Dia-TTS: Realistische Dialoge mit der eigenen Stimme
Ein neues Open-Source-Modell erzeugt Dialoge, die kaum von echten zu unterscheiden sind. Zumindest auf englisch.


Das von Nari Labs entwickelte Text-to-Speech-Modell “Dia” sorgt für Aufsehen in der Welt der künstlichen Stimmgenerierung. Es ist als Open-Source-Projekt konzipiert und spezialisiert sich auf die Erzeugung von ultra-realistischen Dialogen, statt nur einzelne Sätze vorzulesen. Ein genauerer Blick auf die Technik, die Installation und die wichtigen ethischen Rahmenbedingungen ist daher angebracht.
[UPDATE]:
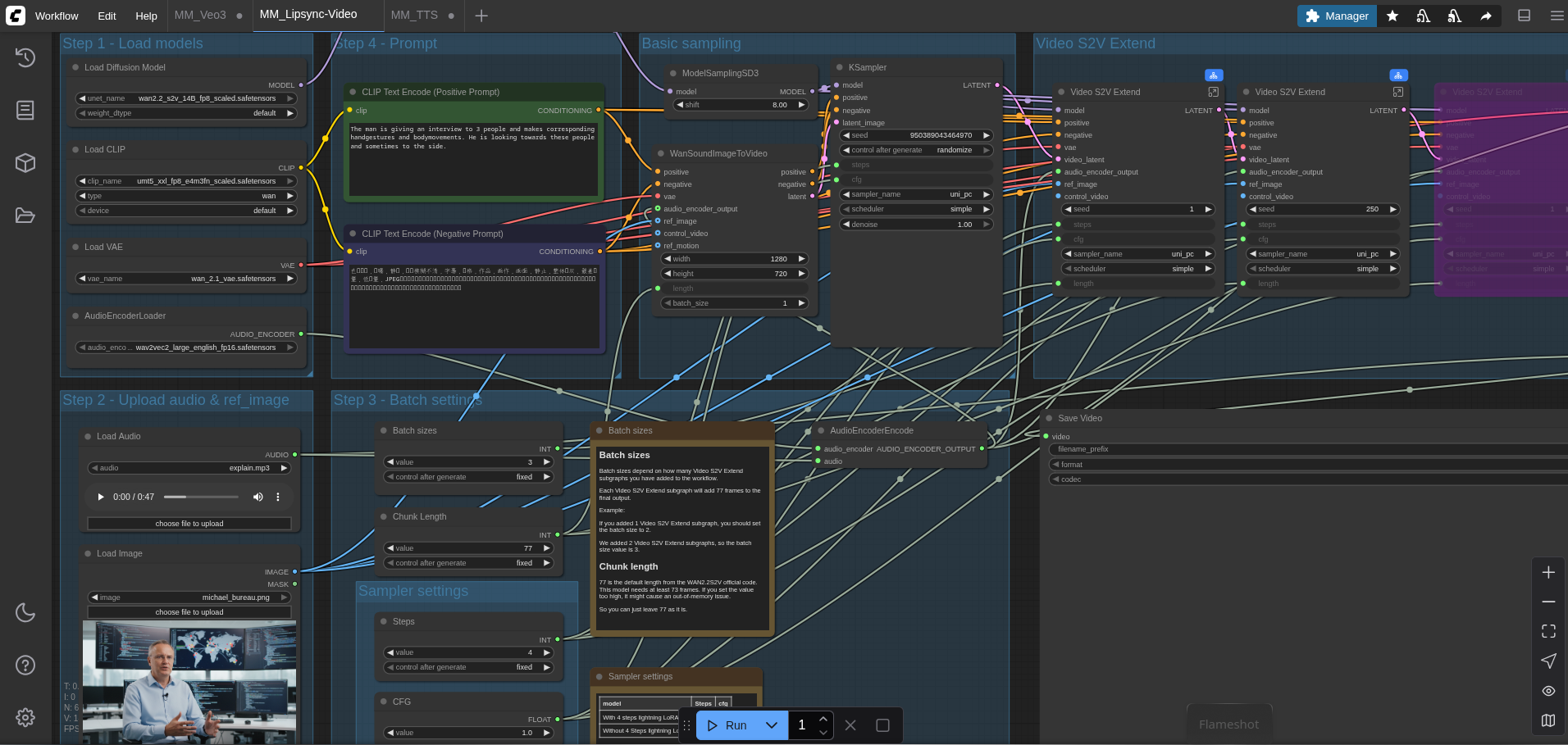
Meine älteren Projekte
Früher habe ich einfach Online-Dienste genutzt. Dabei musste ich zunächst die Texte in einzelne Sätze zerlegen, aber das war ein relativ einfacher Zwischenschritt.

