Consistent AI Voice Generation with ComfyUI
How to solve AI voice inconsistency in long audio using a clever ComfyUI and scripting.

This article demonstrates how to create a robust pipeline for generating high-quality, long-form audio content using a combination of powerful AI tools. By orchestrating ComfyUI, the VibeVoice TTS model, and a local LLM via a clever script, the common problem of voice degradation over longer texts is elegantly solved. This approach enables the automated production of consistent and natural-sounding audio, such as podcasts or article readings, directly from a web URL.
The Digital Sound Studio: Key Components
To build this automated audio generation pipeline, a few specialized tools are required, each playing a crucial role in the overall process.
- ComfyUI: This is a node-based graphical user interface for advanced AI model workflows, that I covered in an earlier article. Instead of linear scripts, ComfyUI allows for the creation of complex processing graphs, offering immense flexibility. It serves as the core engine for our text-to-speech generation.
- VibeVoice TTS: A powerful custom node for ComfyUI designed for high-quality text-to-speech and voice cloning. Its standout feature is the ability to use short audio clips as a reference to generate speech in that specific voice. This is the “voice actor” in our digital studio.
- Ollama: A framework for running large language models (LLMs) like Llama 3 or Mistral locally. By keeping the “creative brain” on a local machine, reliance on cloud-based APIs is eliminated, ensuring privacy and cost control. Ollama’s role is to act as a scriptwriter, transforming raw text into an engaging dialogue.
- FFmpeg, curl, and jq: These are the essential command-line utilities that act as the “glue” for the entire system.
curlhandles communication with web pages and APIs,jqis a master at parsing and manipulating the JSON data used by these APIs, andffmpegis the industry standard for processing and combining the final audio files.

The Problem: Vocal Drift in Long Monologues
A significant challenge with many TTS models, including very advanced ones, is maintaining vocal consistency over long passages of text. When fed a large block of text, the model’s vocal characteristics can begin to “drift.” The intonation might change, the pacing can become unnatural, or the core qualities of the cloned voice can degrade. It is akin to an actor who starts a scene with a specific accent but slowly loses it over the course of a long monologue. This inconsistency can be jarring to the listener and immediately signals the content as artificially generated.
The first 17 seconds closely match my original voice, but after the 1:45 mark, the resemblance drops off significantly.
The Solution
The key to overcoming vocal drift is a classic “divide and conquer” strategy. Instead of feeding the entire script to the TTS model at once, the text is broken down into individual sentences or short lines of dialogue. Each sentence is then processed independently. This forces the model to re-apply the original voice characteristics fresh for each segment, completely preventing the cumulative error that leads to drift. While performing this process manually would be incredibly tedious, it is a perfect task for automation via a shell script.
Crafting the ComfyUI Workflow
The foundation of the process is a carefully constructed ComfyUI workflow. This workflow is designed to accept text and generate audio using two distinct speaker voices.
The visual layout of the workflow is straightforward:
- Two
LoadAudioNodes: Each node is configured to load an MP3 or WAV file containing a voice sample. One file for “Sara” (sara.mp3) and one for “Michael” (michael.mp3). These serve as the voice clones. - One
VibeVoiceTTSNode: This is the central processing unit. It receives the two voice samples as inputs forspeaker_1_voiceandspeaker_2_voice. It also has a large text field where the script will inject the dialogue, one line at a time. The node is configured to use a model likeVibeVoice-Large. The trick is to format the text input to assign a speaker, for example:Speaker 2: This is the text Michael should say. - One
SaveAudioNode: This node takes the audio output from theVibeVoiceTTSnode and saves it as a FLAC file on the server running ComfyUI.
