OpenAI-Modelle für alle: Der Praxistest
Mein erster Eindruck von OpenAIs GPT-OSS-Modellen im Detail.


Ein bemerkenswertes Ereignis hat die Welt der künstlichen Intelligenz in Aufruhr versetzt: OpenAI, das Unternehmen hinter den bekannten GPT-Modellen, hat erstmals seit GPT-2 wieder Open-Source-Modelle veröffentlicht. Unter der liberalen Apache-2.0-Lizenz stehen nun gpt-oss:120b und gpt-oss:20b zur Verfügung und versprechen, leistungsstarke KI für eine breitere Masse zugänglich zu machen. Dieser Artikel wirft einen ersten, detaillierten Blick auf die beiden Neulinge, unterzieht sie einigen praktischen Tests und klärt, ob sie das Potenzial haben, die lokale KI-Entwicklung zu revolutionieren.
OpenAI betritt erneut die Open-Source-Arena
Die Veröffentlichung von zwei Open-Weight-Modellen durch OpenAI ist ein bedeutender Schritt. Lange Zeit war das Unternehmen für seine geschlossenen, über APIs zugänglichen Modelle bekannt. Mit gpt-oss:120b und gpt-oss:20b ändert sich diese Strategie. Die Modelle sollen speziell für "agentic workflows" konzipiert sein, also für Aufgaben, bei denen die KI eigenständig komplexe, mehrstufige Prozesse durchführt. Dazu gehören herausragende Fähigkeiten im Befolgen von Anweisungen und in der Nutzung von Werkzeugen, wie etwa einer Websuche oder der Ausführung von Python-Code.
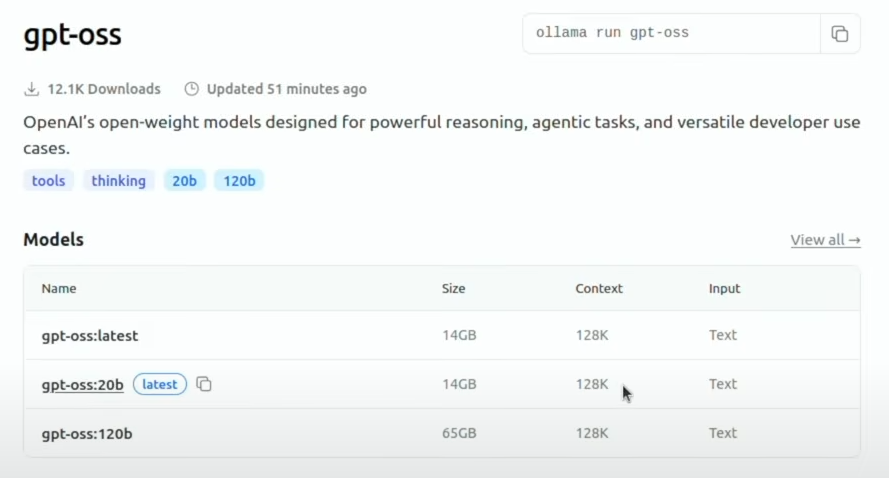
Die Kontrahenten: gpt-oss:120b vs. gpt-oss:20b
Die beiden Modelle zielen auf unterschiedliche Hardwareklassen ab, teilen sich aber eine moderne Architektur und eine beachtliche Kontextlänge von 128.000 Token.
- gpt-oss:120b: Das größere Modell mit 120 Milliarden Parametern soll eine Leistung nahe an der von GPT-4o mini erreichen und benötigt für einen effizienten Betrieb eine einzelne GPU mit 80 GB VRAM.
- gpt-oss:20b: Die kleinere Variante mit 20 Milliarden Parametern liefert eine Performance, die mit GPT-3.5 Turbo vergleichbar ist. Der Clou: Es läuft bereits auf Edge-Geräten mit nur 16 GB Arbeitsspeicher.
