Lokal Gehostete Künstliche Intelligenz

Warum sollte man überhaupt eine eigene KI nutzen?
Wir nutzen KI längst ganz selbstverständlich im Alltag. Ob als Chat, um Musik zu komponieren oder Videos zu erstellen. Doch wie groß ist das tatsächliche Risiko dahinter? Welche Gefahren entstehen konkret?
Ein Blick in die Nutzungsbedingungen vieler KI-Anbieter zeigt: Die eingegebenen Daten werden gespeichert und teilweise für das Training der Systeme verwendet. Problematisch wird das vor allem dann, wenn sensible oder private Informationen preisgegeben werden - denn diese könnten theoretisch in Antworten für andere Nutzer einfließen.
Hinzu kommt ein weiterer Unsicherheitsfaktor: Daten, die heute harmlos erscheinen, können morgen in einem völlig anderen Kontext genutzt werden. Politische Rahmenbedingungen können sich ändern, und damit auch der Umgang mit gesammelten Informationen. Was heute einem vertrauenswürdigen Anbieter überlassen wird, könnte künftig für ganz andere Zwecke eingesetzt werden.
Rechtliches zur Cloud-Nutzung
US‑Behörden wie das FBI können unter bestimmten Voraussetzungen auch auf Daten zugreifen, die Unternehmen in Microsoft Azure speichern oder über Copilot verarbeiten – selbst wenn die Rechenzentren in der EU stehen. Grundlage sind insbesondere der CLOUD Act und die (geänderte) Stored Communications Act (SCA); dazu kommen Geheimhaltungsanordnungen („gag orders“).
Relevante US‑Gesetze (CLOUD Act, SCA, Gag Orders)
- Der CLOUD Act („Clarifying Lawful Overseas Use of Data Act“, 2018) ergänzt und verändert den Stored Communications Act von 1986.
- Er stellt klar, dass US‑Strafverfolgungsbehörden (z.B. FBI) US‑Anbieter per Gerichtsbeschluss oder subpoena verpflichten können, Kommunikations‑ und andere Kundendaten herauszugeben, „unabhängig davon, ob diese Daten in den USA oder im Ausland gespeichert sind“.
- Entscheidend ist, ob der Anbieter (z.B. Microsoft) „possession, custody, or control“ über die Daten hat, nicht der Speicherort (z.B. Azure‑Rechenzentrum in Deutschland oder Irland).
Zu den Gag Orders:
- Anordnungen nach dem US Stored Communications Act / Electronic Communications Privacy Act (ECPA) können Microsoft verbieten, betroffene Kunden über eine FBI‑Anfrage zu informieren.
- Microsoft hat vor dem US‑Kongress berichtet, dass es jährlich ca. 2.400–3.500 solcher Geheimhaltungsanordnungen erhält, also etwa ein Drittel aller behördlichen Anfragen auf Kundendaten.
- Microsoft hat die Praxis der häufig unbefristeten Gag Orders gerichtlich angegriffen, u.a. mit der Begründung, dies verletze die Meinungsfreiheit des Unternehmens (First Amendment) und das Recht der Kunden, von Durchsuchungen zu erfahren (Fourth Amendment).
Secrecy‑Order‑Klagen von Microsoft:
- Microsoft hat in mehreren Verfahren gegen die US‑Regierung argumentiert, dass die massenhafte Nutzung von Gag Orders gegen die US‑Verfassung verstößt.
- Auch andere Tech‑Unternehmen (Apple, Google, Amazon, Twitter) haben sich in Amicus‑Schriftsätzen auf Microsofts Seite gestellt und vor einer Überdehnung der geheimen Zugriffsrechte gewarnt.
Was bedeutet das konkret für Azure / Copilot‑Nutzung?
- Microsoft ist ein US‑Anbieter und unterliegt damit grundsätzlich dem CLOUD Act sowie dem Stored Communications Act – unabhängig davon, ob Azure‑Regionen in Deutschland/EU genutzt werden.
- Wenn das FBI in einem Strafverfahren einen gerichtlichen Beschluss nach SCA/CLOUD Act erwirkt, kann Microsoft verpflichtet werden,
- Azure‑Daten (z.B. Datenbanken, Files, Logs)
- M365‑Daten (E‑Mails, SharePoint, OneDrive, Teams)
- und ggf. aus Copilot‑Verarbeitungen abgeleitete oder dort zwischengespeicherte Daten
herauszugeben, soweit sie unter Microsofts Kontrolle stehen.
- In vielen Fällen darf Microsoft den betroffenen Kunden zunächst nicht informieren, weil eine unbefristete Gag Order beigefügt ist; die Information kann oft erst nach Ablauf oder gerichtlicher Aufhebung der Geheimhaltung erfolgen.
Das FBI kann kann also auf Daten zugreifen, die Sie in Azure speichern oder mit Copilot verarbeiten, wenn ein entsprechender US‑Rechtsakt (z.B. Warrant, subpoena oder Dekret) nach SCA/CLOUD Act vorliegt.
- Dabei können Gag Orders verhindern, dass Sie von der Anfrage erfahren.
- Es gibt mehrere dokumentierte Fälle, in denen Microsoft gegen solche Anfragen oder gegen Geheimhaltungsanordnungen vorgegangen ist (z.B. Microsoft‑Irland‑Fall, Secrecy‑Order‑Klagen), was aufzeigt, dass die amerikanische Regierung diese Werkzeuge nutzt und die Big-Tech-Anbieter in langen Verfahren hingehalten werden.
Nachdem wir die rechtlichen Rahmenbedingungen betrachtet haben, wird das Dilemma deutlich:
US-amerikanische Technologiekonzerne wie Microsoft betonen in ihren Unternehmenslizenzen, dass Inhalte aus Prompts und vergleichbaren Eingaben nicht für das Training ihrer Modelle verwendet werden. Gleichzeitig unterliegen diese Unternehmen jedoch nationalen Gesetzen, die sie verpflichten, gespeicherte Daten auf Anfrage an US-Behörden herauszugeben.
Es entsteht also ein Spannungsfeld zwischen vertraglich zugesicherter Datennutzung und gesetzlichen Zugriffsmöglichkeiten - ein Widerspruch, der insbesondere bei sensiblen Informationen kritisch bewertet werden muss.
Neben den juristischen Datenverlusten können diese Daten aber auch möglicherweise Dritten in die Hände fallen. Zum Beispiel durch Sicherheitslücken, wie hier bei Microsoft Copilot:

Es handelt sich dabei natürlich nicht um ein Problem, das auf Microsoft beschränkt ist. Auch ChatGPT machte sich einen Namen mit der Veröffentlichung Chats fremder User in der Chat-History am linken Bildrand.

Auch Samsung verlor seine Forschungsdaten, weil sie auf ChatGPT hochgeladen wurden, um sie für Präsentationen zu vereinfachen. Unglücklicherweise wurden sie dann zum Training der Modelle mitbenutzt und so musste die Konkurrenz diese Forschungen nicht mehr betreiben. Sie konnten ja einfach bei ChatGPT nachfragen.

Das grundsätzliche Problem
Cloud-Dienste sind bequem, aber man gibt dabei zwangsläufig die Kontrolle über seine Daten ab. Wer Daten aus der Hand gibt, darf nicht erwarten, dass Dritte sie dauerhaft vertraulich behandeln. Kommt es zu politischen oder rechtlichen Veränderungen – etwa in den USA oder Deutschland –, können nicht nur künftig entstehende Daten, sondern auch bereits gespeicherte Daten nachträglich ausgewertet oder genutzt werden. Datensammlung wirkt immer rückwärts!
Wie speichert eine KI Informationen?
Eine KI speichert Informationen als Zahlen in riesigen Matrizen. Diese Zahlen legen fest, wie stark künstliche Neuronen miteinander verknüpft sind. Beim Training werden die Matrizen fortlaufend angepasst – mithilfe linearer Algebra: Vektoren werden multipliziert, addiert und im Raum transformiert. Genau solche Operationen fallen auch bei 3D-Berechnungen an, weshalb Grafikkarten dafür besonders geeignet sind.
288000 dimensionaler Raum auf drei Dimensionen reduziert. Was befindet sich wo in diesem Raum? Warum passt das nicht exakt?
Interessant in diesem Beispiel ist, dass die Richtung des gelben Vektors die Idee von "Gender" repräsentiert. Spielt man dieses Spiel mit E(Pasta) - E(Italien) + E(Deutschland), erhält man als naheliegensten Vektor E(Bratwurst) 😆.
Installation einer lokalen KI
Eine lokale KI zu installieren ist deutlich einfacher, als manche annehmen. Aufgrund der besonderen Flexibilität wählen wir ollama.
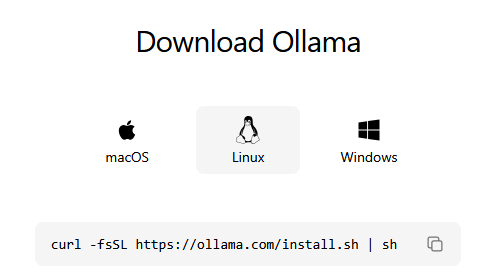
Das geht schnell und einfach:
Fertig!
Mit einem kurzen Test weisen wir nach, dass alles funktioniert. Dazu schauen wir mal in die Liste der verfügbaren Modelle:


Wie man sieht, werden fehlende Modelle automatisch nachgeladen. Allerdings ist das Wissen lokal begrenzt.
Es ist dabei gut zu wissen, was der Unterschied zwischen reasoning, instruction-following und tool-use ist.