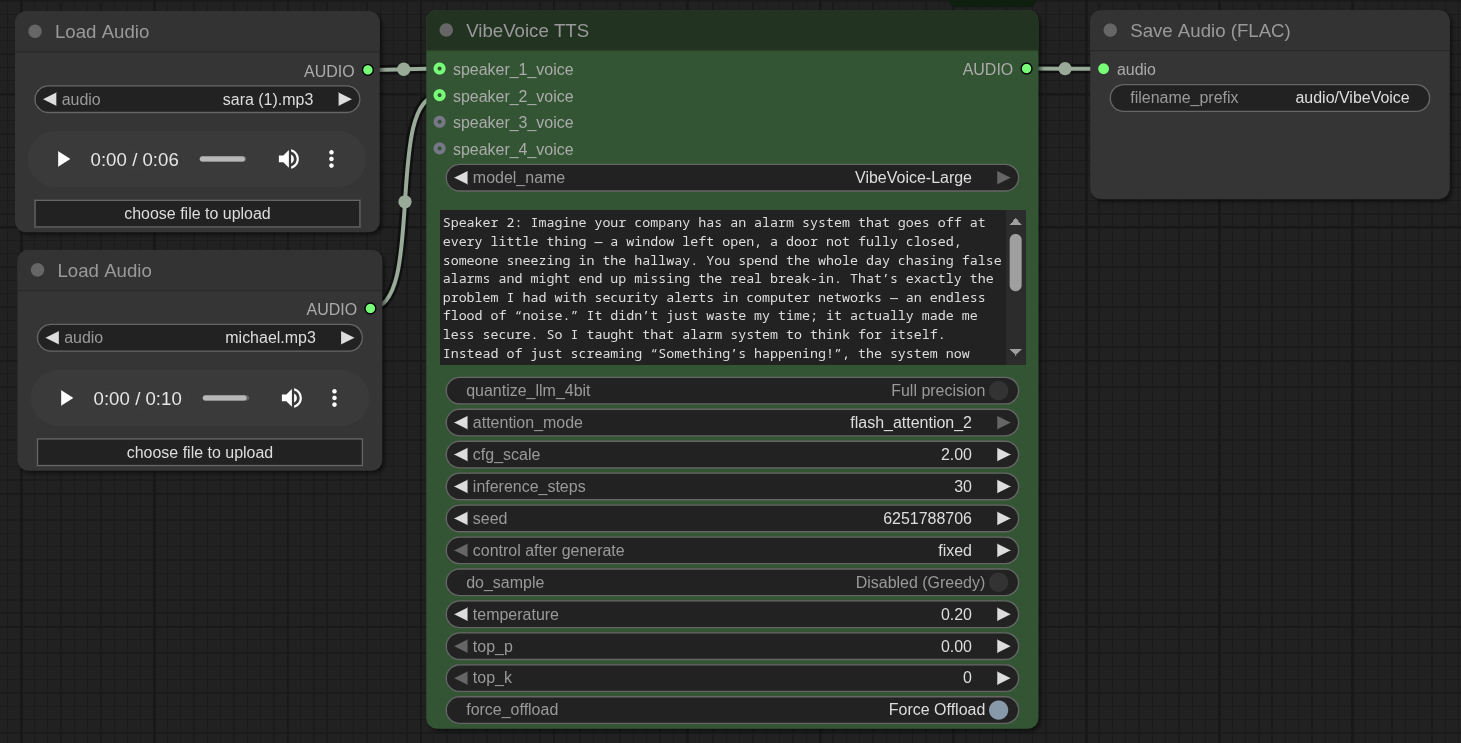
The entire workflow can be represented by the following JSON, which can be loaded directly into ComfyUI. To interact with this workflow via a script, it’s crucial to identify the node ID of the VibeVoiceTTS block (in this case, "11") and the SaveAudio block (here, "3").
{
"id": "b91265e5-1b03-4b63-8dc3-4abd9a030e08",
"revision": 0,
"last_node_id": 15,
"last_link_id": 34,
"nodes": [
{
"id": 4,
"type": "LoadAudio",
"pos": [-1903,-1131],
"size": [274,136],
"flags": {},
"order": 0,
"mode": 0,
"outputs": [{"name": "AUDIO", "type": "AUDIO", "links": [30]}],
"properties": {"Node name for S&R": "LoadAudio"},
"widgets_values": ["sara.mp3"]
},
{
"id": 3,
"type": "SaveAudio",
"pos": [-1096,-1132],
"size": [270,112],
"flags": {},
"order": 3,
"mode": 0,
"inputs": [{"name": "audio", "type": "AUDIO", "link": 27}],
"properties": {"Node name for S&R": "SaveAudio"},
"widgets_values": ["audio/VibeVoice"]
},
{
"id": 11,
"type": "VibeVoiceTTS",
"pos": [-1595,-1132],
"size": [460,510],
"flags": {},
"order": 2,
"mode": 0,
"inputs": [
{"name": "speaker_1_voice", "type": "AUDIO", "link": 30},
{"name": "speaker_2_voice", "type": "AUDIO", "link": 34}
],
"outputs": [{"name": "AUDIO", "type": "AUDIO", "links": [27]}],
"properties": {"Node name for S&R": "VibeVoiceTTS"},
"widgets_values": [
"VibeVoice-Large",
"Speaker 2: This is a placeholder text.",
false, "flash_attention_2", 2, 30, 6251788706, "fixed", false, 0.2, 0, 0, true
]
},
{
"id": 14,
"type": "LoadAudio",
"pos": [-1902,-952],
"size": [274,136],
"flags": {},
"order": 1,
"mode": 0,
"outputs": [{"name": "AUDIO", "type": "AUDIO", "links": [34]}],
"properties": {"Node name for S&R": "LoadAudio"},
"widgets_values": ["michael.mp3"]
}
],
"links": [
[27, 11, 0, 3, 0, "AUDIO"],
[30, 4, 0, 11, 0, "AUDIO"],
[34, 14, 0, 11, 1, "AUDIO"]
],
"groups": [], "config": {}, "extra": {}, "version": 0.4
}The Automation Script
With the ComfyUI stage set, a Bash script takes on the role of the conductor, orchestrating every part of the performance. This is the power, I was covering in my previous article about this tool.