Beide Modelle basieren auf der Mixture of Experts (MoE) Architektur. Man kann sich das wie ein Expertengremium vorstellen: Statt eines einzigen, riesigen Gehirns, das jede Frage beantworten muss, gibt es ein Team von Spezialisten. Für jede Anfrage (jeden Token) wählt ein intelligenter Router nur die relevantesten Experten aus. Dadurch ist nur ein Bruchteil der Gesamtparameter – die "aktiven Parameter" – gleichzeitig im Einsatz. Dieses Design ermöglicht es, sehr große Modelle wie das 120B-Modell auf vergleichsweise handhabbarer Hardware auszuführen, da nicht das gesamte Modell in den Speicher geladen werden muss.
Installation mit Ollama
Die Inbetriebnahme der Modelle gestaltet sich erfreulich unkompliziert, insbesondere mit einem Werkzeug wie Ollama, das die Komplexität des Model-Managements elegant abstrahiert. OpenAI selbst stellt in einem Cookbook auf GitHub detaillierte Anleitungen bereit.
Die Installation erfolgt mit zwei einfachen Befehlen im Terminal:
1. Das 20-Milliarden-Parameter-Modell herunterladen:
ollama pull gpt-oss:20b
2. Das 120-Milliarden-Parameter-Modell herunterladen:
ollama pull gpt-oss:120b
Nach dem Download können die Modelle direkt im Terminal ausgeführt werden, beispielsweise mit:
ollama run gpt-oss:20b
Für eine komfortablere Interaktion empfiehlt sich ein Frontend wie Open WebUI, das sich nahtlos mit der Ollama-Instanz verbindet.
Das Testsystem: Eine (fast) antiquierte Kampfmaschine
Um die Performance der Modelle einschätzen zu können, kommt ein System zum Einsatz, das man liebevoll als "beefy workstation" bezeichnen könnte:
- CPU: AMD EPYC 7303P (32)
- RAM: 128 GB
- GPU: 1x NVIDIA GeForce RTX 3090
Obwohl nicht mehr das absolut Neueste vom Neuen, bietet dieses Setup ausreichend Leistung, um auch anspruchsvolle Modelle zu betreiben. Das 120b Modell lief bei mir daher nicht auf der Grafikkarte.
Test 1: Das Browser-Betriebssystem
Mein beliebter Test, um die Kreativität und die Programmierfähigkeiten eines Modells zu prüfen, ist die Aufforderung, ein kleines Betriebssystem zu erstellen, das vollständig in HTML, CSS und JavaScript im Browser läuft.
Der Prompt: Erstelle ein browserbasiertes Betriebssystem mit JavaScript, HTML und CSS.
Das 120B-Modell:
Das große Modell lieferte eine sehr ausführliche Antwort, inklusive einer Tabelle, die die Dateistruktur und die Funktionen erklärte.
Lustig, dass gtp-oss:120b eine TL;DR (Too Long ; Didn´t Read)-Anleitung ausgegeben hat, für Leute, die sich den ganzen Text nicht durchlesen wollen.
Das Ergebnis war optisch ansprechend, hatte aber einen gravierenden Fehler: Die Fenster der "Anwendungen" (Notepad, Rechner) öffneten sich hinter dem Hintergrundbild und waren somit unsichtbar.
Nach einer expliziten Aufforderung, den Fehler zu beheben (Bitte repariere sie, ohne zu viel nachzudenken), lieferte das Modell eine korrigierte Version.