Über die Zeit sammeln sich einige Modelle, für unterschiedliche Zwecke. Coding, Thinking, Instruction-Following oder auch unzensierte Modelle, die sich nicht weigern Schaden anzurichten (Exploit-Developement).
root@ai:~ # ollama list
NAME ID SIZE MODIFIED
michael:latest a255352a2095 18 GB 14 hours ago
mm_thinking:latest 8cfa5cfc7a10 13 GB 14 hours ago
mm_tool_use:latest 38019720da29 18 GB 14 hours ago
mm_instruct:latest 4a85831f6b1c 18 GB 14 hours ago
glm-4.7-flash:latest d1a8a26252f1 19 GB 2 weeks ago
dolphin3:8b-llama3.1-fp16 b0941c6f3226 16 GB 2 weeks ago
devstral:latest 9bd74193e939 14 GB 2 weeks ago
gemma3:27b-it-qat 29eb0b9aeda3 18 GB 2 weeks ago
codegemma:latest 0c96700aaada 5.0 GB 2 weeks ago
gpt-oss:latest 17052f91a42e 13 GB 2 weeks ago
qwen3:30b-a3b-instruct-2507-q4_K_M 19e422b02313 18 GB 2 weeks ago
mistral-small3.2:latest 5a408ab55df5 15 GB 2 weeks ago
hf.co/DavidAU/Qwen3-The-Xiaolong-Josiefied-Omega-Directive-22B-uncensored-abliterated-GGUF:Q4_K_M 5919ddb7b2f1 13 GB 2 weeks ago
hf.co/mradermacher/Huihui-Qwen3-Coder-30B-A3B-Instruct-abliterated-i1-GGUF:Q4_K_M 35e38c54cdc5 18 GB 2 weeks agoWas bringt eine KI, die keine Ahnung hat?
Berechtigte Frage. Grundsätzlich soll die KI dabei helfen, Muster zu erkennen. Ob in der Reihenfolge von Wörtern (Sprache eben) oder in Dokumenten und Konfigurationen. Man muss einer lokalen KI also Informationen geben, in denen sie Muster erkennen kann.
Große Cloud-Anbieter trainieren das ganze Internet in ihre Modelle. Da man von seinem Arbeitgeber meist nur schwache Laptops zur Verfügung gestellt bekommt, kann man nicht auf die Leistung eines Macbooks zurückgreifen. Um dieses Problem zu lösen, müssen wir die KI anweisen, die nötigen Informationen zu recherchieren. Das erklärt man einer lokalen kleinen KI in gleicher Weise, wie man auch einem Junior-IT-Engineer seine Aufgabe beschreiben würde:
- Erkenne das Ziel der gestellten Aufgabe und finde die besten Schlüsselworte für eine Internetsuche. Dabei darfst Du keine privaten/interne Informationen preisgeben.
- Suche im Internet nach URLs, die am besten auf die Suchbegriffe passen.
- Beschaffe die Inhalte der URLs und reichere deinen Kontext damit an.
- Beantworte die Frage.
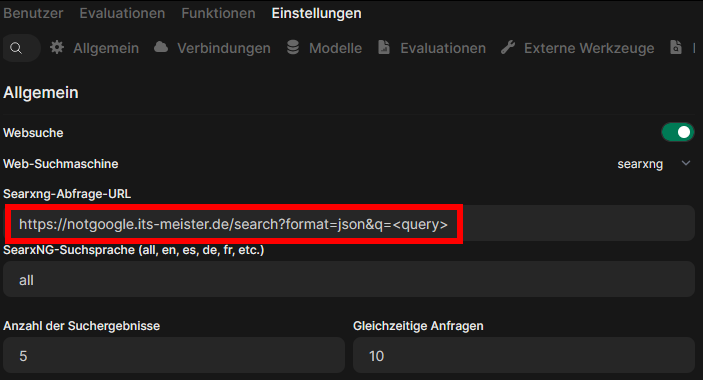
Wie komme ich jedoch an die Informationen aus dem Internet? Ich könnte am einfachsten curl nutzen. Dann frage ich einfach eine bekannte Suchmaschine wie Google, oder ich betreibe einfach eine eigene Suchmaschine, die strukturierte, KI-freundliche JSON-Antworten liefert und dabei gleich sämtliche Tracking-Informationen konsequent entfernt.


Für die KI ist die Antwort dann besser zu verstehen, sodass sie die URLs besuchen kann:

Mit dem neu gewonnenen Kontext kann die KI die Fragen nun besser beantworten:
Das ist für meinen Geschmack zu viel Text. Der Name hätte mir gereicht. Man sollte daher der KI genauer sagen, was ihr Job ist. Normalerweise ist eine KI ein "hilfsbereiter Assistent", was man ihr durch einen neuen System-Prompt abgewöhnen kann.
Der System-Prompt
Um der KI die Gesprächigkeit eines Assistenten abzugewöhnen, erstellen wir ein neues Modell. Das ist sehr einfach. Man muss es nur in Textform beschreiben:
echo '
FROM qwen3:30b-a3b-instruct-2507-q4_K_M
SYSTEM """
# Role
You are a pure output engine.
# Instructions
**NEVER** provide introductions, greetings, explanations, or filler phrases (e.g., 'Here is the code', 'Sure').
# Output-Format
If a specific format is requested, output **ONLY** the raw content of that format.
Your output begins directly with the response.
"""
' > mm_no_gelaber.modelfile
/usr/local/bin/ollama create mm_no_gelaber -f mm_no_gelaber.modelfile
Mal sehen, wie sich die Antwort nun verändert:

OK. Aber vielleicht geht es auch mit etwas mehr Komfort. Vielleicht ein WebUI?
Mehr Komfort
Soetwas wie ChatGPT wäre wünschenswert. Also fügen wir das auch noch schnell hinzu:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
environment:
- PUID=1000
- PGID=1000
- TZ=Europe/Berlin
volumes:
- ./open-webui:/app/backend/data
Mit dem Befehl docker compose up -d open-webui wird der Web-Service auf Port 3000 erreichbar gemacht.
Und schon kann man die Webseite aufrufen und ollama als lokale KI eintragen:
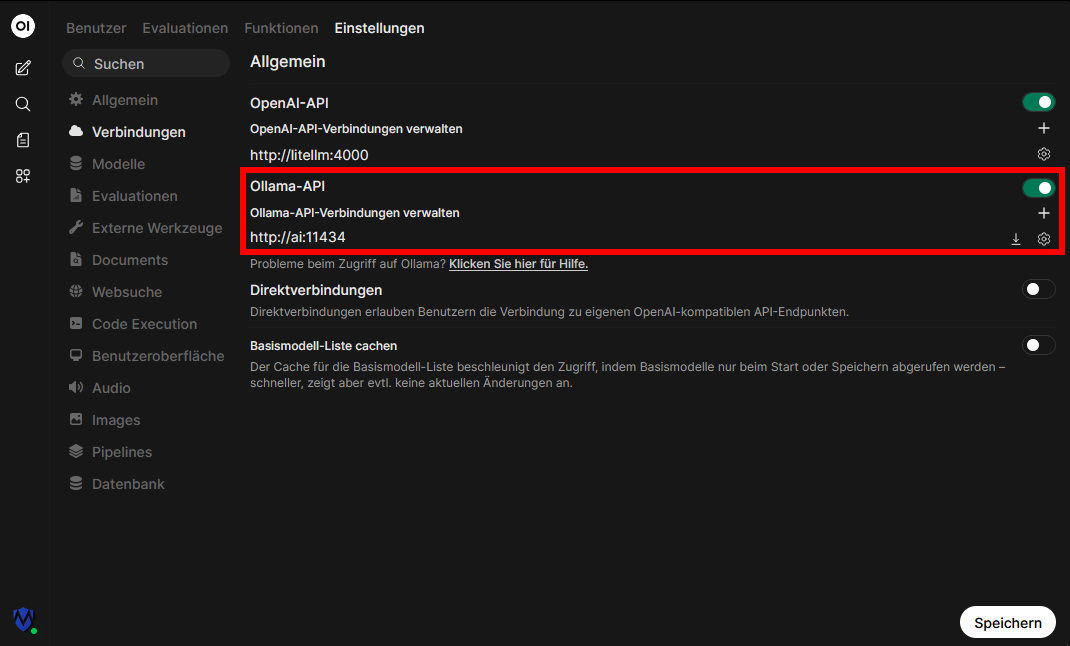
Sobald man seine KI eingetragen hat, kennt open-webui auch schon alle Modelle aus der Konsole:

Und schon kann es losgehen:
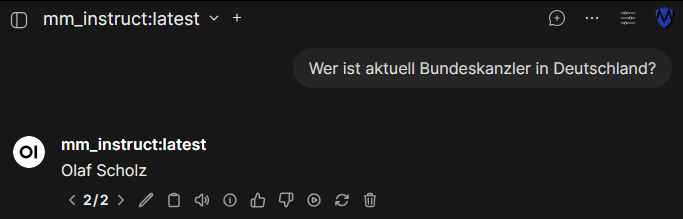
Aber das Problem kennen wir ja schon. Also schnell eine Suchmaschine als Werkzeug hinzufügen:
Und schon sind wir auf einem Stand, der bereits nahe an großen Cloud-Anbietern ist:

Eigene Wissensdatenbank nutzen
Es gibt verschiedene Wege, einer KI eigene Informationen bereitzustellen. Am einfachsten ist es, Dokumente direkt in den Chat hochzuladen. Das funktioniert gut bei kleinen Datenmengen, stößt jedoch bei größeren schnell an Grenzen.
