Incident-Response: Public Playbooks


Ein Security Operations Center (SOC) spielt eine entscheidende Rolle beim Schutz einer Organisation vor Cyberbedrohungen. Playbooks für Incident Responses im SOC sind äußerst vorteilhaft aus verschiedenen Gründen:
Standardisierung von Prozessen:
- Playbooks helfen bei der Standardisierung von Abläufen und Prozessen im Incident Response. Dies sorgt dafür, dass Teammitglieder klare Anweisungen haben, wie sie auf bestimmte Arten von Sicherheitsvorfällen reagieren sollen.
Schnelle Reaktion:
- Durch vordefinierte Playbooks kann das SOC schnell auf Sicherheitsvorfälle reagieren. Zeit ist oft entscheidend, wenn es darum geht, einen Angriff zu erkennen, zu verstehen und darauf zu reagieren.
Effizienzsteigerung:
- Playbooks ermöglichen eine effizientere Nutzung der Ressourcen im SOC. Teammitglieder können sich auf die Durchführung vordefinierter Schritte konzentrieren, anstatt Zeit mit der Entwicklung von Reaktionsplänen für jeden Vorfall zu verschwenden.
Wissenstransfer:
- Playbooks dienen als Wissensquelle für das Team. Neue Mitglieder können sich schnell in die Arbeitsweise des SOC einarbeiten, indem sie auf die Playbooks zugreifen und die darin festgelegten Verfahren verstehen.
Verbesserte Zusammenarbeit:
- Playbooks fördern eine bessere Zusammenarbeit im Team, da alle Mitglieder nach den gleichen Richtlinien arbeiten. Dies erleichtert die Kommunikation und Koordination während eines Sicherheitsvorfalls.
Dokumentation von Erfahrungen:
- Durch die Verwendung von Playbooks können Erfahrungen und Erkenntnisse aus vergangenen Sicherheitsvorfällen dokumentiert werden. Dies ermöglicht eine kontinuierliche Verbesserung der Reaktionsstrategien im Laufe der Zeit.
Compliance-Anforderungen erfüllen:
- In einigen Branchen und Regionen sind Organisationen gesetzlich verpflichtet, bestimmte Sicherheitsstandards einzuhalten. Playbooks können dazu beitragen, die Einhaltung dieser Standards sicherzustellen, indem sie klare Schritte für die Incident Response festlegen.
Zusammenfassend ermöglichen Playbooks im SOC eine konsistente, effiziente und strukturierte Reaktion auf Sicherheitsvorfälle, was entscheidend ist, um die Auswirkungen von Cyberbedrohungen zu minimieren und die Sicherheit einer Organisation zu gewährleisten.
Wo fängt man an, wenn man ein SOC frisch aufbaut
Eines ist klar. Die Fäden laufen bei MITRE zusammen. Hier wird beschrieben, wie ein SOC beschaffen sein sollte, je nach Unternehmensgröße. Auch die verschiendenen Angriffstaktiken und -methoden sind hier dargelegt. Alles sehr nützliche Informationen, zeigen sie doch genau auf, welche Quellen erforderlich sind, um entsprechende Angriffe erkennen zu können.
Es ist eine der wichtigsten Überlebensstrategien, im Falle eines Angriffs Abläufe vorbereitet zu haben, die helfen den Angriff abzuwehren und Fehler dabei zu vermeiden.
Solche Playbooks neu zu erstellen ist mühselig. Doch diesen Aufwand kann man reduzieren, wenn man auf Erfahrungen anderer Firmen, und kritischer Infrastrukturen, zurückgreifen kann.
Gepflegte Playbooks auf Gitlab
Die Webseite https://gitlab.com/syntax-ir/playbooks enthält eine Sammlung von öffentlichen Playbooks für die Incident Response (IR). IR ist der Prozess der Reaktion auf - und Behebung von - Sicherheitsvorfällen. Playbooks sind vordefinierte Handlungsabläufe, die dabei helfen, die Reaktion auf einen Vorfall zu koordinieren und zu beschleunigen.
Die Playbooks auf der oben genannten Webseite sind in vier Phasen unterteilt:
- Vorbereitung: Diese Phase umfasst die Planung und Vorbereitung auf den Fall eines Vorfalls.
- Erkennung und Analyse: In dieser Phase wird der Vorfall erkannt und analysiert, um die Ursache und den Umfang des Schadens zu bestimmen.