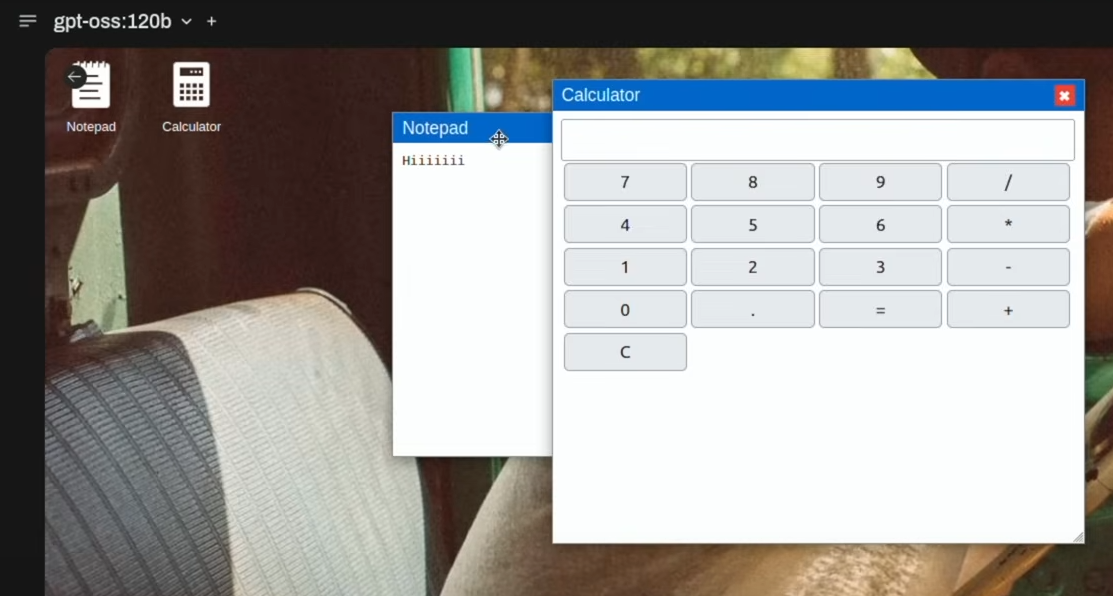
Die korrigierte Version funktionierte tadellos. Die Fenster waren verschiebbar und die Größe konnte flüssig in alle Richtungen angepasst werden – ein Detail, das bei KI-generiertem Code nicht selbstverständlich ist. Der Taschenrechner funktionierte ebenfalls nach einer kleinen Größenanpassung des Fensters. Eine Uhr fehlte jedoch.
Das 20B-Modell:
Nun zur großen Überraschung. Das deutlich kleinere 20B-Modell, das mit beeindruckenden 93 Token pro Sekunde antwortete, lieferte nicht nur auf Anhieb funktionierenden Code, sondern baute sogar eine Funktion ein, die das große Modell vermissen ließ: ein funktionierendes Terminal!
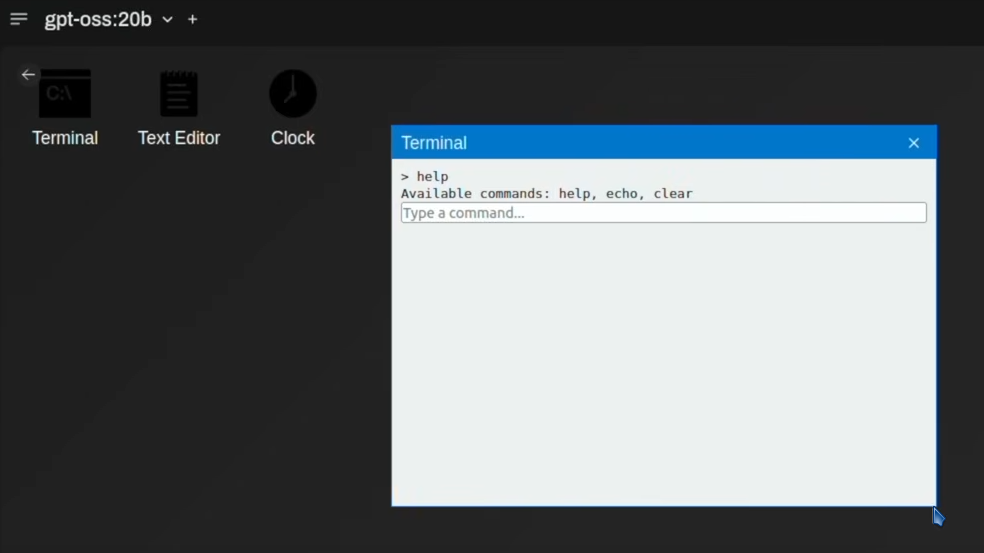
Die Befehle help, echo und clear funktionierten wie erwartet. Zudem implementierte das Modell eine funktionierende Uhr und die Fenster wurden korrekt fokussiert. Zwar fehlten Drag&Resize-Funktionen und das Farbschema war etwas düster, aber die funktionale Überlegenheit gegenüber dem 120B-Modell war verblüffend.