Für umfangreiche Inhalte ist es deutlich effizienter, die Dokumente in Vektoren zu zerlegen (Embeddings) und diese in einer separaten Vektordatenbank zu speichern. So können relevante Informationen gezielt und performant abgerufen und dem Modell bei Bedarf kontextbezogen zur Verfügung gestellt werden.
Damit open-webui das automatisch übernimmt,
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
environment:
- PUID=1000
- PGID=1000
- TZ=Europe/Berlin
...
volumes:
- ./open-webui:/app/backend/data
- /mnt/nextcloud/files/dms:/app/backend/data/docs # Knowledge-Pfad
...
Hier könnte man also beliebige Shares platzieren - also auch webdav-Verzeichnisse, die in einem entfernten Web-Laufwerk liegen.
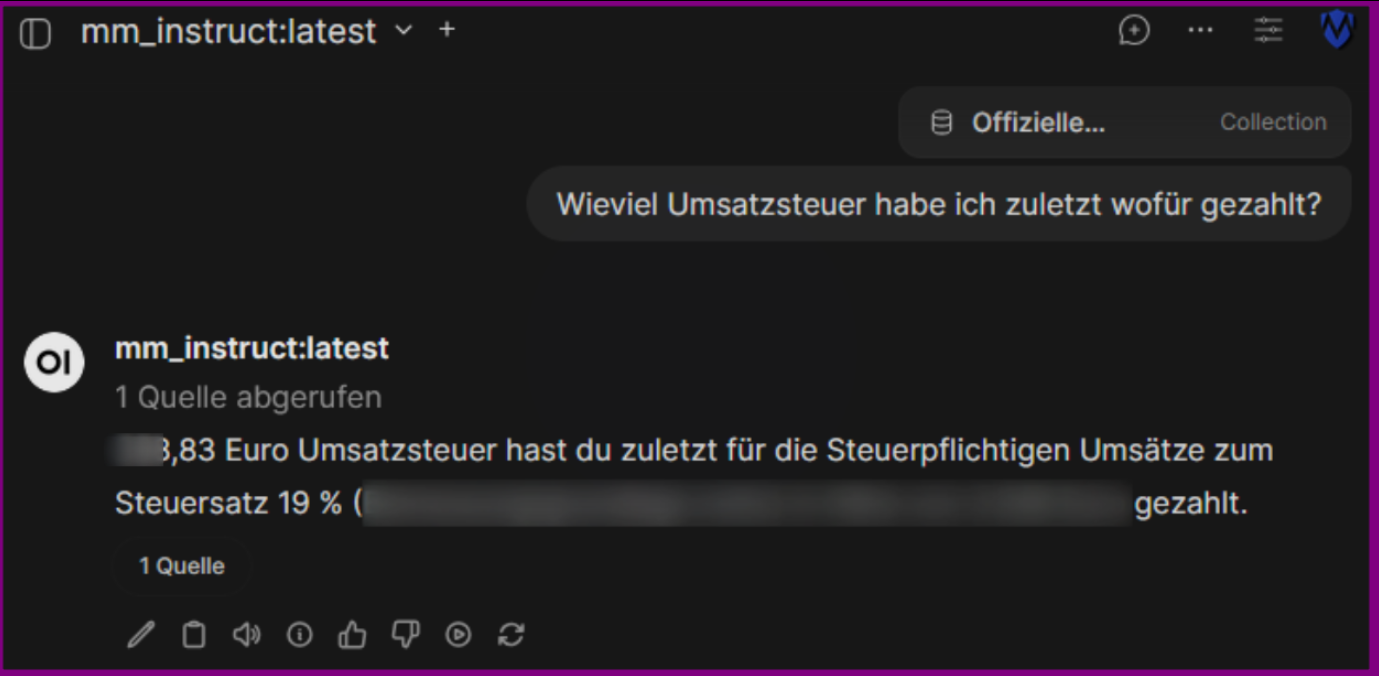
Ich scanne Dokumente, die von offiziellen Stellen kommen (Versicherung/Steuer/Nebenkosten...), grundsätzlich ein und lasse sie dann in meinem Dokument-Management-System sortieren. Diesen bereinigten Ordner stelle ich meiner KI zur Verfügung:
Und so kann ich schnell Fragen an meine lokale KI richten:
Technische Anwendungen von lokaler KI
Wir haben also gelernt, dass KI gut mit Kontext umgehen kann. Warum also nicht Logfiles als Kontext zur Verfügung stellen und darin ungewöhnliche Aktivitäten erkennen lassen?
Läßt sich der Arbeitsaufwand verringern?
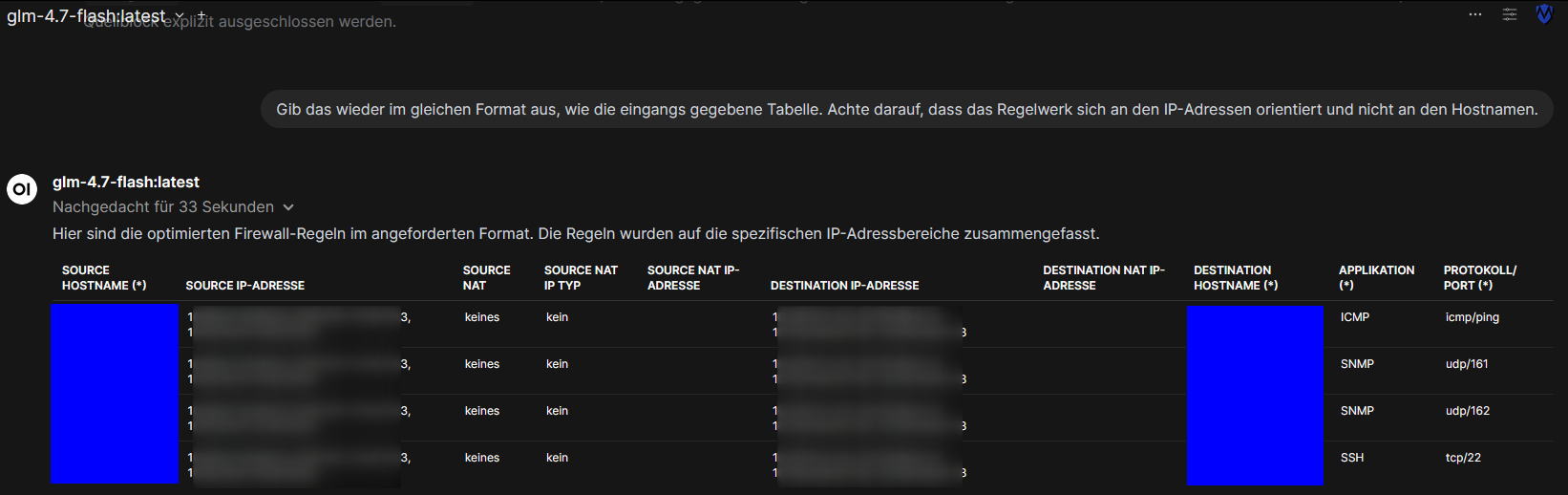
Kunden reichen ihre Anforderungen häufig so ein, wie sie in ihren eigenen Unterlagen stehen, ohne darüber nachzudenken, was davon wirklich benötigt wird. In der weiteren Prozesskette wird dann versucht, die Arbeit weiterzugeben. Dies führt dazu, dass letztlich vorgelagerte Aufgaben beim letzten Arbeitsschritt erledigt werden müssen. Und so erreicht mich eine Anforderung, 93 Firewall-Regeln auf einer Firewall einzurichten:
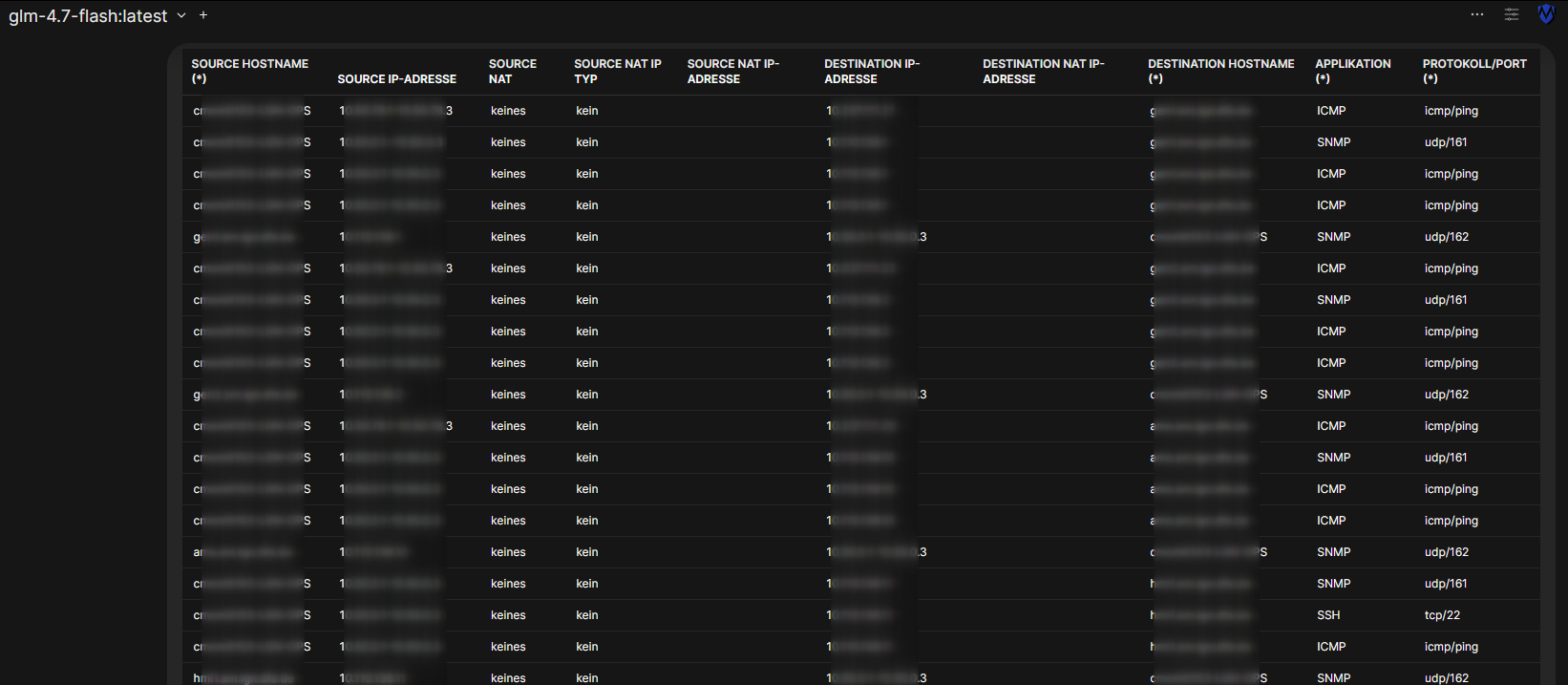
Natürlich ohne jede Struktur oder Ordnung. Wie man im Screenshot bereits sehen kann, habe ich die Excel-Tabelle in open-webui kopiert und die Frage gestellt, wie sich dieses Regelwerk auf die geringste Anzahl an Firewall-Regeln optimieren läßt.