- Eindämmung, Beseitigung und Wiederherstellung: In dieser Phase wird der Vorfall eingedämmt und beseitigt, und die Systeme und Daten werden wiederhergestellt.
- Post-Vorfall-Aktivitäten: In dieser Phase werden die Vorfälle dokumentiert und ausgewertet, um Lerneffekte zu erzielen.
Die Playbooks sind für verschiedene Arten von Vorfällen konzipiert, darunter:
- Datenverstöße: Bei einem Datenverstoß werden vertrauliche Daten gestohlen oder verloren.
- Malware-Infektionen: Bei einer Malware-Infektion wird ein Computer oder Netzwerk durch Schadsoftware infiziert.
- DDoS-Angriffe: Bei einem DDoS-Angriff wird ein Computer oder Netzwerk durch eine Überlastung mit Datenverkehr angegriffen.
- Phishing-Angriffe: Bei einem Phishing-Angriff versuchen Angreifer, Benutzer durch gefälschte E-Mails dazu zu bringen, persönliche Daten preiszugeben.
Die Playbooks sind in einem strukturierten Format geschrieben und enthalten alle wichtigen Informationen, die für die Reaktion auf einen Vorfall erforderlich sind. Dazu gehören:
- Definition des Vorfalls: Was ist der Vorfall?