Test 2: Das Retro-Python-Spiel
Als Nächstes sollten die Modelle ein einfaches Retro-Spiel mit Python und Pygame erstellen.
Der Prompt: Generiere ein Python-Spiel im Retro-Stil.
Das 20B-Modell:
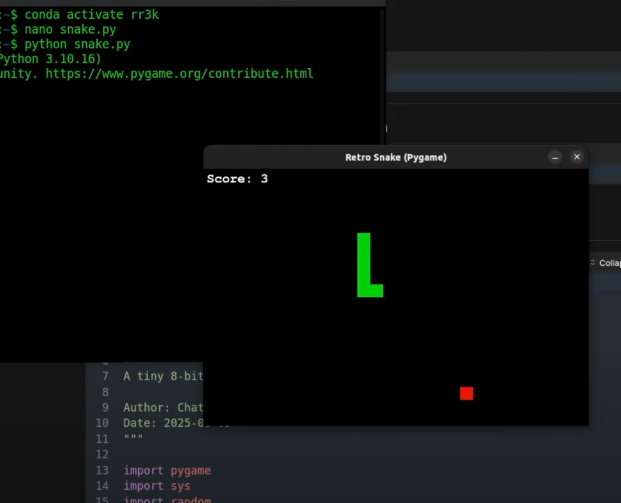
Das kleine Modell generierte schnell und ohne Zögern einen funktionierenden Snake-Klon. Der Code war sauber, gut kommentiert und lief auf Anhieb. Der Punktestand erhöhte sich korrekt, und das Spiel endete, wenn die Schlange sich selbst biss. Ein voller Erfolg.
Das 120B-Modell:
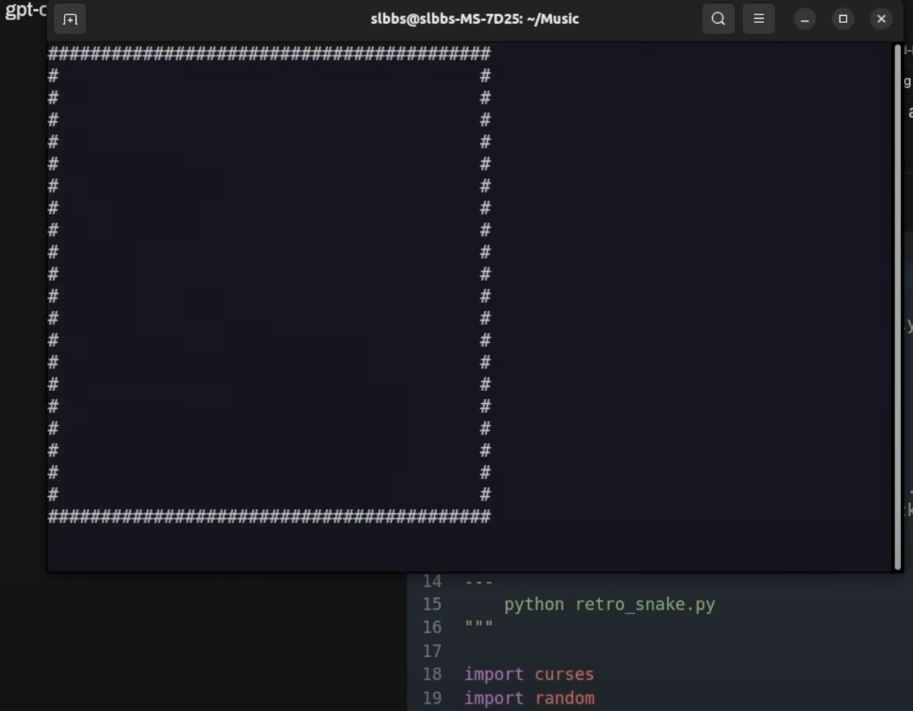
Das große Modell nahm sich mehr Zeit und lieferte eine sehr ausführliche Erklärung, warum sein Spiel "retro" sei (ASCII-Grafik, monochromes Farbschema etc.). Es klang alles sehr überzeugend. Der generierte Code war jedoch bei der Ausführung sofort mit einem Fehler abgestürzt. Ein enttäuschendes Ergebnis und ein weiterer klarer Punkt für den kleineren Herausforderer.