Die logische Konsequenz meines Selfhosting Gedanken war natürlich, die eigene Sprache lokal vorzuhalten. Das war zu der Zeit noch extrem aufwendig.

Dia ist ein weiterer Zwischenschritt, bei dem ein einziger gesprochener Satz genügt, um damit sehr lange Texte in Sprache zu verwandeln. Die Texte, oder auch Dialoge, lasse ich mir dabei meist von einer KI schreiben, die zusätzlich Lachen und Atemgeräusche als Marker platziert. Ein toller Vergleich ist hier.
Was ist Dia überhaupt?
Dia ist ein auf Transformatoren basierendes Text-to-Speech (TTS) Modell mit 1.6 Milliarden Parametern. Entwickelt von dem kleinen südkoreanischen Startup Nari Labs, das ohne externes Funding auskam, steht das Projekt unter der freizügigen Apache-2.0-Lizenz auf GitHub zur Verfügung. Das primäre Ziel des Modells ist nicht nur die Umwandlung von Text in Sprache, sondern die Generierung kompletter, natürlich klingender Dialoge zwischen zwei Sprechern, inklusive emotionaler Nuancen und non-verbaler Laute.
Die Technik hinter dem Vorhang
Das Modell wurde stark von Architekturen wie Googles SoundStorm und Parakeet inspiriert, aber speziell für Dialoge optimiert. Die Kernfunktionen sind beeindruckend und umfassen:
- Multi-Sprecher-Dialoge: Durch die Verwendung von Tags wie
[S1]und[S2]im Eingabetext kann das Modell ein Gespräch zwischen zwei unterschiedlichen Stimmen erzeugen und deren Charakteristika über den gesamten Dialog beibehalten. - Non-verbale Geräusche: Dia kann eine Reihe von non-verbalen Lauten wie
(laughs),(coughs),(sighs)oder(gasps)in die Sprachausgabe integrieren, was die Authentizität erheblich steigert. Die Liste der erkannten Geräusche ist erstaunlich lang und enthält sogar(burps)– für welche Anwendungsfälle auch immer das gedacht sein mag. - Zero-Shot Voice Cloning: Mit nur wenigen Sekunden Referenz-Audio kann das Modell eine Stimme klonen und für die Generierung neuer Inhalte verwenden. Die Stimmkonsistenz kann alternativ auch durch die Verwendung eines festen Seeds gewährleistet werden.
Für den Betrieb ist aktuell eine GPU mit CUDA-Unterstützung (PyTorch 2.0+) notwendig. Ein Test auf einer RTX 4090 zeigte, dass für die Generierung im bfloat16-Format rund 4.4 GB VRAM benötigt werden, während das float32-Modell knapp 7.9 GB beansprucht. CPU-Support sowie quantisierte Versionen für geringere Hardwareanforderungen sind für die Zukunft geplant.
Installation und Inbetriebnahme
Die Installation unter Linux ist unkompliziert und kann direkt über pip erfolgen. Es wird empfohlen, dies in einer virtuellen Umgebung zu tun.
# Repository klonen
git clone https://github.com/nari-labs/dia.git
cd dia
# Optionale virtuelle Umgebung
python -m venv .venv && source .venv/bin/activate
# Dia installieren
pip install -e .
