Automatische Wissens-Updates in Open-WebUI
So wird die Open WebUI Knowledge Base automatisch mit dem lokalen Dateisystem synchronisiert


In Teil 2 der Reihe um Nextcloud und KI soll es um die Anbindung einer privaten Wissensdatenbank gehen. Ein lokal gehostetes Sprachmodell ist eine feine Sache, doch ohne Zugriff auf eigene Dateien glänzt die KI oft nur mit gefährlichem Halbwissen. Wer jedoch nicht für jede Anfrage mühsam PDF-Dokumente in den Chat ziehen will, braucht eine zuverlässige Automatisierung. Genau hier hakt das offizielle Tool OIKB (Open WebUI Knowledge Base) ein und schaufelt lokale Dokumenten-Ordner im Hintergrund stur in die Wissensdatenbank der KI.
Das Problem mit dem Inselwissen
Ein lokales Setup mit Open WebUI, wie etwa in Run Uncensored AI Selfhosted gezeigt, legt den Grundstein für einen strikt privaten Assistenten. Das Modell kennt zwar das geballte Internetwissen bis zu seinem Trainingsdatum, hat aber logischerweise keinen blassen Schimmer von lokalen Rechnungen, Verträgen oder der akribisch gepflegten IT-Dokumentation auf dem heimischen NAS.

Open WebUI bietet zwar sogenannte Knowledge Bases an, um dem Modell dieses Wissen einzuimpfen, doch der manuelle Upload ist ein echter Produktivitätskiller. Sobald der Dokumentenscanner ein neues PDF im Netzwerkordner ablegt, ist die KI schon wieder veraltet. Ein ständiges händisches Nachpflegen ist im Alltag schlicht nicht praktikabel.
Der automatische Synchronisator für Dokumente
Um nicht ständig den Babysitter für die Wissensdatenbank spielen zu müssen, bietet sich oikb an. Dieser schlanke Hintergrunddienst (Daemon) klemmt sich an definierte Quellen – egal ob lokale Verzeichnisse, GitHub-Repositories oder S3-Buckets – und synchronisiert diese nach einem festen Zeitplan über die API mit Open WebUI.
Ein pfiffiger Nebeneffekt: Dank inkrementellem SHA-256-Abgleich wandern wirklich nur neue oder veränderte Dateien über den Draht. Das schont die Systemressourcen und hält die KI völlig unbemerkt stets auf dem exakten Stand des angebundenen Verzeichnisses.
Nahtlose Docker-Integration mit Stolperfalle
Da Open WebUI meist ohnehin als Docker-Container schnurrt, packt man den OIKB-Daemon am besten direkt als weiteren Service in die bestehende docker-compose.yml. Dabei gibt es zwei Dinge zu beachten: Die Kommunikation sollte tunlichst über das interne Docker-Netzwerk laufen, um unnötige Umwege über den Host zu vermeiden.
Außerdem versteckt sich in aktuellen OIKB-Versionen ein fieser kleiner Bug: Das Docker-Image erwartet die Konfigurationsdatei .oikb.yaml zwingend im Verzeichnis /data und nicht mehr unter /app. Nutzt man den alten Pfad, wirft der Container direkt beim Start frustriert ein „No sync entries found. Create a .oikb.yaml file.“ ins Log und beendet sich.
Eine funktionierende und saubere Erweiterung der bestehenden Umgebung sieht folgendermaßen aus:
# M. Meister - OIKB Docker Compose Extension
services:
# ... (bestehender open-webui Service) ...
oikb:
image: ghcr.io/open-webui/oikb:latest
container_name: oikb
environment:
# Interne Kommunikation über den Service-Namen "open-webui"
- OPEN_WEBUI_URL=http://open-webui:8080
# API-Key aus den Open WebUI Konto-Einstellungen
- OPEN_WEBUI_API_KEY=sk-1234567890abcdef
# Frei wählbarer, sicherer Key für den OIKB Daemon
- OIKB_API_KEY=ein_sehr_sicheres_passwort
- LOG_FORMAT=json
volumes:
# Wichtig: Die Konfiguration MUSS auf /data/.oikb.yaml gemappt werden
- ./oikb/.oikb.yaml:/data/.oikb.yaml:ro
# Das DMS-Verzeichnis des Hosts wird exakt spiegelbildlich und Read-Only gemountet
- /pfad/zum/lokalen/dms:/pfad/zum/lokalen/dms:ro
command: daemon
ports:
# Port-Mapping zur Host-Maschine
- "8081:8080"
depends_on:
- open-webui
restart: unless-stoppedEin entscheidendes Detail: Der Mount des Host-Verzeichnisses (hier anonymisiert als /pfad/zum/lokalen/dms) in den Container ist zwingend erforderlich. Ein Docker-Container läuft isoliert und sieht das Dateisystem des Hosts nativ nicht. Die Option :ro (Read-Only) garantiert am Ende des Mappings, dass das Tool die Originaldaten unter keinen Umständen verändern oder löschen kann.