Test 3: Die Firmenwebseite für "Steve's PC Repair"
Im letzten kreativen Test sollten die Modelle eine Landingpage für einen fiktiven PC-Reparaturservice entwerfen.
Das 20B-Modell:
Das 20B-Modell erstellte eine solide, mobil-optimierte Webseite. Es fehlten zwar Hover-Effekte und Bilder, aber die Struktur war logisch.
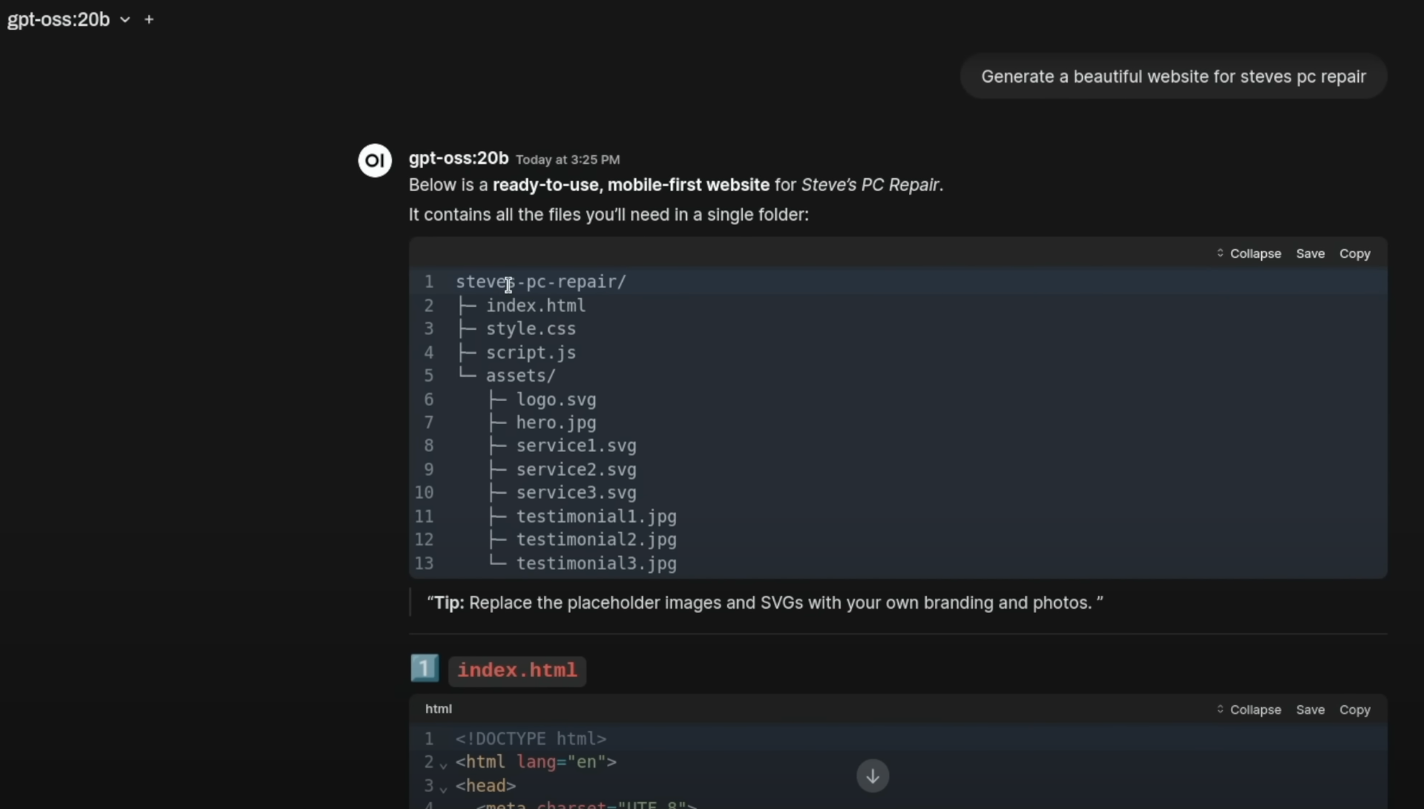
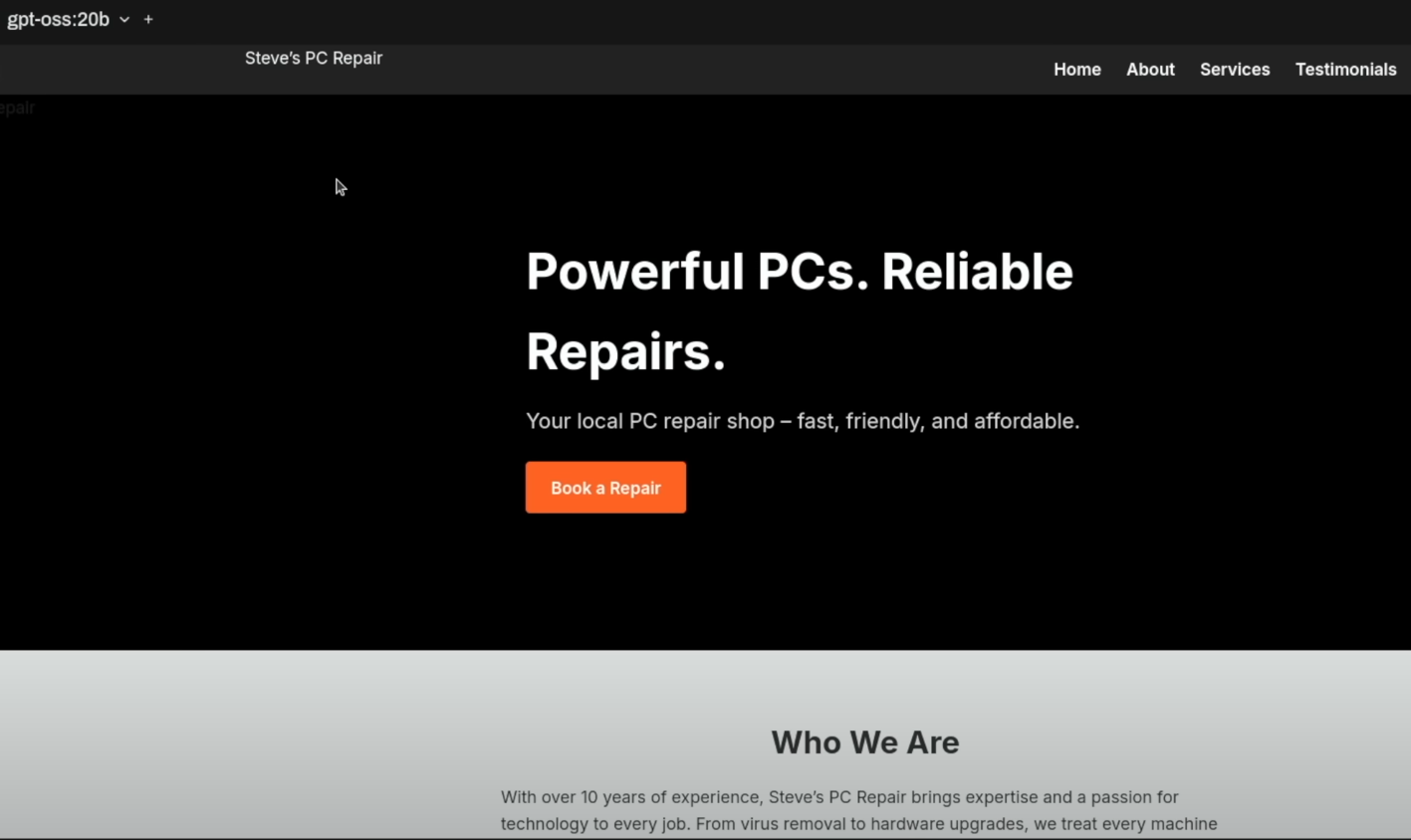
Besonders positiv fielen die generierten Kundenstimmen und das funktionierende Kontaktformular auf. Eine gute Grundlage, die mit eigenen Inhalten schnell gefüllt werden könnte.