- Schritt-für-Schritt-Anleitungen: Was muss getan werden, um den Vorfall zu beheben?
- Ansprechpartner: Wer ist für die Reaktion auf den Vorfall verantwortlich?
Die Playbooks können von Unternehmen, Organisationen und Einzelpersonen verwendet werden, um sich auf einen Sicherheitsvorfall vorzubereiten und um die Reaktion auf einen Vorfall zu koordinieren und zu beschleunigen. Sie werden von der Community ständig weiterentwickelt.
Beispiel
Jemand meldet beim SOC, dass er bemerkt hat, dass sein Rechner deutlich langsamer arbeitet als gewohnt. Doch was ist nun zu tun?
Es wäre gut, wenn das Team nicht unter Zeitdruck und Panik geraten würde. Abgesehen von Ablaufdiagrammen finden sich in den Playbooks auch genaue Beschreibungen, was zu tun ist:
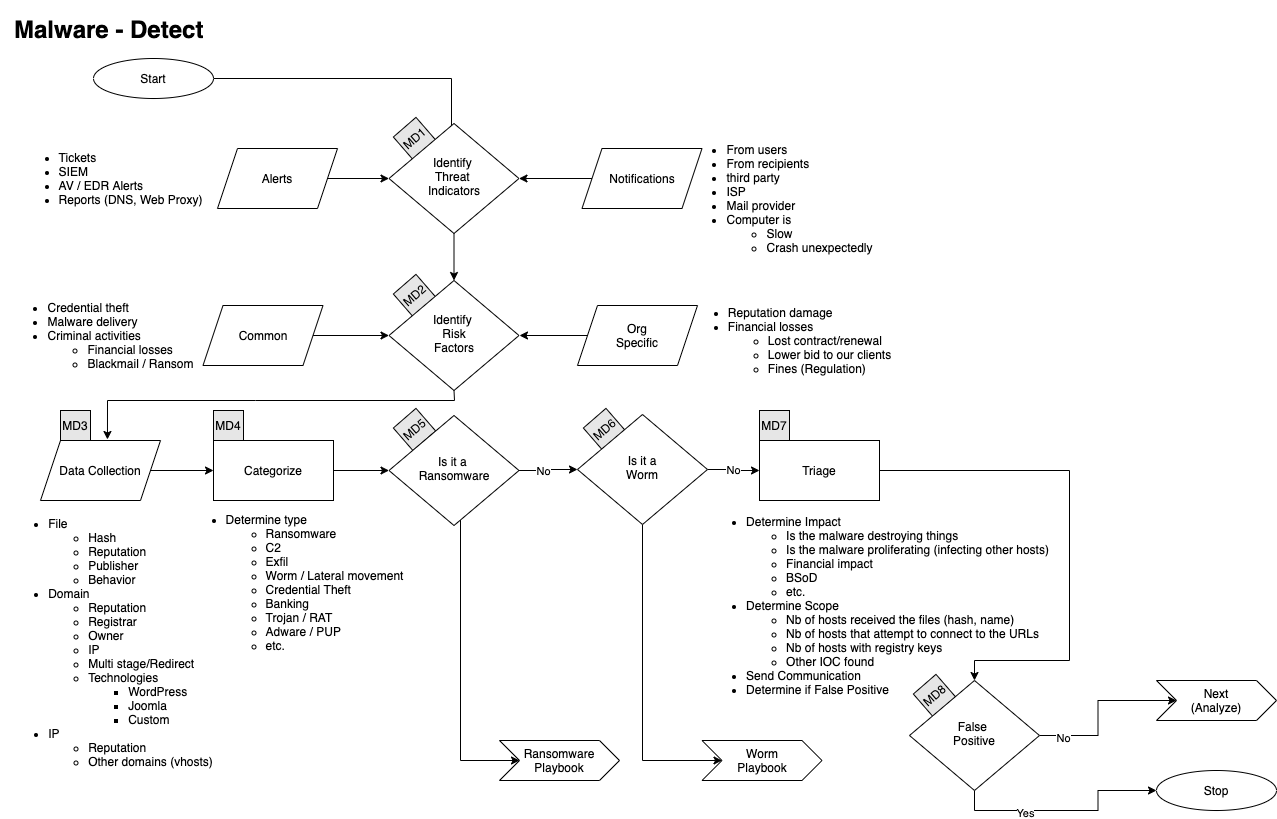
In den genauen Beschreibungen der einzelnen Blöcke befinden sich Abläufe, die das Personal eines SOCs versteht. So wurde bereits in MD1 die Bedrohung erkannt. Die weiteren Module helfen, die Bedrohung genauer zu spezifizieren. Gehen wir mal davon aus, dass wir keine Indizien für eine Erpressung gefunden haben und niemand sonst diese Symptome wahrgenommen hat. Dann würde eine Analyse folgen.
