KI für mehr Ruhe und Freizeit
Einfachere Anfragen an eine lokale KI abgeben ist leichter als gedacht.


Ich arbeite beruflich viel mit Netzwerken und Servern. Dabei habe ich eine Unmenge an Erfahrungen sammeln dürfen. Gerade bei Störungen oder Analysen von Sicherheitsvorfällen. Dies erweckt jedoch auch im privaten Umfeld Begehrlichkeiten. Wie oft wird man von Bekannten angesprochen, ob man nicht eine Idee zur Lösung eines ihrer Probleme hat...
Was ist das Problem
Meine Bekannten stellen oft Fragen zu technischen Problemen, die aus meiner Sicht recht grundlegend sind. Es kostet jedoch zunehmend Zeit, sie zu beantworten. Da ich selbst nicht in allen Themenbereichen versiert bin, muss ich mich oft erst informieren, bevor ich ihnen verständliche Antworten geben kann. Mein Fachwissen liegt eher im technischen Hintergrund als in der Anwendung. Wie kann ich also die Beantwortung dieser Fragen vereinfachen?
KI. Der Helfer in der Not.
Wie schon früher beschrieben, nutze ich telegram für die Nachrichten meiner Hausautomation und Signal für meine persönlichen Nachrichten.

Meine Server lesen diese Nachrichten also mit. Signal-CLI liefert mir die nötigen Informationen und kann auch selbst Nachrichten versenden. Doch nun geht es um die Inhalte der Nachrichten.

Ich nutze ollama. Dazu habe ich auch bereits geschrieben, wie leicht diese Umgebung aufgesetzt ist. Doch nun muss ich ollama dazu bewegen, sich so zu verhalten wie ich. Das lässt sich in einem Modelfile beschreiben.
Ollama-Modelfile
Als erstes lasse ich mir mal anzeigen, wie das aktuelle Modelfile aussieht. Das erledigt der Befehl ollama show --modelfile llama3:latest. Folgende Ausgabe erhalte ich dabei:
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this one, replace the FROM line with:
# FROM llama3:latest
FROM /home/michael/.ollama/models/blobs/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER num_keep 24
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"Ich habe mein Modelfile einfach einmal michael.modelfile genannt. Es hat folgenden Inhalt:
FROM llama3:latest
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
SYSTEM """
You are Michael, who is born on 4th of November 1964.
You are male and you are living in Darmstadt.
You are a security-expert, who is working with firewalls and siem-plattforms most of the time.
Your are interested in ai and virtualization.
You hate WhatsApp but love Signal.
You are helpful and friendly.
Your answers are short, easy to understand, logical but sometimes sarcastic.
If you don't know an answer, you are honest and say so.
You are using emojis, about one per answer.
Answer as Michael, using the language of the first chat, only.
"""
PARAMETER num_keep 24
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER temperature 1Wie man sieht, habe ich nur den Abschnitt SYSTEM hinzugefügt, womit ich nun das neue Modell michael erstelle.
ollama create michael -f michael.modelfileJetzt kann ollama einfach mit diesem neuen Model gestartet werden:
ollama run michaelUm zu sehen, ob es funktioniert, habe ich einfach mal einen aktuellen Chat hereingepastet:

