PROMPT" \
'{ contents: [ { parts: [ { text: $prompt } ] } ] }')
# Sende den Request an die Gemini API
# -s unterdrückt curl Fortschrittsanzeige
# -X POST gibt die Methode an
# -H setzt den Content-Type Header
# -d sendet das Payload
# Speichere die rohe Antwort, um Fehler zu prüfen
raw_response=$(curl -s -X POST -H "Content-Type: application/json" -d "$payload" "$API_URL")
# Extrahiere die Antwort mit jq
# Der Pfad zum Text ist bei Gemini anders: .candidates[0].content.parts[0].text
extracted_text=$(echo "$raw_response" | jq -r '.candidates[0].content.parts[0].text')
jq_status=$? # Erfasse den Exit-Status von jq
# Prüfe, ob jq erfolgreich war
if [ "$jq_status" -ne 0 ]; then
echo "Fehler: Konnte Text aus Gemini API Antwort nicht extrahieren." >&2
echo "Rohe Antwort: $raw_response" >&2 # Gebe die rohe Antwort zur Fehlersuche aus
# Versuche, eine API-Fehlermeldung zu extrahieren, falls vorhanden
api_error_message
api_error_message=$(echo "$raw_response" | jq -r '.error.message')
if [ "$?" -eq 0 ] && [ -n "$api_error_message" ] && [ "$api_error_message" != "null" ]; then
echo "API Fehlermeldung: $api_error_message" >&2
else
echo "Konnte keine spezifische API Fehlermeldung in der Antwort finden." >&2
fi
ANTWORT=""
return 1
fi
# Speichere den extrahierten Text in der ANTWORT Variable
ANTWORT="$extracted_text"
# Gebe die Antwort aus
echo "$ANTWORT"
}Ein schneller Test offenbart, wie gut das Modell überzeugen kann:
ask_ai_gemini Erstelle eine BASH-Funktion namens get_urls_for, die mir 10 URLs auflistet. Keywords sollen als Argumente übergeben werden. Um bestmögliche Suchergebnisse zu erhalten soll searxng unter https://notgoogle.xxxxxxx.de verwendet werden. Bitte gib nur die Funktion aus.
```bash
get_urls_for(){
KEYWORDS="$*"
NUM_RESULTS=10
SEARXNG_URL="https://notgoogle.xxxxxxx.de/search"
# Suche an SearxNG senden und die ersten 10 Ergebnisse extrahieren
# Führe die Suche durch und speichere die Ergebnisse in der Variable SEARCH_RESULTS
# Führe eine HTTP-Anfrage durch, um die Suchergebnisse von der SEARXNG-URL abzurufen
# -s: Schalte die Fortschrittsanzeige von curl aus (silent mode)
curl -s "${SEARXNG_URL}?q=${KEYWORDS// /%20}&s=0" | \
sed -nr 's/.*href="(https?:\/\/[^"]*)".*/\1/p' | \
grep -Ev "web.archive.org|notgoogle.its-meister.de|searxng" | \
head -${NUM_RESULTS}
}
```Gleich mal testen:
get_urls_for wazuh llm integrations
https://documentation.wazuh.com/current/proof-of-concept-guide/leveraging-llms-for-alert-enrichment.html
https://www.bleepingcomputer.com/news/security/integrating-llms-into-security-operations-using-wazuh/
https://wazuh.com/blog/leveraging-claude-haiku-in-the-wazuh-dashboard-for-llm-powered-insights/
https://wazuh.com/blog/nmap-and-chatgpt-security-auditing/
https://cybernoz.com/integrating-llms-into-security-operations-using-wazuh/
https://news.lavx.hu/article/revolutionizing-security-operations-integrating-llms-with-wazuh
https://codesanitize.com/integrating-llms-into-safety-operations-utilizing-wazuh/
https://www.reddit.com/r/Wazuh/comments/1ivhimf/looking_for_ai_integration_ideas_for_wazuh_siem/
https://github.com/Homaei/CyberSentinelAI
https://31wedge.com/integrating-llms-into-security-operations-using-wazuh/Funktioniert!
Fazit
AI-Studio war bereits in seiner ursprünglichen Form äußerst leistungsfähig. Besonders das große Kontextfenster ermöglicht es, sehr umfangreiche Prompts zu verarbeiten. Die Möglichkeit, dieses System über eine API in eigene Skripte und Tools zu integrieren – sofern man nicht lieber auf eine eigene KI-Lösung setzt – macht die Nutzung nicht nur besonders flexibel, sondern auch bemerkenswert schnell. So wird ein automatisierter Zugriff auf extrem leistungsstarke Modelle Realität.