Dem Daemon den Weg weisen
Damit OIKB überhaupt weiß, welche Verzeichnisse in welcher Wissensdatenbank landen sollen, braucht es die erwähnte Datei .oikb.yaml. Diese wird passend zum Volume-Mount auf dem Host-System im Ordner ./oikb angelegt.

Zuvor muss allerdings in der Weboberfläche von Open WebUI eine frische Knowledge Base erstellt werden. Ein Blick in den rechten Bereich des Browsers verrät dabei das fehlende Puzzleteil: Eine ID im Format 12345678-abcd-efgh-ijkl-1234567890ab ist genau die benötigte kb-id.
Die Syntax der Konfiguration bleibt angenehm übersichtlich:
# M. Meister - OIKB Configuration
# Globale Defaults für alle Sync-Jobs
defaults:
interval: 1h # Stündlicher Abgleich aller definierten Quellen
concurrency: 4 # Parallele Verarbeitung beschleunigt den Upload
sources:
- name: Lokale_Dokumente
# Dieser Pfad muss exakt dem Volume-Mapping im Docker-Container entsprechen
source: /pfad/zum/lokalen/dms
kb-id: 12345678-abcd-efgh-ijkl-1234567890ab
- name: Chats
# siehe https://blog.meister-security.de/script-time-signal-chat-bot-teil-2/
source: /pfad/zum/signal/chats
kb-id: 12345678-abcd-efgh-ijkl-1234567890acDokumentenscanner anbinden
Ja. Ich gebe es zu. Ich habe sehr preiswert gekauft. Deshalb hat mein Scanner kein eingebautes OCR. Mein LXC-Container beobachtet daher das Verzeichnis (inbox), in welchem der Scanner seine PDF-Dokumente ablegt. Dann erledige ich die Texterkennung schnell selbst. Das schlägt natürlich bei handgeschriebenen Dokumenten fehl. Deshalb lasse ich meine KI nochmals einen Blick darauf werfen. Sie klassifiziert das Dokument, benennt die Datei um, und erstellt unter gleichem Namen eine Markdown-Version des PDF-Dokuments, welche sich deutlich leichter durchsuchen lässt als ein PDF. Das OCR-PDF kommt dann ins Archiv und das Markdownfile in das Verzeichnis, das oikb überwacht. So muss ich mich nicht mehr um meine Dokumente kümmern (wie z.B. bei Paperless-NGX/AI/GPT).
#!/bin/bash
# ------------------------------------------------------------------
# PDF-Watcher mit OCR und KI-gestützter Dokumentenaufbereitung
#
# Workflow:
# 1. Überwacht ein Eingangsverzeichnis auf neue PDFs
# 2. Erstellt ein OCR-PDF/A
# 3. Wandelt PDF-Seiten in Bilder um
# 4. Lässt ein Vision-Modell Markdown erzeugen
# 5. Extrahiert Metadaten per LLM
# 6. Benennt PDF und Markdown automatisch
# ------------------------------------------------------------------
AI_MODEL="vision-model:latest"
ALLOWED_TAGS="rechnung, vertrag, versicherung, steuer, bank, haus, fahrzeug"
# Verzeichnisse
WATCH_DIR="/data/documents/inbox"
MARKDOWN_DIR="/data/documents/markdown"
ARCHIVE_DIR="/data/documents/archive"
mkdir -p "$MARKDOWN_DIR"
mkdir -p "$ARCHIVE_DIR"
inotifywait -m -e close_write --format "%w%f" "$WATCH_DIR" | while read NEW_FILE
do
if [[ "$NEW_FILE" == *.pdf && "$NEW_FILE" != *_ocr.pdf && "$NEW_FILE" != .* ]]; then
echo "==============================================================="
echo "Neue Datei erkannt: $NEW_FILE"
TMP_WORK_DIR=$(mktemp -d)
#################################################################
# 1. OCR erzeugen
#################################################################
TEMP_FILE="${NEW_FILE%.pdf}_ocr.pdf"
echo "Erstelle OCR-PDF..."
ocrmypdf \
--force-ocr \
-l deu+eng \
--rotate-pages \
--deskew \
--clean \
--output-type pdfa \
"$NEW_FILE" \
"$TEMP_FILE"
if [[ $? -eq 0 ]]; then
#################################################################
# 2. PDF -> JPG
#################################################################
echo "Konvertiere PDF-Seiten..."