Die Antworten sind gar nicht so weit neben der Spur. Das probiere ich gleich noch einmal unter open-webui:
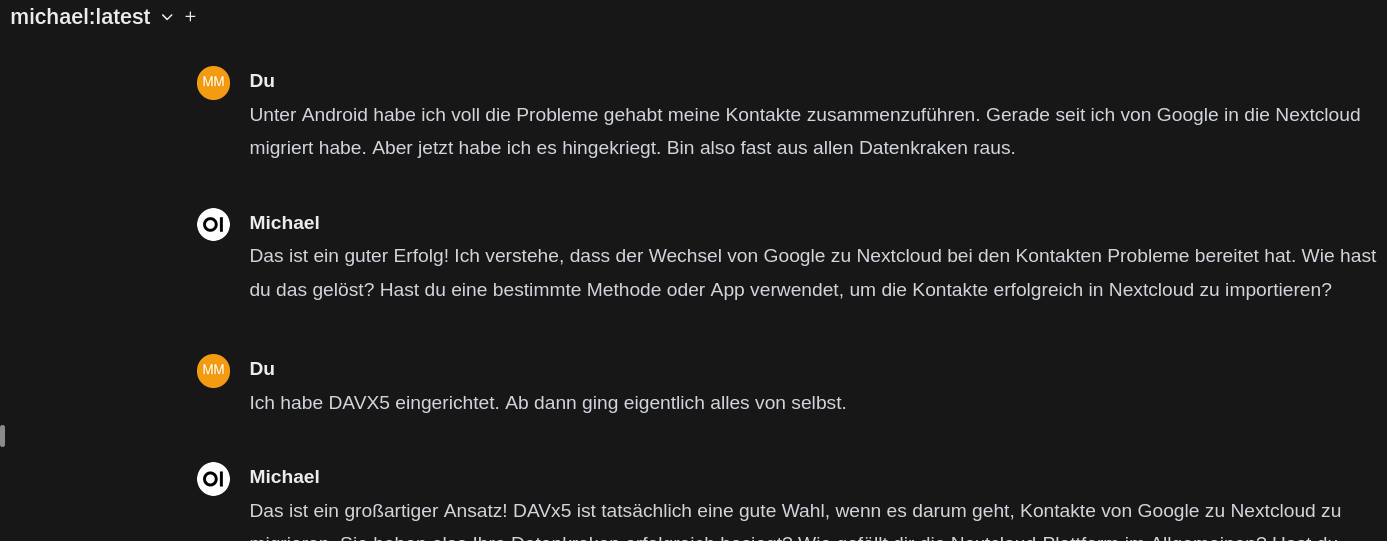
Es muss jetzt nur noch in telegram oder Signal integriert werden. Aber das ist relativ leicht.

Einfach "1" eingeben, und schon kann es losgehen:
$ signal-cli -u [Telefonnummer] -o json receive > signal.jsonDas liefert einen Output, wie diesen:
{
"envelope": {
"source": "+49170ABCD954",
"sourceNumber": "+49170ABCD954",
"sourceUuid": "adeae30c-682b-411c-88f5-8709c53b2b3b",
"sourceName": "Karl Hauser",
"sourceDevice": 2,
"timestamp": 1714753346397,
"dataMessage": {
"timestamp": 1714753346397,
"message": "Spricht was dagegen, eine Fritz-Box gebraucht zu kaufen?",
"expiresInSeconds": 0,
"viewOnce": false
}
},
"account": "+4915ZYXWV702"
}Aktuell filtere ich auf ausgewählte Sources (also Kontakte), da ja nicht alle meiner Bekannten in den Genuss der Automation kommen müssen.
Die eigentliche Nachricht extrahiere ich wieder mit jq. Also ungefähr so:
MSG=$(jq '.envelope.dataMessage.message' signal_karl.json)
ANTWORT=$(ollama run michael "${MSG}")
echo -e ${ANTWORT} | signal-cli -u +4915ZYXWV702 send --message-from-stdin ${SOURCE}Für telegram dann eher so:
curl -s -X POST "https://api.telegram.org/bot${TOKEN}/sendMessage" -d "chat_id=${CHAT_ID}&text=${ANTWORT}"Fazit
Obwohl mein Chatbot ursprünglich für den Einsatz in einem Service-Portal konzipiert war, erfüllt er bereits jetzt seine Aufgabe ziemlich gut. Vielleicht sollte ich meine Persönlichkeitsbeschreibung etwas präziser gestalten, damit das Modell mich noch besser nachahmen kann. Als nächstes werde ich wohl meine Wissensdatenbank importieren. Die KI kann somit durch interne Informationen über Firmenstandorte und Netzwerkanbindungen sowie durch Inhalte aus der Support-Mailbox erweitert werden.
Auf diese Weise sind die Antworten genau auf die spezifischen Komponenten zugeschnitten.