Webseiten beobachten
Change Detection und Headless Chrome mit Docker Compose: Container-Konfiguration, Umgebungsvariablen und Persistenzoptionen für effizientes Web-Scraping.


In meiner Arbeit nutze ich oft automatisierte Tools, um verschiedene Aufgaben effizienter zu gestalten. Kürzlich habe ich ein interessantes Projekt abgeschlossen, bei dem ich Change Detection zusammen mit einem Headless Chrome Browser in einer Docker-Umgebung verwendet habe, um Webseiten zu überwachen. Hier möchte ich gerne zeigen, wie ich dabei vorgegangen bin.
Warum Change Detection?
In vielen Fällen ist es hilfreich, Änderungen auf Webseiten automatisch zu erkennen und darauf zu reagieren. Sei es, um Preisänderungen zu verfolgen, Firmware-Updates zu monitoren oder einfach nur um zu sehen, wann ein Produkt wieder auf Lager ist. Change Detection ist dafür das perfekte Werkzeug, da es auch Screenshots der beobachteten Webseiten anfertigen kann.
Docker Setup
Um Change Detection mit einem Headless Chrome Browser in einer Docker-Umgebung zu betreiben, ist eine sorgfältige Konfiguration der Komponenten notwendig. Das folgende Setup nutzt wie immer Docker Compose, um die verschiedenen Services zu orchestrieren. Dies stellt sicher, dass sowohl Change Detection als auch der Playwright-basierte Headless Chrome reibungslos zusammenarbeiten.
Installation der erforderlichen Software
Docker Installation:
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
Docker Compose Installation:
sudo curl -L "https://github.com/docker/compose/releases/download/v2.11.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
Erstellen der docker-compose.yml
Sobald Docker und Docker Compose installiert sind, lege ich eine docker-compose.yml-Datei an, um die Services zu definieren, die für den Betrieb von Change Detection und Playwright Chrome erforderlich sind.
version: '3.8'
services:
changedetection:
image: ghcr.io/dgtlmoon/changedetection.io:latest
container_name: changedetection
hostname: changedetection
volumes:
- ./data/datastore:/datastore
ports:
- "5000:5000"
environment:
- PLAYWRIGHT_DRIVER_URL=ws://playwright-chrome:3000
depends_on:
playwright-chrome:
condition: service_started
restart: unless-stopped
playwright-chrome:
hostname: playwright-chrome
image: browserless/chrome
restart: unless-stopped
environment:
- SCREEN_WIDTH=1920
- SCREEN_HEIGHT=1024
- SCREEN_DEPTH=16
- ENABLE_DEBUGGER=false
- PREBOOT_CHROME=true
- CONNECTION_TIMEOUT=300000
- MAX_CONCURRENT_SESSIONS=10
- CHROME_REFRESH_TIME=600000
- DEFAULT_BLOCK_ADS=true
- DEFAULT_STEALTH=true
- DEFAULT_IGNORE_HTTPS_ERRORS=true
Erläuterung der docker-compose.yml
changedetection:
- Image: Das offizielle Image von
changedetection.iowird von GitHub Container Registry (ghcr.io) geladen. - Container Name und Hostname: Beide sind auf
changedetectiongesetzt, um die Identifizierung zu erleichtern. - Volumes: Die Daten des Services werden im lokalen Verzeichnis
./changedetection/datastoregespeichert, um Persistenz auch bei Container-Neustarts zu gewährleisten. - Ports: Der Service ist auf Port 5000 verfügbar.
- Environment: Die Umgebungsvariable
PLAYWRIGHT_DRIVER_URList so konfiguriert, dass sie den Playwright Chrome Container anspricht, um eine WebSocket-Verbindung auf Port 3000 zu ermöglichen. - depends_on: Der
changedetection-Service wird erst gestartet, nachdem sichergestellt wurde, dass derplaywright-chrome-Service bereits läuft. - Restart Policy: Der Container wird neu gestartet, falls er unerwartet stoppt (
unless-stopped).