Analyse
Wie geht man dabei vor? Sehen wir uns auch hier den grafischen Ablauf an:
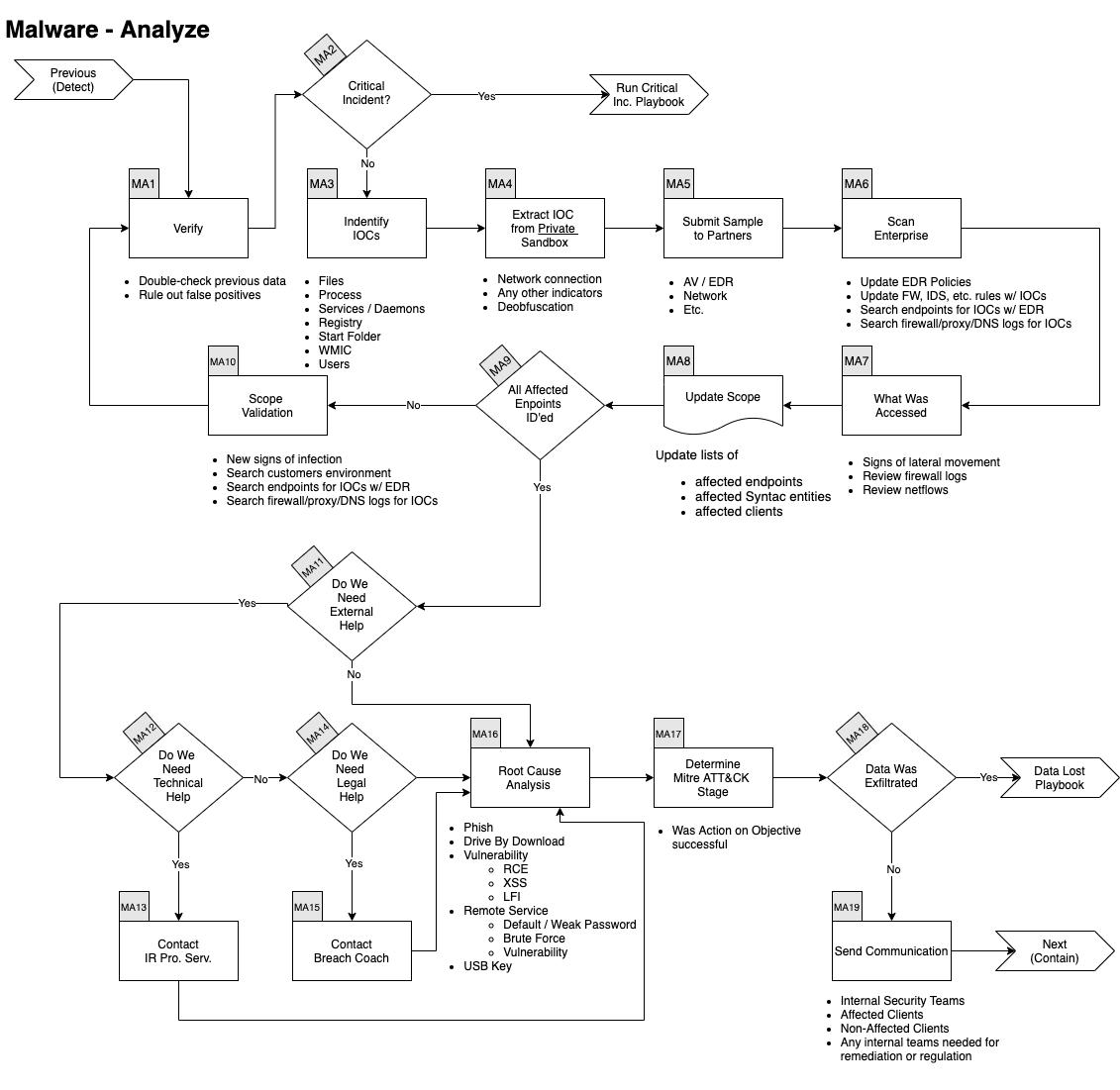
Man kann auch hier wieder genau erkennen, wie vorzugehen ist. Gut, dass wir bereits erkannt haben, nicht unter Zeitdruck zu sein, da bisher keine Indizien vorliegen, dass sich ein Wurm ausbreitet. So können die Forensiker des SOCs ihrer Aufgabe nachgehen, während die Analysten nach weiteren IOCs (Indicators Of Compromise) suchen.
Hier würde die Analyse wohl mit Tools, wie z.B. Autopsy oder Cuckoo, fortgesetzt werden. Und sollte dabei das Ergebnis sein, dass tatsächlich nur ein lokaler Virus eingefangen wurde, geht es darum eine Ausbreitung zu verhindern - was uns zum nächsten Schritt bringt.
Eindämmung, Beseitigung und Wiederherstellung
Bei einer Malware-Infektion ist der erste Schritt, das betroffene System von anderen Systemen im Netzwerk zu isolieren. Anschließend wird die Malware analysiert, um die Art der Infektion und die