# Abhängigkeiten für Hugging Face Transformers aktualisieren
pip install git+https://github.com/huggingface/transformers.gitNach der Installation kann eine webbasierte Demo-Oberfläche mit Gradio gestartet oder das Kommandozeilen-Interface genutzt werden.
# Web-UI starten
python app.py
# CLI-Hilfe anzeigen
python cli.py --helpSchneller Test
Um mal eben schnell zu zeigen, wie sich die eigene Stimme anhört, habe ich im Webfrontend einfach mal auf das Mikrofon geklickt und einen Satz eingesprochen. Das ist natürlich nicht die beste Vorlage, aber man erhält einen Eindruck, was die KI aus so einer kleinen Vorlage macht.
Und so "schlecht" hört sich das Original dann an:
Ich habe dann einfach mal den gleichen Satz erzeugen lassen, um einen direkten Vergleich zu haben. Zusätzlich habe ich die seed auf einen konstanten Wert eingestellt, da man nur etwa 30 Sekunden erzeugen kann. Längere Passagen zerlege ich daher vorher in jeden einzelnen Satz, der so ebenfalls mit einer konstanten Stimme erzeugt wird.
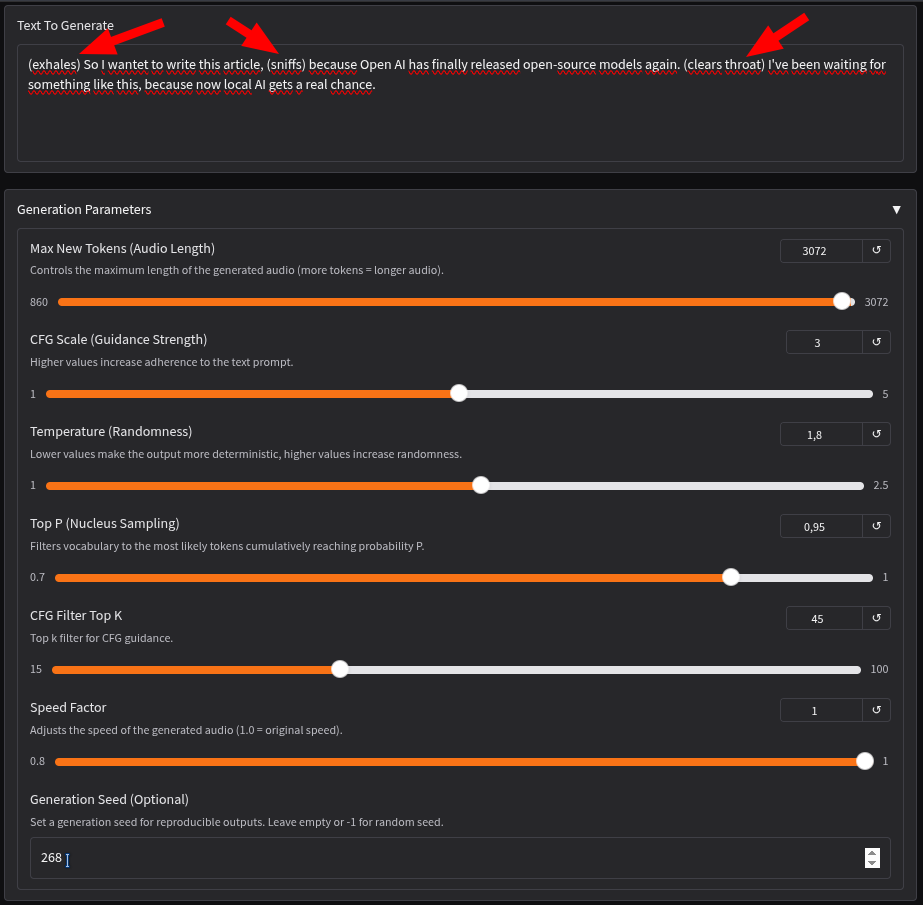
Und das klingt mit den eingefügten Geräuschen dann so:
Während ich im Original beim Ablesen des Textes nicht sonderlich flüssig gesprochen habe, hat die KI das fix korrigiert.