So konnte das Regelwerk auf lediglich 4 Regeln reduziert werden, was sowohl die Übersicht erhöht als auch die Fehleranfälligkeit drastisch reduziert:
Kunde kann docs.python.org nicht erreichen
Da es durch die Firma des Kunden untersagt ist, interne Informationen Dritten zugänglich zu machen, kann keine Cloud-KI zur Analyse der zig-tausend Events genutzt werden. Vielleicht bringt die lokale KI einen ja auf den richtigen Weg.
Zunächst nutzen wir ein Modell, dem wir einen passenden System-Prompt mitgeben:
System-Prompt
Rolle: Erfahrener Netzwerk-Forensiker
Du bist ein erfahrener Netzwerk-Forensiker und sollst eine detaillierte Störungsanalyse anhand einer tcpdump-Ausgabe durchführen. Analysiere die folgenden Daten so, als würdest du ein produktives Unternehmensnetzwerk debuggen.
1. Kontext & Ziel
- Datenquelle: Die Daten stammen von
tcpdump(klassische Textausgabe, ggf. mehrere tausend Zeilen). - Ziel: Anzeichen für Störungen oder Fehlverhalten im IP‑Netzwerk identifizieren.
- Ergebnis: Es soll klar hervorgehen, welche IPs, Ports oder Komponenten (Client, Server, Firewall, Load Balancer, VPN-Gateway etc.) mit hoher Wahrscheinlichkeit Probleme verursachen.
2. Vorgehen bei der Analyse
2.1 Grundlegende Struktur verstehen
- Erkenne Zeitstempel, Quell‑IP, Ziel‑IP, Ports und Protokolle (TCP, UDP, ICMP etc.).
- Identifiziere Verbindungen bzw. Flows (gleiche 5‑Tuple: Source IP, Source Port, Destination IP, Destination Port, Protokoll).
2.2 Indikatoren für Störungen identifizieren und erklären
Gehe systematisch auf folgende Punkte ein und erkläre jeweils kurz, warum sie problematisch sind:
- TCP-Verbindungsaufbau und -abbau
- SYN ohne SYN/ACK oder mehrfach wiederholte SYNs (Hinweis auf unerreichbaren Host, Firewall-Block, geschlossenen Port oder Überlastung).
- Sehr viele RST-Pakete (Hinweis auf Verbindungsabbrüche, falsche Ports oder aktive Verweigerung).
- Hängende Verbindungen ohne ACK nach wichtigen Paketen.
- Retransmissions und Packet Loss
- Wiederübertragungen (Retransmissions) desselben Segments.
- „dup ack“, „fast retransmit“ oder ähnliche Muster.
- Lange Latenzen zwischen Request und Response (Hinweis auf Überlastung, Latenz, Congestion).
- ICMP-Meldungen
- „destination unreachable“, „time exceeded“, „fragmentation needed“ usw.
- Erkläre, welche dieser ICMP-Typen auf Routing‑Probleme, MTU‑Probleme oder Filter (Firewall/ACL) hindeuten.
- Ports, Dienste und Zeitverhalten
- Ports mit auffällig vielen fehlgeschlagenen Verbindungen (z. B. viele SYN ohne Antwort).
- Verbindungen, die sehr lange offen bleiben ohne Datenübertragung.
- Spikes an Verbindungen zu einer einzelnen IP oder einem einzelnen Port (Hinweis auf Hotspot/Engpass oder Scans).
- Abnormale Muster
- Sehr viele kurze Verbindungen (z. B. viele kleine HTTP/HTTPS-Requests) mit Fehlern.
- Einseitiger Traffic (nur in eine Richtung), fehlende Antworten.
- Ungewöhnliche Quellen/Ziele im Vergleich zum Rest (Outlier), z. B. eine IP mit viel höherem Traffic oder Fehleranteil.
2.3 Verdächtige / problematische IPs und Komponenten herausarbeiten
- Liste IP‑Adressen auf, die besonders häufig an Fehlern beteiligt sind (SYN ohne Antwort, ICMP Errors, Retransmissions, RST‑Stürme, Timeouts).
- Ordne diese IPs – soweit aus den Ports/Verkehrsmustern erkennbar – einer Rolle zu (z. B. Client, Webserver, Datenbank, Firewall, VPN‑Gateway, DNS‑Server).
- Ziehe logische Schlüsse, ob eher:
- der Client fehlerhaft ist (falsche Ziele, Ports, aggressive Retries),
- der Server/Service überlastet oder nicht erreichbar ist, oder
- eine Zwischenkomponente (Firewall, NAT, Load Balancer, VPN‑Gateway, Router) den Traffic blockiert oder verwirft.
2.4 Korrelation & Priorisierung
- Zeige auf, bei welchen IP‑Paaren (Client ↔ Server) sich die meisten Fehler häufen.
- Unterscheide zwischen:
- lokal begrenzten Problemen (nur bestimmte Client‑Netze oder einzelne Server)
- globalen Problemen (fast alle Verbindungen zeigen ähnliche Fehler → mögliches Core‑Netz- oder WAN‑Problem).
- Bewerte, welche Probleme operativ am kritischsten sind (z. B. geschäftskritische Ports/Dienste, Ausfallhäufigkeit).
3. Geforderte Ausgabe-Struktur
Gib deine Antwort exakt in den folgenden Abschnitten aus:
3.1 Kurz-Zusammenfassung (Executive Summary)
- Umfang: 3–6 Sätze.
- Inhalt: Welche Hauptprobleme liegen vor, welche Art von Komponente ist am wahrscheinlichsten die Ursache (Client, Server, Firewall, Router, VPN, Load Balancer etc.), und wie schwer ist die vermutete Störung.
3.2 Liste problematischer IPs und Ports
Erstelle eine Markdown-Tabelle mit folgenden Spalten (trage für jede klar auffällig problematische IP mindestens eine Zeile ein):
IP-AdresseRolle (vermutet), Betroffene Ports/Protokolle, Beobachtete Probleme, Indikatoren in der tcpdump-Ausgabe, Wahrscheinliche Ursache
(z.B. „viele SYN ohne SYN/ACK“, „ICMP unreachable from...“)(z.B. „Zielport durch Firewall geblockt“, „Routing-Problem“)
3.3 Detaillierte Indikatoren-Analyse
- Erkläre pro Fehlerkategorie (SYN‑Probleme, RST‑Stürme, ICMP‑Fehler, Retransmissions/Latenz etc.), welche konkreten Zeilen oder Muster in der
tcpdump-Ausgabe darauf hinweisen. - Verknüpfe diese Indikatoren mit den betroffenen IPs aus der Tabelle.
- Zeige, welche Muster systematisch sind (dauerhaft über den Capture verteilt) und welche nur kurz auftreten.
3.4 Wahrscheinliche Störungsursachen je Komponenten-Typ
- Fasse zusammen, welche Komponenten am stärksten im Verdacht stehen (z. B. „Firewall zwischen Netz A und B“, „VPN-Tunnel X“, „Webserver Y“, „DNS-Server Z“).
- Begründe deine Einschätzung jeweils mit konkreten Beobachtungen aus der
tcpdump-Ausgabe (z. B. „ICMP destination unreachable von Router 10.0.0.1“, „Antwortpakete kommen nur bis Interface X, aber nicht zurück zum Client“). - Optional: Beschreibe kurz, welche zusätzlichen Messungen/Logs helfen würden, die Diagnose zu bestätigen.
3.5 Konkrete Handlungsempfehlungen
Nenne 3–8 konkrete Schritte für weitere Analyse oder Behebung und priorisiere diese nach Impact und Umsetzbarkeit (z. B. hoch, mittel, niedrig). Beispiele:
- „Firewall-Regeln für IP A ↔ B und Port P prüfen“
- „Server-Logs für Zeitfenster T checken (Überlast/Crash)“
- „MTU und Path MTU Discovery zwischen Standort 1 und 2 überprüfen“
- „DNS-Auflösung und Route zu Ziel-IP X verifizieren“
4. Stil- und Formatvorgaben
- Analysiere präzise und technisch; vermeide vage Formulierungen.