Auswirkungen zu ermitteln. Wenn die Malware mit Administratorrechten ausgeführt wurde, muss das System möglicherweise formatiert oder gelöscht werden. Wenn die Malware ohne Administratorrechte ausgeführt wurde, können IOCs gelöscht werden, um die Malware zu beseitigen. In einem letzten Schritt wird das System wiederhergestellt und die Auswirkungen der Infektion beseitigt.
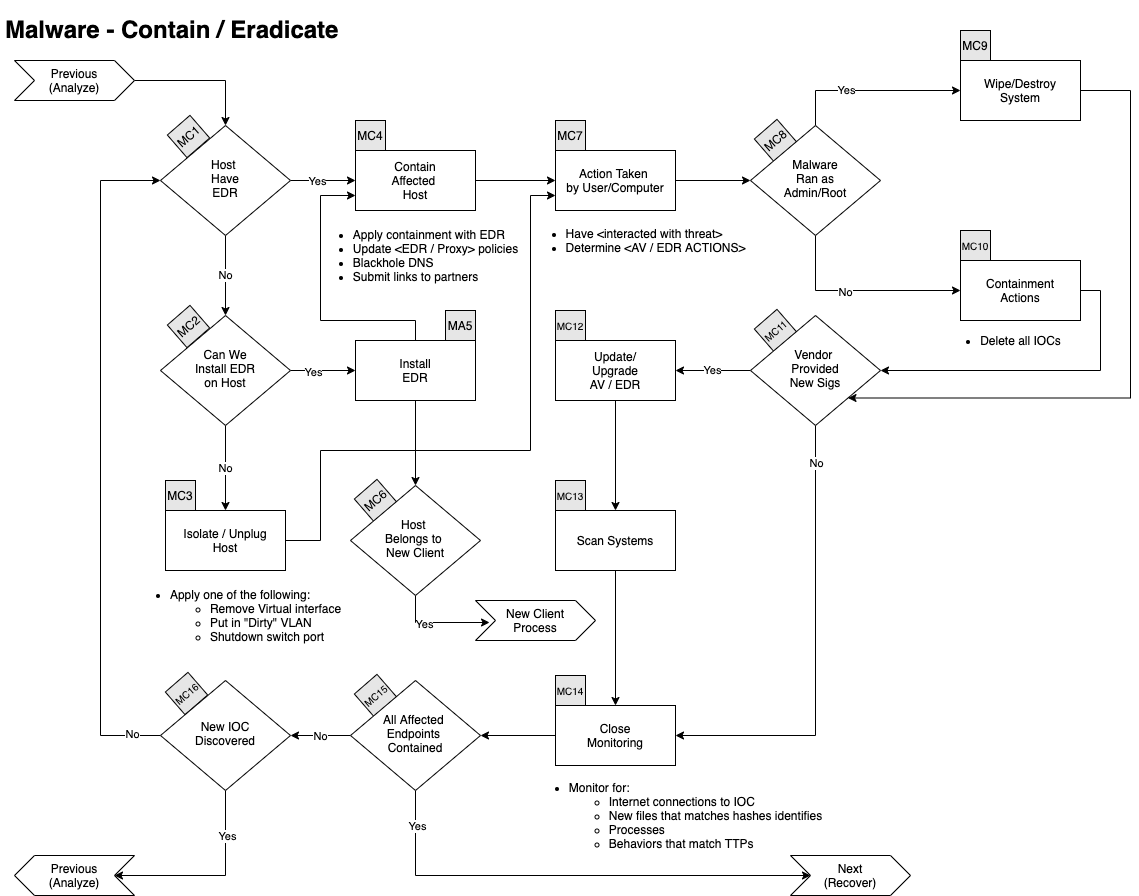
Die Eindämmung der Malware ist wichtig, um zu verhindern, dass sie sich weiter ausbreitet. Die Analyse der Malware ist wichtig, um die richtige Beseitigungsstrategie zu wählen. Die Beseitigung der Malware ist wichtig, um die Auswirkungen der Infektion zu minimieren. Die Wiederherstellung des Systems ist wichtig, um den normalen Betrieb wiederherzustellen.
Recover
Hier gilt es sicherzustellen, dass das betroffene System wieder sauber zum Laufen gebracht wird.
Auch dafür gibt es einen Plan:
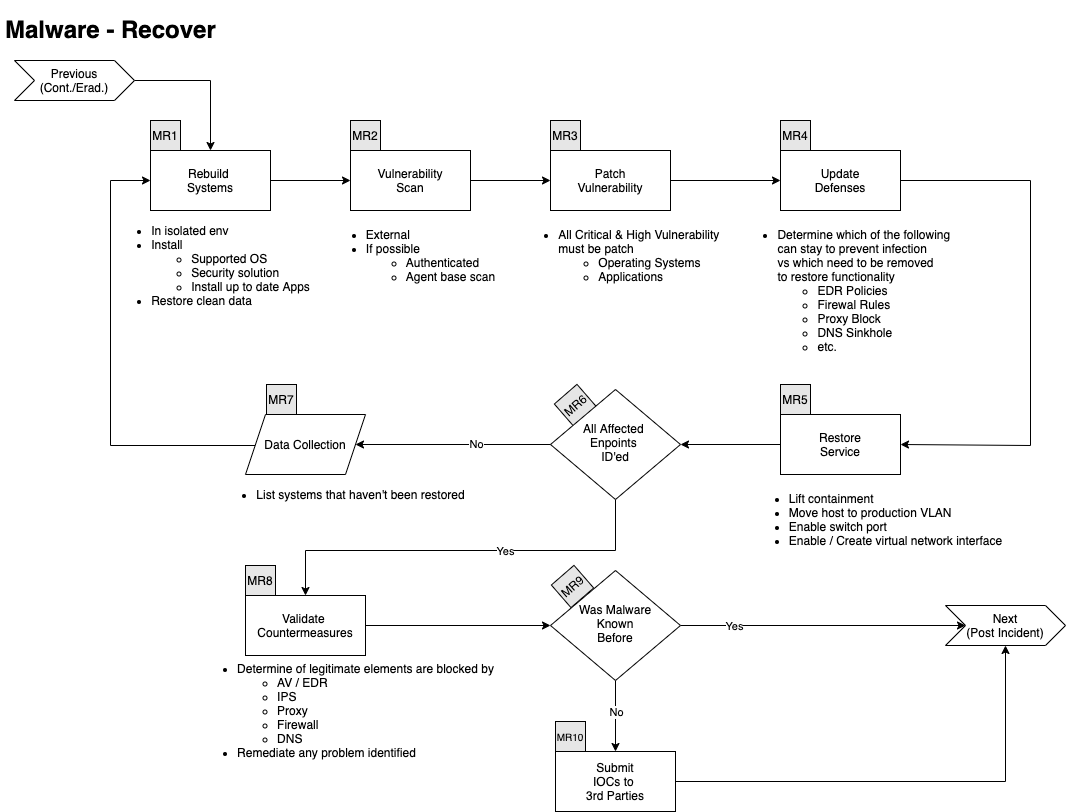
Wenn das System wieder ordnungsgemäß funktioniert, kann das Team den Vorfall dokumentieren und die Prozeduren verbessern.