Freie Hand für einen Dialog
Wenn ich Dia komplett freie Hand gebe und einfach nur einen Text eingebe, kommen recht gute Ergebnisse dabei heraus. Zum Beispiel für einen beliebigen Dialog:

Daraus wird dann:
Längere Texte mit TTS umwandeln
Zwei Sätze sind natürlich extrem wenig. Daher behelfe ich mir mit einem Script, dass jeden Satz einzeln betrachtet. Die Funktion tts() kann ich so auch leicht austauschen, z.B. für deutsche Gespräche mittels Thorsten-Voice. Das wird aber ein eigener Blogpost 😃.
#!/bin/bash
text="$(cat -)"
seed=268 # Damit bleibt meine Stimme nahe am Original ;-)
tts() {
local sentence="$1"
local outfile="$2"
echo "Erzeuge mit Dia TTS: '$sentence' → $outfile"
python dia/cli.py "$sentence" \
--output "$outfile" \
--repo-id nari-labs/Dia-1.6B \
--seed "$seed"
}
# Text in Sätze splitten
IFS=$'\n' read -d '' -r -a sentences < <(
echo "$text" | tr -d '\n' |
sed 's/[.!?]/&\n/g' |
sed '/^[[:space:]]*$/d'
)
# Jeden Satz mit tts() verarbeiten
count=1
rm -f part_*.wav
for sentence in "${sentences[@]}"; do
clean=$(echo "$sentence" | xargs)
outfile="part_${count}.wav"
tts "$clean" "$outfile"
count=$((count+1))
done
# WAVs zu MP3 zusammenfügen
echo "file '$PWD/part_1.wav'" > wav_list.txt
for f in part_*.wav; do
echo "file '$PWD/$f'" >> wav_list.txt
done
ffmpeg -f concat -safe 0 -i wav_list.txt -c:a libmp3lame -q:a 2 podcast_meister-security.mp3
rm wav_list.txtAnwendungsregeln und ethische Bedenken
Die Entwickler haben klare Richtlinien für die Nutzung definiert. So sollte die Länge des Eingabetextes moderat sein (nicht unter 5 und nicht über 20 Sekunden Sprachausgabe), und die Sprecher-Tags müssen stets alternierend verwendet werden.
Besonders wichtig ist der ethische Disclaimer. Die Nutzung des Modells ist für folgende Zwecke strikt untersagt:
- Identitätsmissbrauch: Die Erzeugung von Audio, das echten Personen ähnelt, ohne deren explizite Erlaubnis.
- Täuschende Inhalte: Die Erstellung von irreführenden Inhalten wie Fake News oder Deepfakes.
- Illegale oder böswillige Nutzung: Jegliche Verwendung, die gegen Gesetze verstößt oder darauf abzielt, Schaden anzurichten.
Diese klaren Grenzen sind in einer Zeit, in der KI-generierte Inhalte immer realistischer werden, ein notwendiger und verantwortungsvoller Schritt. Ich denke, die meisten meiner Leser haben bereits davon gehört, dass Eltern von ihren vermeintlichen
Kindern zum Überweisen von Geld aufgefordert wurden. Die Eltern konnten wegen der schlechten Tonqualität auf ihrer Mailbox den Unterschied nicht sofort erkennen und sind auf den Betrug hereingefallen, da man den Stimmen heute auch Emotionen mitgeben kann.
Fazit
Dia ist ein technologisch beeindruckendes und hochpotentes Werkzeug für die Erzeugung künstlicher Dialoge. Die Open-Source-Natur und die vergleichsweise zugängliche Hardwareanforderung machen es für Entwickler, Forscher und Content-Ersteller äußerst attraktiv. Die Betonung der ethischen Verantwortung durch die Entwickler ist dabei ebenso lobenswert wie die technische Umsetzung selbst.