- Content Acquisition & Scriptwriting: The script begins by fetching the content of a webpage using
curl. This content is then passed to a local Ollama instance with a carefully crafted prompt, instructing it to generate a two-person interview script based on the webpage. - Interacting with the ComfyUI API: The script processes the generated transcript sentence by sentence. For each sentence, it dynamically modifies a local copy of the ComfyUI workflow JSON using
jq. It injects the current line of dialogue into the text field of theVibeVoiceTTSnode ("11"). - Queueing and Monitoring: The modified JSON payload is sent to the ComfyUI
/promptAPI endpoint. ComfyUI begins processing and provides aprompt_id. The script then polls the/history/{prompt_id}endpoint, waiting until the audio generation for that sentence is complete. - Downloading and Assembling: Once a segment is ready, the script extracts the filename from the API response and downloads the resulting
.flacfile. This process repeats for every line in the transcript. Finally,ffmpegis used to seamlessly concatenate all the individual audio snippets into a single, polished MP3 file.
The Complete Script in Action
The following script puts all these pieces together. It requires curl, jq, and ffmpeg to be installed. The ComfyUI workflow JSON should be saved as workflow.json in the same directory.
#!/bin/bash
# M. Meister - AI Podcast Generation Script (pure bash version)
#
# Creates exactly one sentence per line prefixed with "Speaker X:"
# and converts each sentence into audio individually.
# --- Configuration ---
COMFYUI_URL="http://aiav:8188"
OLLAMA_URL="http://ai:11434"
TARGET_URL="https://blog.meister-security.de/2024/05/20/next-level-troubleshooting/"
OLLAMA_MODEL="gpt-oss:20b"
WORKFLOW_TEMPLATE="MM_TTS.json"
FINAL_MP3_FILE="podcast_output.mp3"
echo "### Step 1: Fetching web content..."
CONTENT=$(curl -s "$TARGET_URL" | sed -n '/<main/,/<\/main>/p' | sed 's/<[^>]*>//g' | jq -sR .)
if [ -z "$CONTENT" ]; then
echo "Error: Failed to fetch or process content from $TARGET_URL"
exit 1
fi
echo "### Step 2: Generating interview script with Ollama (sentence-per-line mode)..."
PROMPT="Based on the following text, create a two-person interview script between 'Speaker 1' (the moderator "Sara") and 'Speaker 2' (the expert "Matthias"). \
Each line must contain exactly one sentence, and every line must begin with 'Speaker 1:' or 'Speaker 2:'. \
Do not add any commentary or extra text. Output only the dialogue lines, one sentence per line. \
Text: $CONTENT"
OLLAMA_PAYLOAD=$(jq -n --arg model "$OLLAMA_MODEL" --arg prompt "$PROMPT" \
'{model: $model, prompt: $prompt, stream: false}')
TRANSCRIPT=$(curl -s -X POST "$OLLAMA_URL/api/generate" -d "$OLLAMA_PAYLOAD" | jq -r '.response')
if [ -z "$TRANSCRIPT" ]; then
echo "Error: Failed to generate transcript from Ollama."
exit 1
fi
echo "### Step 2.5: Normalizing to exactly one sentence per line (bash fallback)..."