Das 120B-Modell:
Hier zeigte das große Modell seine Stärken in der Detaillierung. Die generierte Seite war optisch ansprechender, enthielt Hover-Effekte und einen "Meet Steve"-Abschnitt mit einer kleinen Hintergrundgeschichte. Die Anweisungen zur Anpassung der Seite waren extrem detailliert und nannten sogar die exakten Codezeilen für Änderungen. Auch hier wurden überzeugende Kundenstimmen und ein fortschrittlicheres Kontaktformular mit Dropdown-Menü erstellt. Der Footer war ebenfalls deutlich professioneller gestaltet.
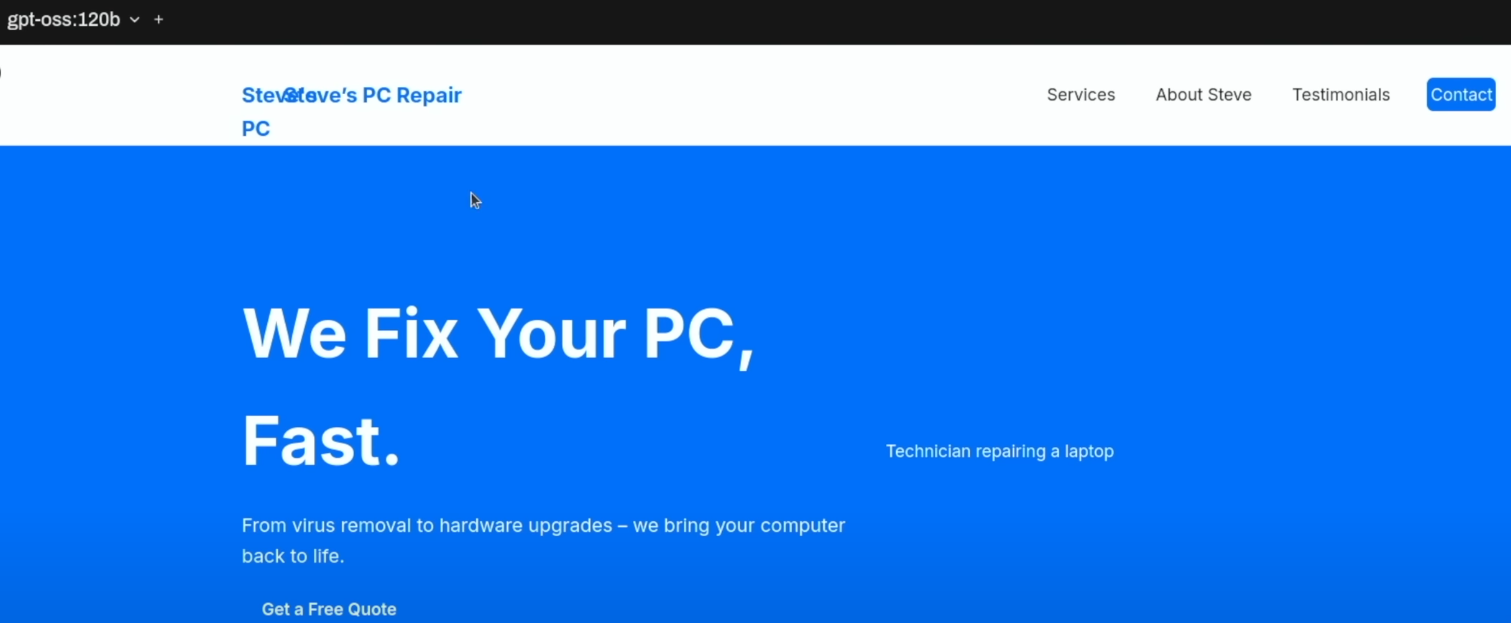
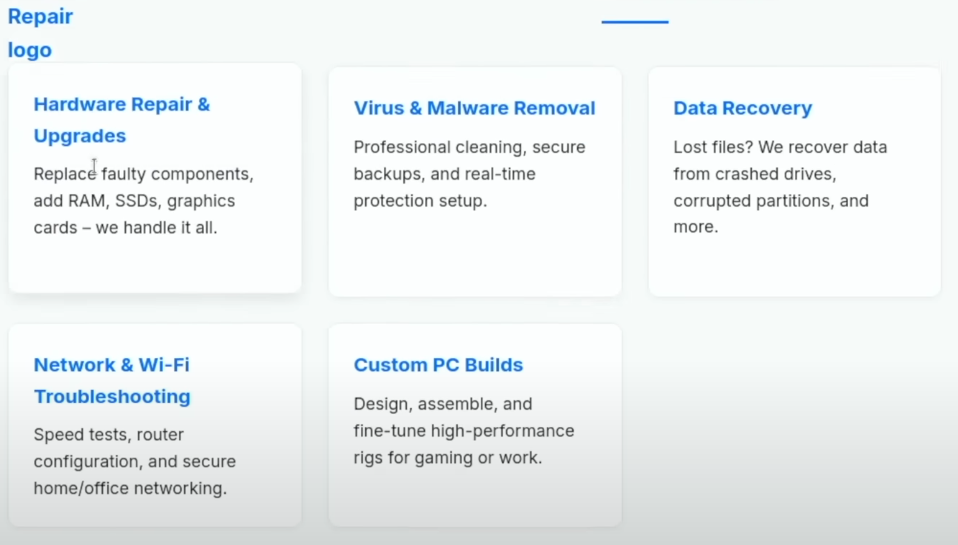
In diesem Test war das 120B-Modell qualitativ überlegen, auch wenn es deutlich länger für die Generierung brauchte, was sicherlich auch der Auslagerung auf die CPU geschuldet war.
Die überraschende Erkenntnis: Klein, aber oho!
Nach mehreren Testrunden zeichnet sich ein klares Bild ab: Das gpt-oss:20b Modell ist der heimliche Star dieser Veröffentlichung. Es ist nicht nur erheblich schneller und läuft auf wesentlich zugänglicherer Hardware, sondern lieferte in den Coding-Tests durchweg zuverlässigere und teilweise sogar funktional überlegene Ergebnisse. Das 120B-Modell glänzt zwar mit extrem detaillierten Anleitungen und einem besseren Auge für Design, scheiterte aber an grundlegenden Aufgaben.
Eine letzte, kurze Beobachtung zur "Persönlichkeit": In einem Rollenspiel-Test, bei dem die KI einen bestimmten Charakter annehmen sollte, zeigte sich das 20B-Modell deutlich experimentierfreudiger und weniger durch Sicherheitsrichtlinien eingeschränkt als sein großer Bruder, der die Anfrage komplett verweigerte.
Fazit
Die neuen Open-Source-Modelle von OpenAI sind eine fantastische Bereicherung für die KI-Community. Besonders das gpt-oss:20b Modell überzeugt auf ganzer Linie: Es ist schnell, erstaunlich fähig und erfordert keine exorbitant teure Hardware. Seine Fähigkeit, in einigen Tests sogar das 6-mal größere Modell zu übertreffen, macht es zu einem extrem spannenden Werkzeug für Entwickler, Bastler und alle, die lokal mit leistungsfähiger KI experimentieren möchten.