Obsidian mit KI denkt beim Schreiben mit
KI schlägt die nächsten zwei Sätze während des Schreibens vor...


Nachdem llama3.2:3b so beeindruckende Geschwindigkeiten gezeigt hat, kam mir der Gedanke, wie hilfreich es wäre, wenn die KI mich beim Schreiben unterstützen könnte.

Mit dem Companion-Plugin von Obsidian verfolgt die konfigurierte KI, was man schreibt, und erweitert das Dokument entsprechend.
Was braucht es dafür?
Natürlich Obsidian, denn dafür machen wir das Ganze hier! 😉 Dann kommt das Companion-Plugin ins Spiel. Und mit der passenden KI wird alles gut.
Ursprünglich ist das Companion-Plugin für ChatGPT konzipiert. Allerdings wurde in der Ollama-Version 0.124 bereits eine OpenAI-kompatible API eingeführt, die es ermöglicht, den Anbieter in der Companion-Konfiguration problemlos auszutauschen.
Companion konfigurieren
Unter den Community-Plugins lässt sich Companion leicht finden. Einfach in der Suche eingeben:
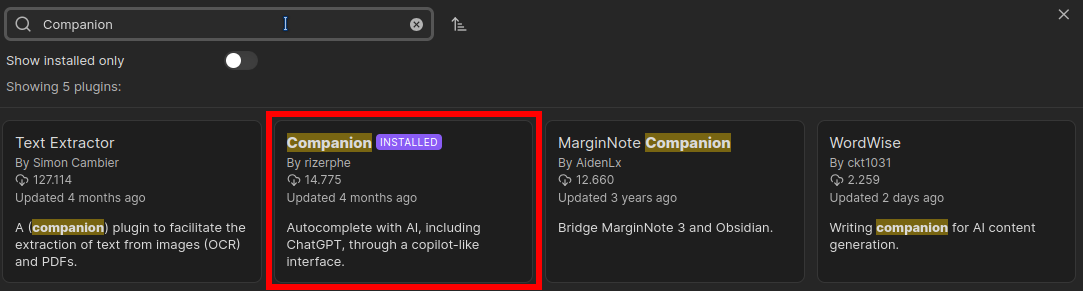
Ist das Plugin installiert, kann man es konfigurieren und aktivieren. Ich habe als Provider Ollama gewählt, der bei mir auf einem eigenen Host läuft, den ich unter dem Namen ai erreiche. Dieser muss unter der API-Route eingetragen werden.
Nach der Konfiguration erscheinen die bereits verwendeten Modelle unter Model. Da ich llama3.2:latest testen wollte, habe ich dieses Modell ausgewählt. Der User-Prompt kann auch in englischer Sprache bleiben. Die Vervollständigungen erfolgen in der Sprache des Textes, an dem man gerade arbeitet.

Der Test
Ich habe probehalber einen technischen Text verfasst, um zu erklären, wie man eine Route auf einer Firewall setzt. Der erste Entwurf war in Ordnung, und ich konnte den Großteil übernehmen und in die gewünschte Richtung lenken. Allerdings waren die Befehle zunächst fehlerhaft. Nachdem ich config router static in den Text habe einfließen lassen, erhielt ich tatsächlich brauchbare Ergebnisse. Ich habe für den Test fast alles akzeptiert. Die Fehler habe ich zur Demonstration im Text belassen.
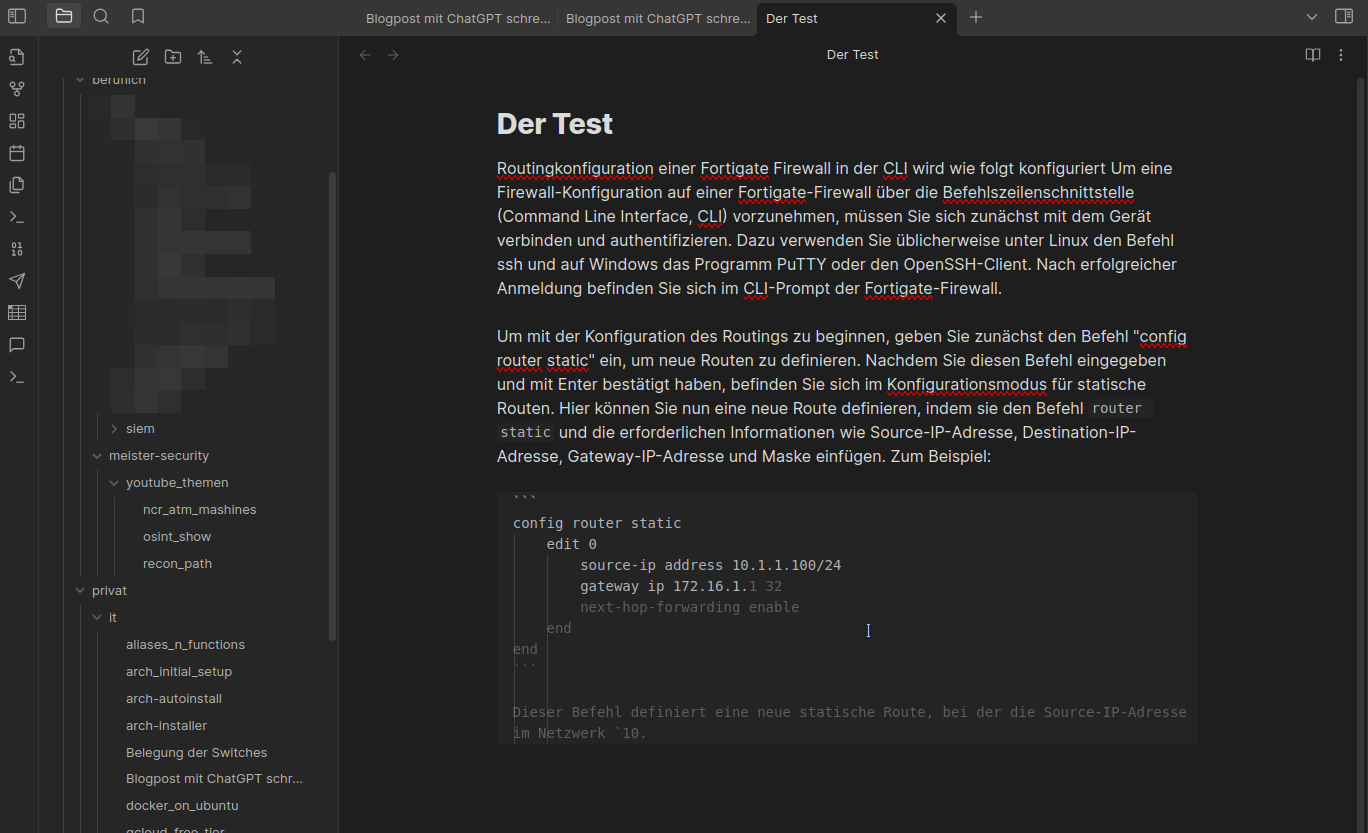
Jedes Wort kann einfach mit der TAB-Taste bestätigt werden. Wie oben in den Einstellungen zu sehen ist, lässt sich dies jedoch leicht anpassen.
Zugegeben, man kann nicht erwarten, dass llama3.2:latest perfekte Ergebnisse liefert. Dennoch ist es eine enorme Bereicherung, da die Vorschläge extrem schnell erfolgen.
Fazit
Da ich auf meiner Ollama-Instanz keine GPU habe, sind Modelle wie Mixtral und llama3.1 für diese Anwendung für mich zu langsam. Vorschläge erhält man nur, wenn man die Tastatur eine Weile nicht berührt. In der Zwischenzeit wird die CPU meines Proxmox-Servers, auf dem der Ollama-Server läuft, stark beansprucht. Mit llama3.2 ist das Companion-Plugin jedoch eine sinnvolle Konfiguration, die ich definitiv weiterempfehlen kann.