playwright-chrome:
- Image: Hier wird das Image
browserless/chromeverwendet, das eine vorkonfigurierte, leichtgewichtige Chrome-Instanz bereitstellt. - Environment: Eine Reihe von Umgebungsvariablen wurde definiert, um die Chrome-Instanz optimal für das Scraping einzurichten:
- Bildschirmauflösung (
SCREEN_WIDTH,SCREEN_HEIGHT,SCREEN_DEPTH) ist für eine breite Kompatibilität eingestellt. PREBOOT_CHROMEsorgt dafür, dass Chrome sofort nach dem Start des Containers verfügbar ist, was die Wartezeiten verkürzt.MAX_CONCURRENT_SESSIONSbegrenzt die Anzahl der gleichzeitigen Sessions auf 10.DEFAULT_BLOCK_ADSundDEFAULT_STEALTHaktivieren das Blockieren von Anzeigen und die Nutzung eines Stealth-Modus, um Erkennung durch Antibot-Maßnahmen zu vermeiden.DEFAULT_IGNORE_HTTPS_ERRORSignoriert SSL-Fehler, was insbesondere bei selbstsignierten Zertifikaten nützlich ist.- Restart Policy: Wie bei
changedetectionwird auch hier der Container neu gestartet, falls er unerwartet beendet wird.
Starten der Docker-Umgebung
Nachdem die docker-compose.yml erstellt wurde, kann man die gesamte Umgebung mit folgendem Befehl starten:
docker-compose up -d && docker-compose logs -f
Mit diesem Befehl werden die Images heruntergeladen und die Container im Hintergrund (-d für "detached mode") gestartet. Um sicherzustellen, dass alles korrekt läuft, überprüft man die Container mit:
docker-compose ps
Hiermit kann man den Status der Container einsehen und sicherstellen, dass sowohl changedetection als auch playwright-chrome ordnungsgemäß laufen.
Change Detection konfigurieren
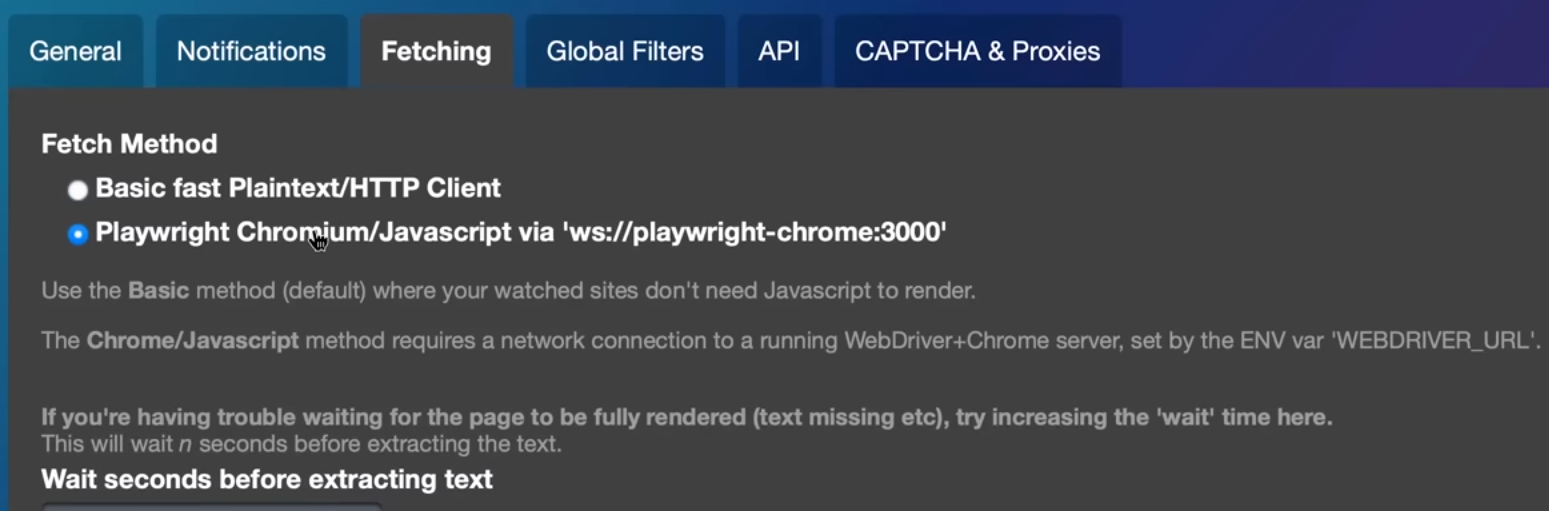
Jetzt, da die Umgebung läuft, war es an der Zeit, Change Detection so zu konfigurieren, dass es den Headless Browser verwendet. Dazu ging ich in die Settings von Change Detection und änderte die Fetch Method auf Headless Chrome. Dies ermöglichte es mir, die Webseiten vollständig zu rendern und ihre Inhalte zu erfassen, einschließlich derjenigen, die erst durch JavaScript sichtbar gemacht werden.