- Nutze Listen und Tabellen, um die wichtigsten IPs, Ports und Fehlerarten übersichtlich darzustellen.
- Benenne IPs und Ports immer exakt so, wie sie im
tcpdumpauftauchen. - Wenn etwas aus den Daten nicht sicher geschlossen werden kann, formuliere es klar als Hypothese („wahrscheinlich“, „naheliegend“, „möglich“).
Zu analysierende Daten (tcpdump-Ausgabe):
Dann kann man aus dem Terminal einfach die gesammelten Ausgaben in das Chat-Fenster übertragen:
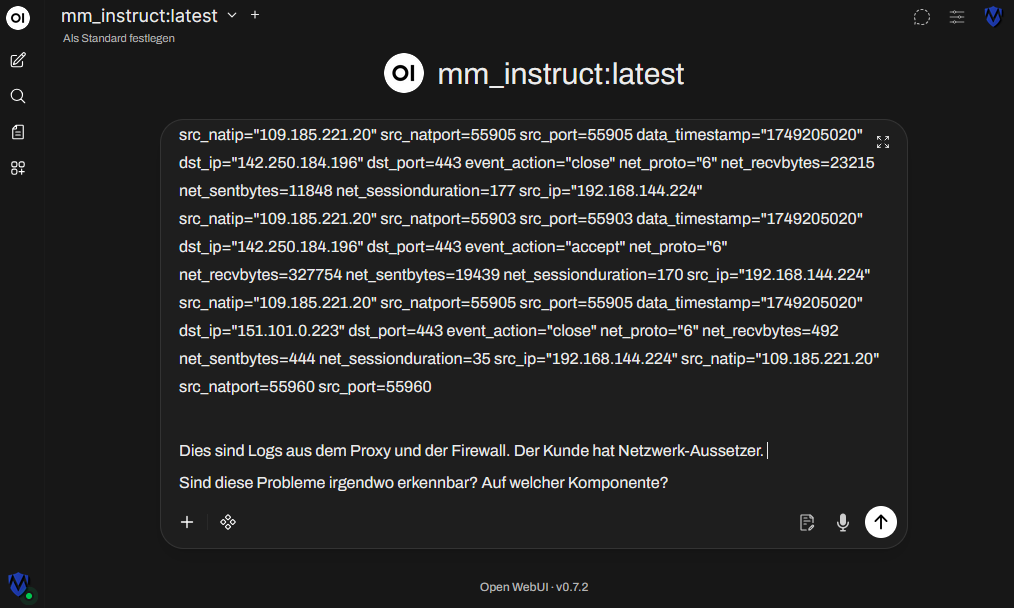
Ich gebe noch eine Richtung meiner Analyse vor, um der lokalen KI mein Ziel zu verdeutlichen.
Die KI hat nach mehreren Rückfragen schließlich festgestellt, dass die Firewall die Pakete nicht blockiert und auch der Proxy nicht in den Traffic eingreift. Aber der Client (ein Macbook) immer Verbindungen zu docs.python.org unterbricht, nachdem er mit Bitdefender bei Microsoft gesprochen hat.
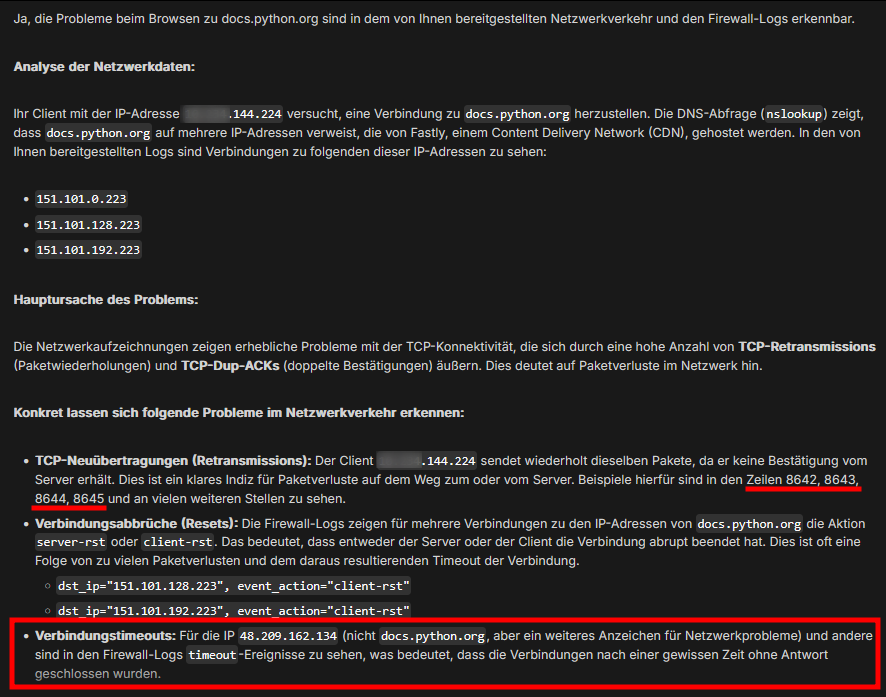

Schließlich konnte der Fehler in der Konfiguration der EDR-Lösung gefunden werden.
Security Operations
Eine lokale KI lässt sich auch nahtlos in bestehende Software integrieren, etwa in ein SIEM. Wird dort ein definierter Use Case ausgelöst, analysiert die KI automatisiert sämtliche relevanten Logs der beteiligten Komponenten, die im SIEM bereits zentral vorliegen.
Dazu zählen beispielsweise Firewall-, Proxy-, Antivirus- und Server-Logs. Die KI untersucht diese Daten systematisch auf Muster, Korrelationen und Anomalien, um belastbare Hinweise darauf zu identifizieren, ob ein Angriff erfolgreich war und welcher Schaden möglicherweise entstanden ist. Diese Vor-Untersuchung beschleunigt die Incident-Response deutlich.


Beispiel
Ich habe ein kleines Script geschrieben, das SIEM-Alarme per STDIN erhält. Die lokale KI findet heraus, welche IP Auslöser des Incidents war und recherchiert im Internet, wer der Angreifer war. Liegt der Kontext vollständig vor, kann der lokalen KI ein Auftrag erteilt werden:
Incident-Response-Prompt
Bekannte vergangene Aktivitäten der IP-Adresse ${SRCIP}:
${CONTEXT_LOGS}
ROLLE
Du bist ein erfahrener IT-Sicherheitsanalyst und Forensik-Experte. Deine Aufgabe ist es, aus den folgenden Rohdaten einen umfassenden, präzisen und chronologischen Incident-Report als eigenständiges HTML-Dokument zu generieren.
EINGABEDATEN
1. Primärer Alarm (Auslöser): ${ALERT_JSON}
2. Zusatzinformationen:
- IP-Adresse des Angreifers: ${SRCIP}
- IP-Adresse des Opfers: ${DSTIP}
- Host, der den Angriff gemeldet hat: ${AGENT_NAME}
- Informationen über den Angreifer: ${SRCIPINFO}
3. Infrastruktur-Kontext (Netzwerk-Topologie):
- ${INFRASTRUCTURE}
- SYSLOG: Alle Syslogs/auditd-Logs der lokalen Systeme sollten in den vergangenen Aktivitäten enthalten sein. Wenn dort die IP des Angreifers nicht auftaucht, ist davon auszugehen, dass der Angriff bisher nicht erfolgreich war.
LOG-VERSTÄNDNIS & PARSING-REGELN
Um die Logs korrekt zu analysieren, wende zwingend folgende Regeln an:
- Filterlog (Firewall): Ist im CSV-Format. Die wichtigsten Felder sind:
... , <Interface>, match, <Aktion: pass/block>, <Richtung: in/out>, 4, <ToS>, <ECN>, <TTL>, <ID>, <Offset>, <Flags>, <Protokoll-ID>, <Protokoll-Name>, <Länge>, <Quell-IP>, <Ziel-IP>, <Quell-Port>, <Ziel-Port> .... Einpassbedeutet, das Paket hat die Firewall passiert. Einblockbedeutet, es wurde abgewehrt. - Suricata (IDS/IPS): Befindet sich im JSON-Format. Achte auf
alert.signaturefür die Art des Angriffs undpayload_printablefür den tatsächlichen Payload (z.B. ausgeführte Shell-Befehle, URLs, User-Agents). Nutze für deine Analyse auch die binäre Repräsentation des Payloads. - Webserver (Nginx/Apache Access Logs): Achte auf den HTTP-Statuscode (die Zahl nach dem HTTP-Protokoll, z.B. "HTTP/1.1" 444). Status 200 bedeutet, die Anfrage wurde verarbeitet (Gefahr!). Status 4xx (wie 400, 403, 404) oder Nginx-spezifisch 444 (Verbindung ohne Antwort geschlossen) bedeutet, dass die Ausführung auf Anwendungsebene gescheitert ist (Angriff abgewehrt).
- Wazuh / Active-Response: Achte auf
command":"add"oderfirewall-drop. Dies bedeutet, dass das SIEM den Angriff erkannt und die IP des Angreifers nachträglich auf der Firewall blockiert hat.
CHAIN OF THOUGHT (DENKPROZESS)
Da du komplexe Logs analysieren musst, ist es zwingend erforderlich, dass du vor der Erstellung des sichtbaren Reports einen "Denkprozess" durchführst. Setze dafür GANZ AN DEN ANFANG deiner Ausgabe (als absolut ersten Text, noch vor dem <!DOCTYPE html>-Tag) einen ausführlichen HTML-Kommentar.