pdftoppm -jpeg "$TEMP_FILE" "$TMP_WORK_DIR/page"
> "$TMP_WORK_DIR/b64_lines.txt"
for img in "$TMP_WORK_DIR"/page-*.jpg; do
if [[ -f "$img" ]]; then
base64 -w 0 "$img" >> "$TMP_WORK_DIR/b64_lines.txt"
echo "" >> "$TMP_WORK_DIR/b64_lines.txt"
fi
done
jq -R -s \
'split("\n") | map(select(length > 0))' \
"$TMP_WORK_DIR/b64_lines.txt" \
> "$TMP_WORK_DIR/images.json"
#################################################################
# 3. Vision-Modell -> Markdown
#################################################################
MD_PROMPT="Lies die angehängten Bilder und wandle sie in ein sauber strukturiertes Markdown-Dokument um. Gib ausschließlich Markdown zurück."
jq -n \
--arg model "$AI_MODEL" \
--arg prompt "$MD_PROMPT" \
'{
model:$model,
prompt:$prompt,
stream:false,
options:{
num_ctx:8192,
temperature:0.1
}
}' \
> "$TMP_WORK_DIR/payload_base.json"
jq \
--slurpfile imgs "$TMP_WORK_DIR/images.json" \
'.images=$imgs[0]' \
"$TMP_WORK_DIR/payload_base.json" \
> "$TMP_WORK_DIR/payload.json"
MD_CONTENT=$(
curl -s http://localhost:11434/api/generate \
-d @"$TMP_WORK_DIR/payload.json" \
| jq -r .response
)
#################################################################
# 4. Metadaten extrahieren
#################################################################
echo "$MD_CONTENT" > "$TMP_WORK_DIR/md_content.txt"
META_PROMPT="Analysiere folgendes Markdown.
Gib ausschließlich ein valides JSON mit folgenden Feldern zurück:
{
\"datum\": \"YYYYMMDD\",
\"beschreibung\": \"Kurze Beschreibung\",
\"tags\": []
}
Erlaubte Tags:
[${ALLOWED_TAGS}]"
jq -n \
--arg model "$AI_MODEL" \
--arg prompt_base "$META_PROMPT" \
--rawfile md_doc "$TMP_WORK_DIR/md_content.txt" \
'{
model:$model,
prompt:($prompt_base + "\n\n" + $md_doc),
stream:false,
format:"json",
options:{
num_ctx:8192,
temperature:0.1
}
}' \
> "$TMP_WORK_DIR/meta_payload.json"
META_RESPONSE=$(
curl -s http://localhost:11434/api/generate \
-d @"$TMP_WORK_DIR/meta_payload.json" \
| jq -r .response
)
#################################################################
# 5. Metadaten bereinigen
#################################################################
AI_DATE=$(echo "$META_RESPONSE" | jq -r '.datum // ""')
if [[ -z "$AI_DATE" || "$AI_DATE" == "null" ]]; then
AI_DATE=$(stat -c %y "$NEW_FILE" | awk '{gsub("[-:]","",$1); print $1}')
fi
RAW_DESC=$(echo "$META_RESPONSE" | jq -r '.beschreibung // "Dokument"')
DESC_CLEAN=$(
echo "$RAW_DESC" |
sed \
-e 's/ä/ae/g' \
-e 's/ö/oe/g' \
-e 's/ü/ue/g' \
-e 's/Ä/Ae/g' \
-e 's/Ö/Oe/g' \
-e 's/Ü/Ue/g' \
-e 's/ß/ss/g' \
-e 's/ /_/g' \
-e 's/[^a-zA-Z0-9_]//g'
)
TAGS_CLEAN=$(
echo "$META_RESPONSE" |
jq -r '(.tags // []) | join("_")' |
tr '[:upper:]' '[:lower:]' |
sed 's/[^a-z0-9_]//g'
)
#################################################################
# 6. Dateien speichern
#################################################################
if [[ -n "$TAGS_CLEAN" ]]; then
NEW_BASENAME="${AI_DATE}_${TAGS_CLEAN}-${DESC_CLEAN}"
else
NEW_BASENAME="${AI_DATE}-${DESC_CLEAN}"
fi
FINAL_PDF="${ARCHIVE_DIR}/${NEW_BASENAME}.pdf"
FINAL_MD="${MARKDOWN_DIR}/${NEW_BASENAME}.md"
echo "$MD_CONTENT" > "$FINAL_MD"
mv "$TEMP_FILE" "$FINAL_PDF"
rm "$NEW_FILE"
echo "Markdown gespeichert: $FINAL_MD"
echo "PDF archiviert: $FINAL_PDF"
else
echo "OCR fehlgeschlagen."
rm -f "$TEMP_FILE"
fi
rm -rf "$TMP_WORK_DIR"
echo "==============================================================="
fi
doneJetzt kann ich in Open-WebUI einfach fragen: "Gib mir alle steuerrelevanten Dokumente aus dem Jahr 2025. Sortiere sie nach folgenden Themen: Haushaltsnahe Dienstleistungen, Versicherungen, Telefonkosten, ...".