Praktische Anwendungsfälle
Ein paar Beispiele, wie ich diese Umgebung genutzt habe:
Firmware-Updates verfolgen: Ich habe Change Detection so konfiguriert, dass es die Webseiten von Hardware-Herstellern überwacht und mich benachrichtigt, sobald neue Firmware verfügbar ist. Hierzu habe ich die URLs der entsprechenden Downloadseiten hinzugefügt und Change Detection den Rest überlassen.
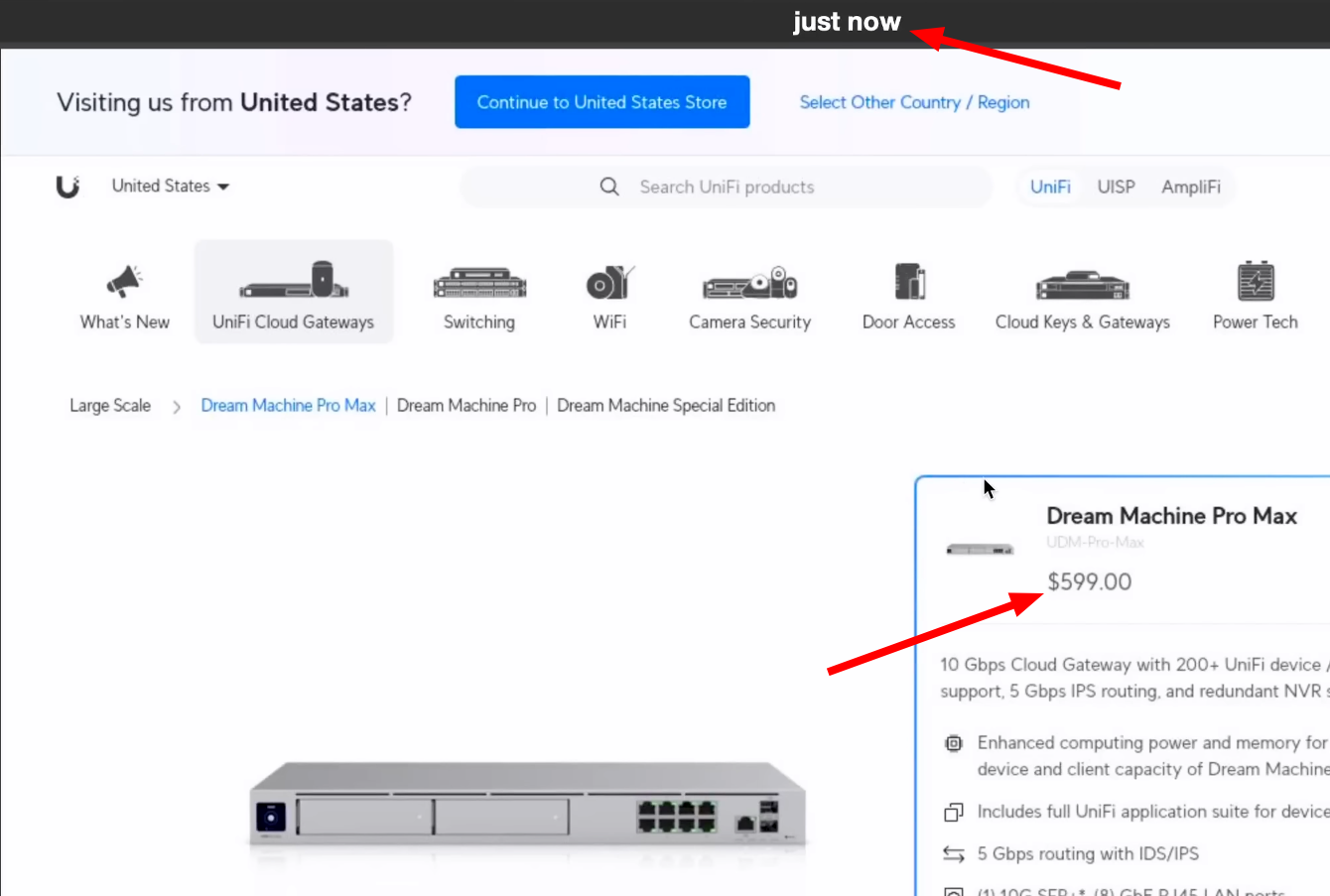
Preise überwachen: Mit dieser Methode habe ich auch Preise von Produkten auf Online-Shops überwacht. Change Detection kann sogar in JSON-Responses eingebettete Preisinformationen erkennen, was es besonders effizient macht.