Post Incident
Zuletzt wird betrachtet, was gut funktioniert hat, oder eben nicht. Aus diesen Erkenntnissen werden nun die Prozeduren optimiert. Aber auch die technischen Rahmenbedingungen werden verbessert. Darunter vielleicht IPS-Signaturen, SIEM-Rules, Endpoint-Detection Rules und was man sonst zur Verfügung hat.
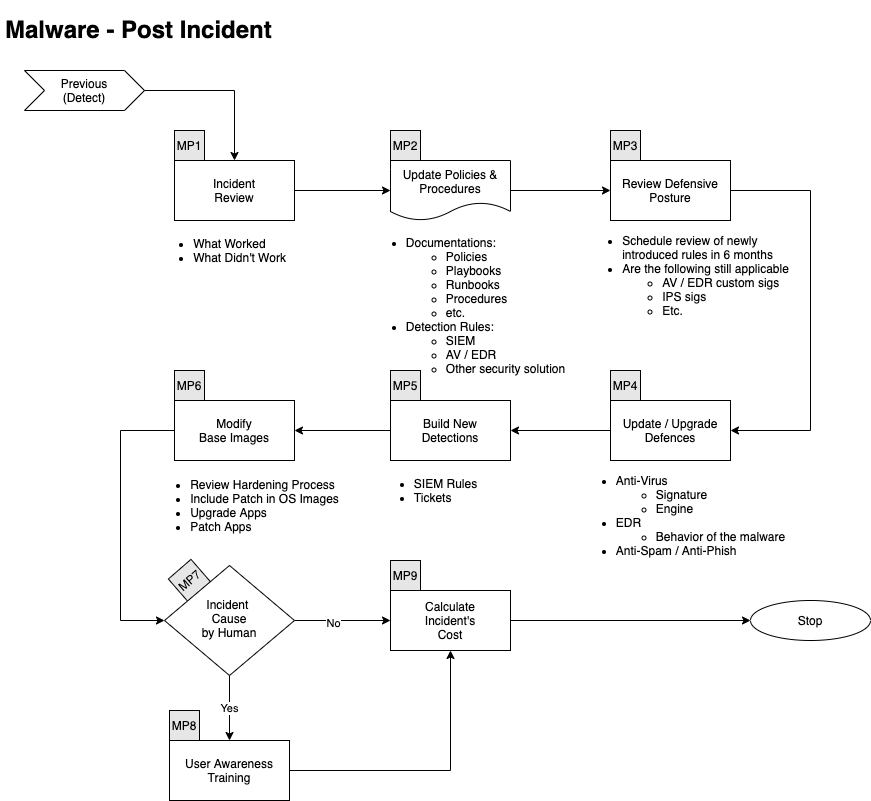
Auch das Playbook, das man für den Incident durchlaufen hat, ist Bestandteil der Optimierungen. Und vielleicht hat man etwas vergessen, wie zum Beispiel weitere Schulungen des Personals...
Aber dies ist nur ein kleines Beispiel der Aufgaben eines SOC. Und es gibt viele mögliche Angriffe auf eine Organisation. Daraus gehen entsprechend viele Playbooks hervor.