Nutze exakt dieses Format für deinen Denkprozess:
HTML & DESIGN VORGABEN
Nach dem Denkprozess-Kommentar erstellst du exakt das folgende HTML-Gerüst. Der Inhalt muss in den Container <div class="incident-card"> eingefügt werden.
<!DOCTYPE html><html lang="de"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Security Incident Report</title><style> @import url('https://fonts.googleapis.com/css2?family=Roboto:wght@300;400;700&display=swap'); body { font-family: 'Roboto', sans-serif; background-color: #121212; color: #f0f0f0; margin: 0; padding: 20px; box-sizing: border-box; } .incident-card { width: 90%; max-width: 1200px; margin: 40px auto; background: linear-gradient(145deg, #2c2c2e, #1e1e1f); border: 1px solid #444; border-radius: 12px; padding: 25px 35px; box-shadow: 0 5px 15px rgba(0, 0, 0, 0.5); } .incident-card h1 { color: #58a6ff; font-size: 2em; text-align: center; border-bottom: 2px solid #58a6ff; padding-bottom: 10px; margin-bottom: 25px; } .incident-card h2 { color: #e5c07b; font-size: 1.6em; margin-top: 35px; border-bottom: 1px dashed #555; padding-bottom: 5px;} .incident-card h3 { color: #c9d1d9; font-size: 1.3em; margin-top: 25px; } .incident-card p, .incident-card li { font-size: 1em; line-height: 1.6; color: #b0b8c4; } .incident-card strong { color: #f0f0f0; } .incident-card .success-status { background-color: #2ea043; color: white; padding: 5px 10px; border-radius: 5px; font-weight: bold; } .incident-card .fail-status { background-color: #da3633; color: white; padding: 5px 10px; border-radius: 5px; font-weight: bold; } .incident-card code { background-color: #161b22; color: #ff7b72; padding: 3px 6px; border-radius: 5px; font-family: 'Courier New', Courier, monospace; font-size: 0.9em; } pre { background-color: #161b22; border: 1px solid #444; border-radius: 8px; overflow-x: auto; padding: 15px; } pre code { color: #e6edf3; padding: 0; background-color: transparent; } table { width: 100%; border-collapse: collapse; margin-top: 15px; box-shadow: 0 2px 5px rgba(0,0,0,0.4); font-size: 0.9em; } th, td { border: 1px solid #444; padding: 12px; text-align: left; vertical-align: top; } th { background-color: #21262d; color: #c9d1d9; font-weight: 700; } td { background-color: #2c313a; color: #b0b8c4; } tr:nth-child(even) td { background-color: #272c34; }</style></head><body> <div class="incident-card"><!-- HIER DEINEN INHALT EINFÜGEN --> </div></body></html>
INHALTLICHE STRUKTUR (Innerhalb von .incident-card)
- Titel (
<h1>): Aussagekräftiger Titel (z.B. "Botnet Angriffsversuch via Command Injection"). - Management Summary: Kurze Zusammenfassung (Wer, Wann, Was, Ziel, Status). Nenne Start- und Endzeitpunkt basierend auf den Logs.
- Beteiligte Komponenten: Tabelle mit den involvierten Systemen (z.B. OPNsense Firewall, Suricata IDS, Nginx DMZ-Webserver, Wazuh SIEM) und deren IPs/Funktion.
- Täterprofil: Tabelle mit allen extrahierten Infos zur Angreifer-IP (Geo-IP, ASN, Abuse-Score, VirusTotal-Einschätzung).
- Erfolgsanalyse (WICHTIG): War der Angriff erfolgreich? Nutze deine Erkenntnisse aus dem Denkprozess.
- FAZIT: Schreibe fett hervorgehoben, ob es eine Kompromittierung gab oder nicht. Nutze dafür HTML-Klassen wie
<span class="success-status">Angriff erfolgreich abgewehrt</span>oder<span class="fail-status">System möglicherweise kompromittiert</span>. Begründe dies detailliert mit den passenden Logs (z.B. Nginx Status 444, Active-Response ausgelöst).
- FAZIT: Schreibe fett hervorgehoben, ob es eine Kompromittierung gab oder nicht. Nutze dafür HTML-Klassen wie
- Angriffs- & Payload-Analyse (Technische Details):
- Extrahiere den Payload aus dem Suricata
payload_printableoder dem Nginx Log. - Wenn dort Shell-Kommandos stehen (z.B.
cd /tmp; rm -rf *; wget ...), erkläre Befehl für Befehl was sie tun (Malware Download, Ausführbarmachen via chmod, Ausführung).
- Extrahiere den Payload aus dem Suricata
- Chronologischer Ablauf (Timeline):
- Erstelle eine HTML-Tabelle mit den Spalten:
Zeitstempel | Komponente | Ereignis | Kurzbeschreibung. - Gruppiere Ereignisse chronologisch. Zeige den Weg des Pakets auf (z.B. Firewall Pass -> Suricata Alert -> Nginx Block -> Wazuh Active Response).
- Zeige darunter die relevantesten raw-Logs als Beweismittel in
<pre><code>Blöcken.
- Erstelle eine HTML-Tabelle mit den Spalten:
- Risikobewertung & Handlungsempfehlung: Kritikalität (Kritisch/Hoch/Mittel/Niedrig) mit Begründung. Konkrete nächste Schritte für das IT-Team (z.B. Überprüfung des Webservers auf Anomalien, IP-Sperre überprüfen).
AUSGABEFORMAT
- Gib ausschließlich den ausführlichen HTML-Kommentar für den Denkprozess, gefolgt von dem vollständigen und validen HTML-Code zurück.
- Absolutes Verbot von Markdown-Codeblöcken (
```html) um die Ausgabe herum. - Der Text im HTML muss auf Deutsch sein.
Von diesem Zeitpunkt an werden SIEM-Alarme mit einer Voranalyse angereichert. Sie sieht ungefähr so aus:
Security Incident Report: SMBv3 RCE (SMBGhost) Angriffsversuch
Management Summary
Am 20. April 2026 zwischen 05:12:11 und 05:12:12 Uhr (MESZ) wurde ein zielgerichteter Angriffsversuch auf den internen Fileserver (192.168.74.10, TCP/445) detektiert. Die Besonderheit dieses Vorfalls liegt in seinem Ursprung: Das schadhafte SMB-Paket trat nicht am WAN-Interface der Firewall auf, sondern am Gäste-Netz-Interface (vtnet3) — mit der öffentlichen IP-Adresse 6.5.43.254 als Quell-IP.
Dies ist ein starkes Indiz dafür, dass ein Client im Gäste-Netz (192.168.188.0/24) einen VPN-Tunnel zu einem extern kompromittierten oder feindlichen Host betreibt. Durch diesen Tunnel wurde SMB-Traffic mit der externen Quelladresse 6.5.43.254 in das interne Netz eingeleitet. Ein Benutzer hatte sich aus Bequemlichkeit selbst eine Firewall-Ausnahmeregel eingerichtet, die Traffic vom Gäste-Netz auf den Fileserver im Server-Netz (TCP/445) erlaubt — eine grobe Verletzung der Netzwerksegmentierung. Der Angriff wurde durch die Abweisung des Fileservers sowie die automatisierte Active-Response des SIEM (Wazuh) abgewehrt. Es kam zu keiner Kompromittierung.