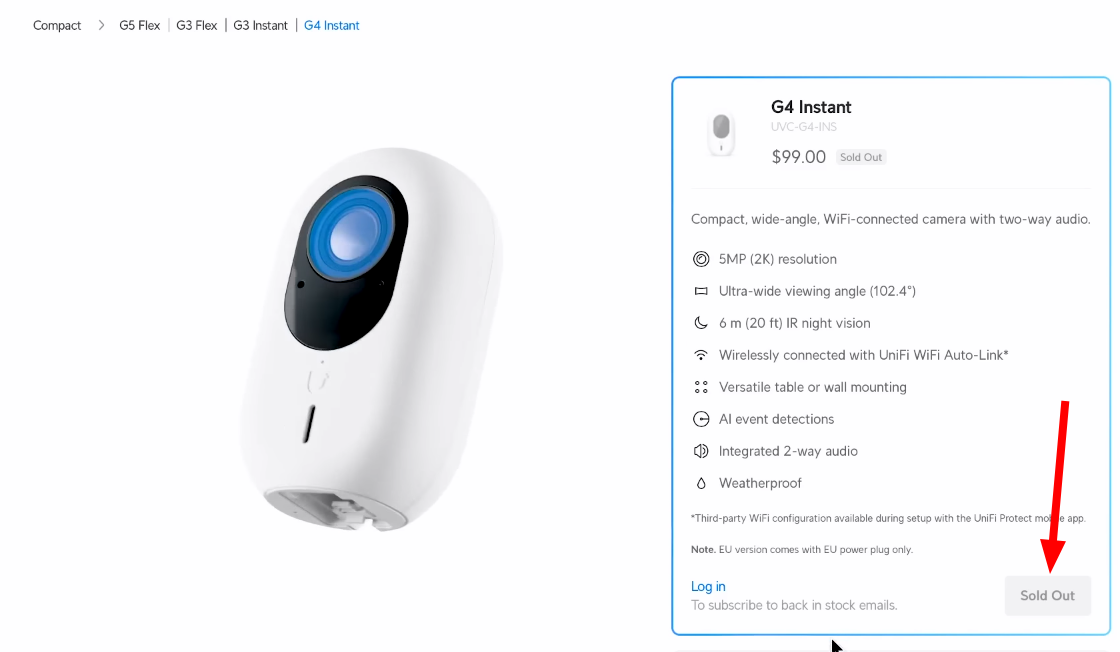
Restock-Benachrichtigungen: Ein weiteres praktisches Szenario ist das Überwachen von Produkten, die derzeit nicht auf Lager sind. Sobald sie wieder verfügbar sind, werde ich sofort benachrichtigt.



Fazit
Die Kombination aus Change Detection und einem Headless Browser eröffnet viele Möglichkeiten für automatisiertes Web Scraping und Monitoring. Besonders in sicherheitsrelevanten Bereichen, in denen ich arbeite, ist diese Automatisierung äußerst nützlich, um stets auf dem neuesten Stand zu bleiben und schnell auf Änderungen in der ZeroDayInitiative und bekannt gewordenen CVEs reagieren zu können.