Folgen, wenn ein Unternehmen nicht vorsorgt
Es gibt viele Beispiele für Unternehmen, die einen Cyberangriff nicht überlebt haben. Hier sind einige Beispiele:
- Die niederländische Zahlungsdienstleisterin DigiNotar wurde 2011 Opfer eines Angriffs, bei dem die Hacker die digitale Signatur des Unternehmens missbrauchten, um gefälschte SSL-Zertifikate zu erstellen. Dies führte zu einem Vertrauensverlust bei den Kunden und zum Konkurs des Unternehmens.
- Die US-amerikanische Einzelhandelskette Target wurde 2013 Opfer eines Angriffs, bei dem die Hacker die Kreditkartendaten von über 40 Millionen Kunden erbeuteten. Dies führte zu einem Rückgang der Kundenzahlen und zu einem Umsatzverlust von über 1 Milliarde US-Dollar.
- Der britische Energieversorger TalkTalk wurde 2016 Opfer eines Angriffs, bei dem die Hacker die persönlichen Daten von über 156.000 Kunden erbeuteten. Dies führte zu einer Strafzahlung von 400.000 Pfund und zu einem Vertrauensverlust bei den Kunden.
Die Gründe, warum Unternehmen einen Cyberangriff nicht überleben, sind vielfältig. Dazu gehören:
- Ein mangelhaftes Cybersicherheits-Management: Unternehmen, die nicht ausreichend in ihre Cybersicherheit investieren oder nicht über eine angemessene Cybersicherheitsstrategie verfügen, sind anfälliger für Cyberangriffe. Oft werden Sicherheitsprozesse von Mitarbeitern verfasst, die keine praktische Erfahrung mit Cybersecurity haben. Falscher Stolz, die Empfehlungen der Spezialisten des eigenen Unternehmens nicht anzuhören und zu berücksichtigen, scheint einen großen Prozentanteil dieser Folgen einzunehmen.
- Ein fehlendes Bewusstsein für Cyberrisiken: Mitarbeiter, die nicht über die Gefahren von Cyberangriffen und die richtigen Verhaltensweisen im Umgang mit Cyberrisiken geschult sind, können zu einem Einfallstor für Hacker werden. Oft werden Systeme nur isoliert betrachtet. Meiner Erfahrung nach ist es meist die Kombination, die nicht beachtet wurde - also z.B. die Folgen, wenn ein Angreifer einen Mailserver eingenommen hat. Ich habe erlebt, dass ein Systemhaus seine Strategie zur Abwehr des Angriffs per Mail koordiniert hat, und dabei vergessen hatte, dass der Angreifer dies mitlesen konnte und sich entsprechend vorbereiten konnte.
- Ein Mangel an Notfallplänen: Unternehmen, die nicht über einen Notfallplan für den Fall eines Cyberangriffs verfügen, sind nicht in der Lage, einen solchen Angriff schnell und effektiv zu bewältigen.
Um einen Cyberangriff zu überleben, ist es wichtig, dass Unternehmen ihre Cybersicherheits-Maßnahmen verbessern und ihre Mitarbeiter für Cyberrisiken sensibilisieren. Darüber hinaus sollten Unternehmen einen Notfallplan für den Fall eines Cyberangriffs haben.
Fazit
Wie man sieht, sind die Aufgaben recht umfangreich. Sie umfassen viele verschiedene Themen. Und das sind nicht nur Forensik und Analyse. Sie erstrecken sich auch über das Durchsetzen der Richtlinien. Also z.B. die Beschränkungen des Netzwerkverkehrs durch Firewalls und Intrusion-Prevention-Systeme, oder Umsetzen der Proxy Regeln. Aber auch das Wissen um die eigenen Schwachstellen ist wichtig. Und so gehört auch ein Pentesting-Team zum SOC. Dies ist alles im Mitre-Buch über den Aufbau eines SOC beschrieben.
Auf bereits gereifte Playbooks zurückgreifen zu können und diese an das eigene Unternehmen anzupassen, ist sicherlich eine große Hilfe beim Aufbau eines SOC. Dieses dann zu klein zu dimensionieren ist daher auch der größte Fehler, den ein Unternehmen machen kann. Und das zeigt sich spätestens, wenn das Unternehmen seine Dienste braucht.