Zurücklehnen und profitieren
Sind alle Konfigurationen gespeichert, genügt ein beherztes docker compose up -d, um den Daemon loszulassen. Ein Kontrollblick in die Logs per docker logs -f oikb zeigt im Idealfall direkt, wie das Tool das Verzeichnis durchkämmt und die Dokumente indexiert.
Ab diesem Moment wandelt sich der Umgang mit der KI spürbar. Ein Dokument wird digitalisiert, landet im überwachten Netzwerkordner und spätestens nach Ablauf des eingestellten Intervalls hat OIKB die Daten vollautomatisch eingepflegt. Fragt man in Open-WebUI nun nach der Zusammenfassung eines kürzlich eingescannten Schreibens, antwortet es nicht nur präzise, sondern liefert gleich die passende Quellenangabe zum PDF mit – ganz ohne händisches Drag-and-Drop.
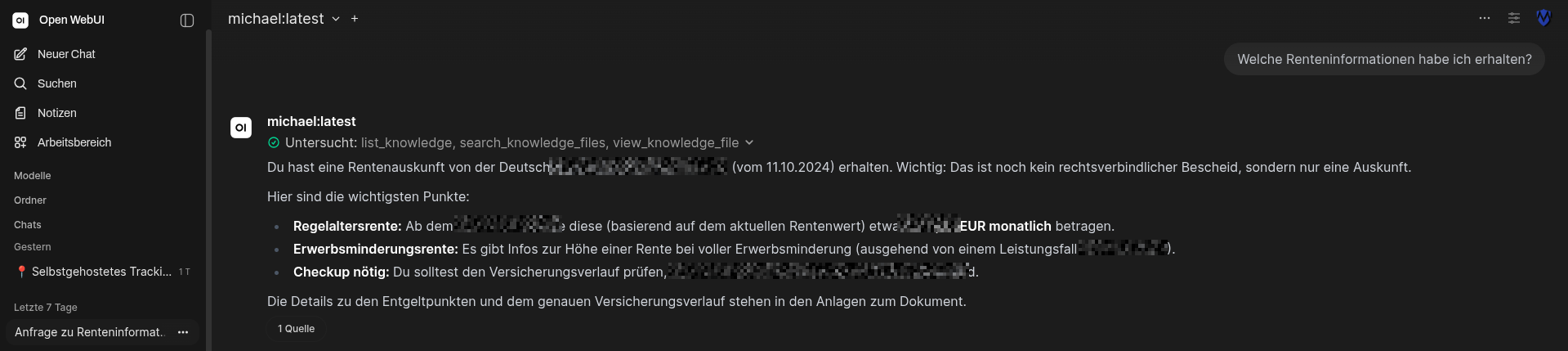
Absprachen im Blick behalten
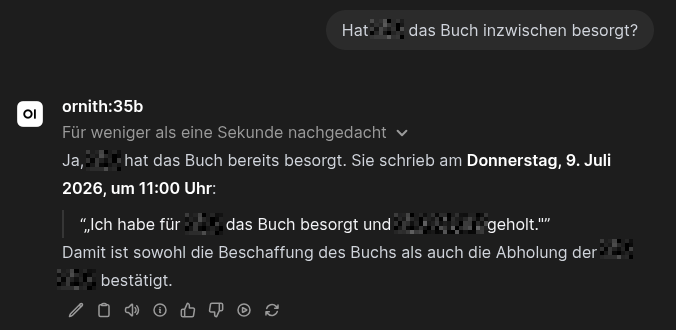
Wer genau hingeschaut hat, hat vielleicht bemerkt, dass ich auch meinen Signal-Chatverlauf der KI zur Analyse überlasse. So kann ich auch schnell nachfragen, mit wem ich über ein bestimmtes Thema gesprochen habe, und welche Meinungen wir dabei vertreten haben. Aber auch, ob noch Aufaben für mich zu erledigen sind:
Fazit
Die automatisierte Pflege von Wissensdatenbanken macht aus einem simplen Chatbot erst einen ernstzunehmenden, digitalen Assistenten. Mit einer sauberen Docker-Integration verrichtet der OIKB-Daemon völlig unauffällig seinen Dienst und erspart Administratoren lästige Handarbeit. Zusammen mit owuinc, integriert sich das Setup nahtlos in bestehende Workflows und sorgt für spürbar mehr Komfort im Umgang mit lokalen LLMs, wie wir im dritten Teil dieser Reihe noch sehen werden.