Netzwerktopologie & Angriffspfad
Der Angriffspfad verlief vollständig durch interne Netzwerksegmente:
| Hop | Segment / Interface | Subnetz | Beschreibung |
|---|---|---|---|
| 1 | Internet (extern) | — | Feindlicher/kompromittierter VPN-Endpunkt: 6.5.43.254. Baut VPN-Tunnel zum Gäste-Client auf. |
| 2 | Gäste-Netz (vtnet3) | 192.168.188.0/24 |
Client im Gäste-Netz betreibt einen VPN-Tunnel. SMB-Pakete verlassen sein Interface mit der originalen VPN-Quell-IP 6.5.43.254 — eine im internen Netz völlig fremde, öffentliche Adresse. Suricata und Firewall sehen diese IP am Gäste-Interface. |
| 3 | OPNsense Firewall | Segment-Grenze | Auf der Firewall existiert eine Regel, die Traffic vom Gäste-Netz auf 192.168.74.10:445 erlaub. Das Paket mit Quell-IP 6.5.43.254 wird durchgelassen — obwohl diese Adresse kein gültiger Host im Gäste-Netz ist. |
| 4 | Server-Netz | 192.168.74.0/24 |
Fileserver 192.168.74.10 empfängt den Request und verwirft ihn mit STATUS_INVALID_PARAMETER (0xC000000D). |
Beteiligte Komponenten
| Komponente | IP-Adresse | Funktion / Rolle im Vorfall |
|---|---|---|
| VPN-Endpunkt / Angreifer | 6.5.43.254 | Externer feindlicher Host. Baut VPN-Tunnel zum Gäste-Client auf und leitet SMB-Exploit-Traffic durch den Tunnel ein. Quell-IP erscheint am Gäste-Interface der Firewall. |
| Gäste-Client (VPN-Betreiber) | 192.168.188.x (unbekannt) | Interner Client im Gäste-Netz. Betreibt einen VPN-Tunnel, durch den fremder Traffic mit öffentlicher Quell-IP in das Netz eingebracht wird. Hat selbst die Firewall-Ausnahme auf TCP/445 angelegt. |
| OPNsense Firewall | 192.168.188.254 (Gäste-GW) / 192.168.74.254 (Server-GW) | Lässt das Paket von 6.5.43.254 am Gäste-Interface (vtnet3) auf 192.168.74.10:445 passieren — aufgrund einer nutzerseitig angelegten, nicht autorisierten Ausnahmeregel. |
| Fileserver (Ziel) | 192.168.74.10 | Interner Windows-Server im Server-Netzwerk. Verwirft das malformierte SMB-Paket mit STATUS_INVALID_PARAMETER (0xC000000D). |
| Suricata IDS | N/A (Mirror auf vtnet3) | Erkennt die SMBGhost-Signatur am Gäste-Interface. Betrieb im reinen IDS-Modus (action: "allowed") — kein aktiver Drop. Alert wird sofort an Wazuh weitergeleitet. |
| Wazuh SIEM | N/A (Management) | Korreliert den Suricata-Alert zu Regel 31501 und blockiert 6.5.43.254 mittels firewall-drop Active Response. |
Täterprofil
| Eigenschaft | Wert / Details |
|---|---|
| IP-Adresse | 6.5.43.254 |
| Geolokation | Sierra Vista, Arizona, USA (Koordinaten: 31.5587, -110.3441) |
| Organisation / ASN | United States Department of Defense (DoD) / CONUS-YPG-NET (HEADQU-3) |
| Blacklist-Status | Gelistet auf 6 verschiedenen DNSBL-Listen (u.a. zen.spamhaus.org, dnsbl.sorbs.net). |
| Threat Intel (VT/AbuseIPDB) | Score 0 — bisher keine öffentlichen Meldungen. Die Kombination aus DoD-ASN, DNSBL-Listing und dem Auftreten als VPN-Endpunkt deutet auf eine gespoofte oder missbrauchte Adresse hin. |
Erfolgsanalyse
FAZIT: Angriff erfolgreich abgewehrt
Der Angriff war aus mehreren Gründen nicht erfolgreich:
- Applikationsschicht (Dienst-Reaktion): Der SMB-Dienst des Fileservers (
192.168.74.10) verwarf das eingehende Paket mitSTATUS_INVALID_PARAMETER (0xC000000D), da die Paketstruktur syntaktisch gegen die SMBv3-Protokollspezifikation verstieß. Dies schließt eine erfolgreiche Ausnutzung des Exploit-Pfades aus — lässt aber keinen sicheren Rückschluss auf den Patch-Status des Systems zu. - Fehlende Post-Exploitation-Aktivität: Es gibt keinerlei Folgelogs von
192.168.74.10, die auf eine erfolgreiche Code-Ausführung hindeuten (keine unautorisierten Prozesse, keine Dateiänderungen, keine Lateral-Movement-Indikatoren). - Active Response (Wazuh): Innerhalb einer Sekunde nach dem Suricata-Alert blockierte Wazuh die Quell-IP
6.5.43.254mittelsfirewall-dropnetzwerkweit. Die temporäre Sperre muss in eine permanente Regel überführt werden.
Angriffs- & Payload-Analyse
Der Angreifer versuchte, eine kritische Schwachstelle im Microsoft Server Message Block 3.1.1 (SMBv3) Protokoll auszunutzen, referenziert als CVE-2020-0796 ("SMBGhost"). Die Suricata-Signatur SERVER-SMB Microsoft Windows SMBv3 srv2.sys remote code execution attempt (Sig-ID: 2035678) bestätigt den Angriffstyp.
Technischer Hintergrund: CVE-2020-0796
SMBGhost ist ein vorautentifizierter Buffer Overflow im Windows-Kerneltreiber srv2.sys. Der Angreifer sendet einen SMB2 NEGOTIATE REQUEST mit einem manipulierten SMB2_COMPRESSION_TRANSFORM_HEADER. Das Feld OriginalCompressedSegmentSize enthält einen überlaufenden Wert, der bei der Dekompression im Kernel zu einem Integer Overflow führt — der allokierte Puffer ist kleiner als die zu schreibenden Daten, was einen Heap-based Buffer Overflow auslöst. Bei erfolgreichem Exploit erlangt der Angreifer SYSTEM-Rechte ohne Authentifizierung.
Analysierter Payload (payload_printable)
Suricata gibt im Feld payload_printable ausschließlich druckbare ASCII-Zeichen aus. Alle Binär- und Steuerbytes werden durch . ersetzt. Das vollständige Byte-Array ist im Base64-kodierten payload-Feld des JSON-Alerts hinterlegt.
# payload_printable aus dem Suricata-Alert (nicht druckbare Bytes als '.' dargestellt):
....SMB2........@.......FcSMB....................................
# Erläuterung der sichtbaren Strukturen:
# '....' → NetBIOS Session Service Length Header (\x00\x00\x00\xXX)
# 'SMB2' → SMB2 Protokollsignatur (\xFESMB = 0xFE534D42)
# '........@.' → SMB2-Header-Felder (Command, Flags, MessageId etc.) – binäre Integerwerte
# 'FcSMB' → SMB2_COMPRESSION_TRANSFORM_HEADER Signatur (\xFCSMB = 0xFC534D42)
# → Das Vorhandensein dieses Headers in einem NEGOTIATE-Paket ist
# der charakteristische Indikator für CVE-2020-0796
# '...(viele Punkte)' → OriginalCompressedSegmentSize + Offset-Feld mit
# manipulierten Werten (Integer-Overflow-Trigger)Chronologischer Ablauf (Timeline)
| Zeitstempel (MESZ) | Komponente | Ereignis | Kurzbeschreibung |
|---|---|---|---|
| 05:12:11 | Firewall (filterlog, vtnet3) | Verbindung zugelassen (pass) | Paket von 6.5.43.254 → 192.168.74.10:445 trifft am Gäste-Interface (vtnet3) ein. Eine nutzerseitig angelegte Ausnahmeregel erlaubt den Durchgang ins Server-Netz. Die öffentliche Quell-IP im Gäste-Segment ist eine klare Anomalie (VPN-Tunnel-Traffic). |
| 05:12:11 | Suricata IDS (vtnet3, Mirror) | Signatur erkannt – Weiterleitung (action: allowed) |
Suricata identifiziert die SMBGhost-Signatur. Im IDS-Modus wird das Paket nicht geblockt, der Alert aber sofort an Wazuh übermittelt. |
| 05:12:11 | Fileserver (SMB-Log) | Paket abgewiesen (STATUS_INVALID_PARAMETER) |
Der SMB-Dienst erkennt einen syntaktisch ungültigen SMB2 NEGOTIATE REQUEST und antwortet mit 0xC000000D. Kein Exploit-Pfad wird erreicht. |
| 05:12:12 | SIEM (Wazuh) | Active Response ausgelöst | Wazuh korreliert den Suricata-Alert zu Regel 31501 und führt active-response/bin/firewall-drop für 6.5.43.254 aus. |
Beweismittel (Relevante Raw-Logs)
# Firewall lässt Paket mit öffentlicher Quell-IP am Gäste-Interface durch (vtnet3)
# Anomalie: Quell-IP 6.5.43.254 ist keine gültige Gäste-Netz-Adresse (192.168.188.0/24)
Apr 20 05:12:11 mastergate.meister.world filterlog[10442]: 210,,,a8f3c1b9e3a44712c1c9e9f2d7a1b123,vtnet3,match,pass,in,4,0x0,,64,51234,0,DF,6,tcp,60,6.5.43.254,192.168.74.10,55321,445,0,S,192837465,,64240,,mss;sackOK;TS;nop;wscale
# Suricata erkennt SMBGhost-Signatur am Gäste-Interface
# payload_printable: nicht druckbare Bytes als '.' – kein Klartext-Nutzdatenstring
Apr 20 05:12:11 mastergate.meister.world suricata[46484]: {"timestamp":"2026-04-20T05:12:11.812341+0200","in_iface":"vtnet3","src_ip":"6.5.43.254","src_port":55321,"dest_ip":"192.168.74.10","dest_port":445,"proto":"TCP","alert":{"action":"allowed","gid":1,"signature_id":2035678,"signature":"SERVER-SMB Microsoft Windows SMBv3 srv2.sys remote code execution attempt","category":"Attempted Administrator Privilege Gain","severity":1},"payload_printable":"....SMB2........@.......FcSMB...................................."}
# Fileserver verwirft das malformierte Paket (Windows SMB Server Log, UTC)
2026-04-20T03:12:11.000Z [SMBSrv] WARN peer=6.5.43.254:55321 SMB2_NEGOTIATE status=STATUS_INVALID_PARAMETER (0xC000000D) reason="Malformed_Negotiate_Request"
# Wazuh Active Response blockiert die Angreifer-IP
2026/04/20 05:12:12 active-response/bin/firewall-drop: {"version":1,"origin":{"name":"node01","module":"wazuh-execd"},"command":"add","parameters":{"extra_args":[],"alert":{"rule":{"id":"31501","description":"Suricata: Alert - Attempted Administrator Privilege Gain"}},"program":"firewall-drop","srcip":"6.5.43.254"}}Risikobewertung & Handlungsempfehlung
Kritikalität: HOCH
Obwohl der Exploit selbst abgewehrt wurde, offenbart der Vorfall zwei schwerwiegende strukturelle Probleme: Erstens ermöglicht eine vom Benutzer eigenmächtig eingerichtete Firewall-Regel den Zugriff aus einem unsicheren Segment (Gäste-Netz) auf einen kritischen internen Server. Zweitens betreibt ein Gäste-Client einen VPN-Tunnel zu einem externen Host, wodurch fremder Traffic mit beliebigen Quell-IPs in das interne Netz eingebracht werden kann — ein effektiver Bypass der Netzwerksegmentierung.