# Removes empty lines and splits multi-sentence lines into individual sentences
SENTENCE_LINES=$(echo "$TRANSCRIPT" \
| tr -d '\r' \
| sed '/^[[:space:]]*$/d' \
| awk '
{
# Each line may contain multiple sentences -> split at .?!… followed by a space
line=$0
speaker=""
if (match(line, /^(Speaker[[:space:]]*[0-9][[:space:]]*[:\-])/, m)) {
speaker=m[1]
sub(/^(Speaker[[:space:]]*[0-9][[:space:]]*[:\-])/, "", line)
} else {
speaker="Speaker 1:"
}
n=split(line, parts, /[.!?…][[:space:]]+/)
for (i=1; i<=n; i++) {
s=parts[i]
gsub(/^[[:space:]]+|[[:space:]]+$/, "", s)
if (s != "") {
last_char=substr(s, length(s), 1)
if (last_char !~ /[.!?…]/) s=s"."
print speaker " " s
}
}
}')
if [ -z "$SENTENCE_LINES" ]; then
echo "Error: No valid sentences after normalization."
exit 1
fi
echo "### Step 3: Generating audio sentence by sentence..."
TEMP_DIR=$(mktemp -d)
FILE_LIST="$TEMP_DIR/files.txt"
CLIENT_ID=$(uuidgen)
i=0
while IFS= read -r line; do
[ -z "$line" ] && continue
((i++))
echo " - Processing sentence $i: ${line:0:60}..."
# Inject current line into workflow JSON
API_PAYLOAD=$(jq --arg text "$line" '.["11"].widgets_values[1] = $text' "$WORKFLOW_TEMPLATE")
# Submit to ComfyUI
QUEUE_RESPONSE=$(curl -s -X POST -H "Content-Type: application/json" "$COMFYUI_URL/prompt" \
-d "{\"prompt\": $API_PAYLOAD, \"client_id\": \"$CLIENT_ID\"}")
PROMPT_ID=$(echo "$QUEUE_RESPONSE" | jq -r '.prompt_id')
if [ "$PROMPT_ID" == "null" ] || [ -z "$PROMPT_ID" ]; then
echo "Error: Failed to queue prompt in ComfyUI. Response: $QUEUE_RESPONSE"
continue
fi
# Wait until the generation job is finished
while true; do
HISTORY_RESPONSE=$(curl -s "$COMFYUI_URL/history/$PROMPT_ID")
if echo "$HISTORY_RESPONSE" | jq -e ".\"$PROMPT_ID\"" >/dev/null 2>&1; then
break
fi
sleep 1
done
# Extract audio file information and download it
FILENAME=$(echo "$HISTORY_RESPONSE" | jq -r ".\"$PROMPT_ID\".outputs[\"3\"].audios[0].filename")
SUBFOLDER=$(echo "$HISTORY_RESPONSE" | jq -r ".\"$PROMPT_ID\".outputs[\"3\"].audios[0].subfolder")
if [ -z "$FILENAME" ] || [ "$FILENAME" == "null" ]; then
echo "Warning: No audio file for $PROMPT_ID"
continue
fi
DOWNLOAD_URL="$COMFYUI_URL/view?filename=$FILENAME&subfolder=$SUBFOLDER&type=output"
curl -s -o "$TEMP_DIR/$FILENAME" "$DOWNLOAD_URL"
echo "file '$TEMP_DIR/$FILENAME'" >> "$FILE_LIST"
done <<< "$SENTENCE_LINES"
echo "### Step 4: Assembling the final audio file..."
ffmpeg -f concat -safe 0 -i "$FILE_LIST" -c:a libmp3lame -q:a 2 "$FINAL_MP3_FILE" -y
echo "### Done! Podcast saved as $FINAL_MP3_FILE"
rm -rf "$TEMP_DIR"
From now on, every sentence remains consistent while still reflecting natural dynamics — such as the emphasis and energy conveyed by exclamation marks.
Conclusion
By breaking down a long text into individual sentences and automating the generation process, the issue of vocal drift in AI-powered TTS is effectively eliminated. This modular pipeline — combining the flexibility of ComfyUI, the vocal quality of VibeVoice, and the local intelligence of Ollama — delivers consistently high-quality audio, even when a voice is predefined by an existing audio file. This method transforms the creation of long-form audio content from a complex challenge into a streamlined, automated workflow.