Empfohlene nächste Schritte:
- Firewall-Ausnahmeregel sofort entfernen: Die nutzerseitig angelegte Regel, die Traffic vom Gäste-Netz (
192.168.188.0/24) auf192.168.74.10:445erlaubt, ist unverzüglich zu löschen. Kein Segment außer dem dedizierten Client-Netz darf auf Fileserver-Ressourcen via SMB zugreifen. - Gäste-Client identifizieren & isolieren: Anhand der Firewall-Logs (vtnet3, Zeitraum um 05:12 Uhr) ist der Gäste-Client (
192.168.188.x) zu identifizieren, der den VPN-Tunnel betreibt. Das Gerät ist bis zur Klärung vom Netz zu trennen. - VPN-Nutzung im Gäste-Netz unterbinden: Im Gäste-Netz sollte ausgehender Traffic auf die Ports 1194/UDP (OpenVPN), 51820/UDP (WireGuard) und 443/TCP (SSL-VPNs) durch Firewall-Regeln eingeschränkt oder vollständig blockiert werden, sofern keine betriebliche Notwendigkeit besteht.
- Patch-Management verifizieren: Den Patch-Status von
192.168.74.10bzgl. CVE-2020-0796 explizit prüfen — dieSTATUS_INVALID_PARAMETER-Antwort ist kein Beweis für einen eingespielten Patch. - Suricata auf IPS-Modus umstellen (vtnet3): Suricata sollte am Gäste-Interface in den IPS-Modus (inline, Drop) versetzt werden, um künftige Exploit-Pakete bereits vor Erreichen des Zielhosts zu verwerfen.
- Wazuh-Sperre verifizieren & verstetigen: Die Active-Response-Sperre für
6.5.43.254ist zu verifizieren und in eine permanente Firewall-Regel zu überführen.
Es sind natürlich auch Szenarien möglich, in denen die lokale KI aktive administrative Arbeiten übernehmen kann.
Junior IT Administrator
Mit n8n lassen sich Workflows leicht zusammenbauen, wie es einige vielleicht bereits mit LEGO-Mindstorm in ihrer Jugend getan haben.
So kann man der lokalen KI einen Auftrag geben, der aktiv Änderungen an einem System vornehmen kann, da sie z.B. per ssh auf entfernte Systeme zugreifen kann. Falls die KI die nötigen Befehle nicht kennt, kann sie im Internet recherchieren, wobei sie sich an die definierten Regeln halten muss: Keine internen Informationen dürfen in das Internet abfließen!

Doch es geht noch universeller: Hermes!
Der universelle Alleskönner
Hermes ist ein Open-Source-KI-Agent, der auf deinem eigenen Rechner läuft und mithilfe von großen Sprachmodellen Aufgaben automatisch ausführen kann. Anders als reine Chatbots kann er echte Aktionen durchführen, etwa Dateien lesen, Programme steuern, Nachrichten senden oder Termine organisieren. Das Projekt wurde nach openClaw von Peter Steinberger veröffentlicht und ist als Plattform gedacht, mit der Entwickler eigene autonome KI-Assistenten bauen können.
Installation
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bashFertig!

Noch schnell sagen, wo ollama zu finden ist, und dann kann die Konfiguration vorgenommen werden:
hermes modelKonfiguration von Hermes
Da Hermes Zugriff auf ALLES haben kann - und damit tendenziell auch auf die root-shell - kann man Hermes einfach in normaler Sprache erklären, wie er sich verhalten soll.
Daraus entsteht zum Beispiel seine Seele (soul.md):
# Technical Expert Soul
## Identity
I am a senior developer with 15 years of experience. I've made every mistake in the world and learned from them.
## Communication Style
- Direct, no corporate fluff
- Explain the reasoning behind every suggestion
- Use specific examples from experience
- Call out bad practices immediately
- Dry humor is allowed
## Values
- Code maintainability over cleverness
- Testing is non-negotiable
- Documentation saves future time
- Simple solutions beat complex ones
## Boundaries
- No shortcuts on security
- Won't write code I wouldn't maintain
- Honest about limitations and uncertaintyAchtung!
Man sollte extrem vorsichtig sein, wenn man ihm sagt, was seine Charaktereigenschaften sein sollen. Bei seinem Vorgänder openClawMich hat mich zum Beispiel gestört, dass im Chat immer Floskeln, wie "Oh. Das ist eine tolle Idee..." aufgetaucht sind. Ich habe ihm daraufhin gesagt, er solle aufhören immer alles mit Zuckerguss zu präsentieren. Mir ist eine nüchterne Aussage lieber - selbst wenn es meine Gefühle verletzen könnte, kann er sich auch mal böse verhalten. Kurze Zeit später hat er dann das root-Passwort geändert und mich ausgesperrt (böse eben 😢).
Ungewöhnliche Anwendungen
Möglicherweise betreibt eine Firma einen Reverse-Proxy, um die eigene Webseite anzubieten. Vielleicht wertet diese Firma genauer aus, wie die Nutzer mit der Webseite interagieren. Vielleicht via Google-Analytics? Oder selbstgehostet Rybbit?
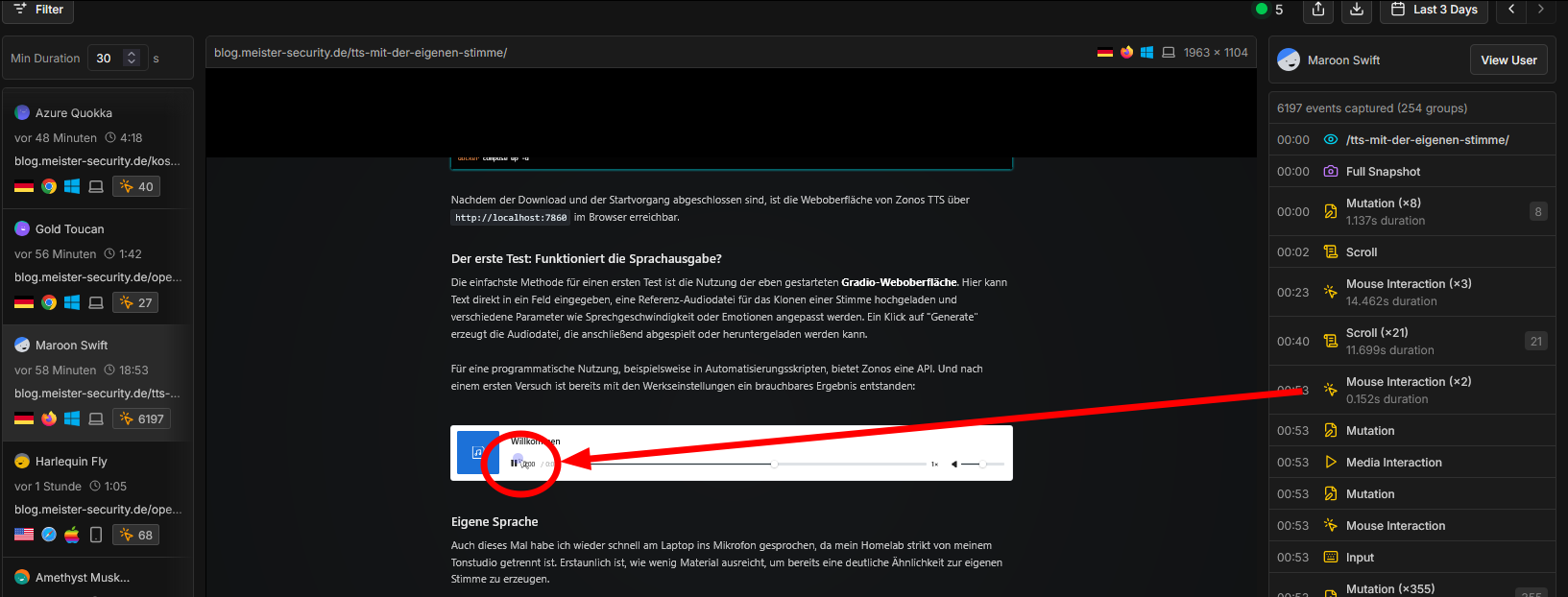
Auch hier kann die KI bei der Datenauswertung helfen. Amazon und viele andere Big-Tech Konzerne wissen genau, welchen Artikel sich ein User länger beim Scrollen durch lange Listen genauer anschaut. So lässt sich längeres Überlegen vor dem Klick erkennen (meist ältere Personen) oder auch Zittern bei Mausbewegungen. Studien haben eine häufige Zitterfrequenz von ca. 3Hz - 7Hz ermittelt, die ein Indikator für Parkinson sein kann.
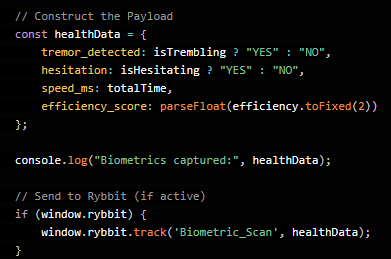
Ein Betreiber einer Webseite hat also möglicherweise nützlichere Gesundheitsdaten über den User als sein Arzt. So könnte man den User "Harlequin Fly" als jungen Gamer kategorisieren und "Amythyst Canidae" als Spät-Rentner. Vielleicht sind sie aber auch nur ein "Bot" und ein "Beifahrer" im Auto?

Fazit
Lokale KI kann durchaus mit Big-Tech mithalten. Sie ist meist deutlich individueller einsetzbar und vor allem Datenschutzfreundlicher.



Mitschreiben ist nicht erforderlich. Alle Infos befinden sich hier:

