Firewall-Reports, die Kunden wirklich verstehen
Automatisierte LaTeX-Reports aus OPNsense-Daten schaffen Transparenz und Vertrauen.


Ich habe über die Feiertage mein Script verbessert, das Berichte über die Aktivitäten auf OPNsense-Firewalls generiert. Und wenn ich schon einmal dabei bin, möchte ich hier kurz einige Elemente vorstellen, und wie ich generell mit diesem Werkzeug verfahre.
Mein Bash-Skript verbindet sich per SSH mit einer OPNsense-Appliance, extrahiert Systemdaten, Logfiles und RRD-Datenbanken und erzeugt daraus ein vollständiges LaTeX-PDF mit Bandbreitengrafiken, IDS-Auswertungen und einer Systemzustandsanalyse. Warum dieser Aufwand lohnt, obwohl Wazuh, Grafana und Uptime Kuma bereits alles im Blick behalten, ist die eigentlich interessante Frage.
Übersicht

Echtzeit-Monitoring und seine blinden Flecken
Wazuh, Grafana und Uptime Kuma sind exzellente Werkzeuge für das, wofür sie gebaut wurden: Sie zeigen, was gerade jetzt passiert. Ein SIEM schlägt Alarm, wenn ein Angriff stattfindet. Ein Dashboard leuchtet rot, wenn ein Dienst ausfällt. Ein Availability-Monitor piept, wenn ein Host nicht antwortet.

Was diese Werkzeuge strukturell nicht leisten, ist der Blick auf Entwicklungen über Zeit aus der Perspektive eines Außenstehenden. Eine CPU-Auslastung von 80% ist im Dashboard ein gelber Balken. Ob dieser Balken vor einem Jahr noch bei 30% lag und seitdem stetig gewachsen ist, erschließt sich nur demjenigen, der aktiv in die historischen Daten schaut und den Verlauf interpretiert. Das tut niemand, der nicht explizit dazu aufgefordert wird - und genau hier liegt der erste unterschätzte Wert des automatisierten Reports.
Der zweite blinde Fleck betrifft die Konfiguration der Firewall selbst. Intrusion Detection erkennt Angriffe im Netzwerkverkehr. Was sie nicht erkennt: Vielleicht ein neuer Benutzer namens PRINTER, der still und leise auf der Appliance angelegt wurde. Ein zusätzlicher Cron-Job, der nächtlich eine Verbindung nach außen aufbaut. Ein Shell-Befehl, der beim Systemstart ausgeführt wird und eine Backdoor öffnet. Diese Vektoren liegen unterhalb der Ebene, auf der klassisches Netzwerk-Monitoring ansetzt - und genau deshalb sind sie so gefährlich.
Warum der Kunde einen Bericht bekommt - und kein Dashboard-Passwort
Der pragmatischste Grund: Kunden öffnen E-Mail-Anhänge. Sie loggen sich nicht in Grafana ein.
Ein Geschäftsführer, der für seine IT-Sicherheit bezahlt, möchte nicht lernen, wie Prometheus-Metriken zu interpretieren sind. Er möchte einmal pro Woche ein Dokument in seinem Posteingang finden, das ihm in verständlicher Form zeigt, dass seine Systeme überwacht werden, dass Angriffe erkannt und abgewehrt wurden und dass die Leitungskapazität noch ausreicht. Dieses Dokument ist keine Vereinfachung der Monitoring-Daten - es ist deren Übersetzung in eine kommunizierbare Form.
Gleichzeitig dient der Report als Nachweis einer erbrachten Dienstleistung. Im Kontext von Versicherungsverträgen, ISO-27001-Audits oder BSI-Grundschutz-Nachweisen ist ein datiertes, regelmäßig erzeugtes Dokument mehr wert als ein Live-Dashboard, das keine Snapshot-Historie hinterlässt. Eine PDF-Datei vom 12. Mai belegt, dass an diesem Tag der Systemzustand aktiv analysiert wurde - ein Screenshot aus Grafana tut das nicht.

Ein weiterer, oft übersehener Aspekt: Der Report schließt den PDCA-Kreislauf (Plan - Do - Check - Act). Echtzeit-Monitoring ist reaktiv. Der wöchentliche Report ist die strukturierte Check-Phase, in der nicht auf Alarme reagiert, sondern aktiv nach Auffälligkeiten gesucht wird. Ohne diese Phase ist IT-Sicherheit kein Prozess, sondern Feuerlöschen.
Aufbau des Reports - Abschnitt für Abschnitt
Das Skript erzeugt eine vollständige .tex-Datei, die durch zwei aufeinanderfolgende pdflatex-Läufe in ein professionell formatiertes PDF kompiliert wird. Der zweite Durchlauf ist notwendig, damit Inhaltsverzeichnis, Abbildungsverzeichnis und Listing-Verzeichnis korrekt erzeugt werden.
Seit meiner Zeit in der Universität schreibe ich Texte in LaTeX. Ich muss mich dabei nie um die optische Gestaltung kümmern. Jedes Dokument ist ein Genuss anzuschauen. Die Struktur ist dabei in mehrere Kapitel unterteilt, die jeweils unterschiedliche Aspekte der Firewall beleuchten.

Systembeschreibung und Scope
Der erste Abschnitt beschreibt, um welche Firewall-Appliance es sich handelt und welchen Berichtszeitraum das Dokument abdeckt. Klingt banal - ist es aber nicht, wenn man mehrere Kunden mit jeweils mehreren Standorten betreut. Das Skript wird mit dem Hostnamen der Firewall als Parameter aufgerufen ($FWGW) und zieht sich via SCP zunächst die komplette Konfigurationsdatei. Mein User, der nur lesen darf - also der ro-man - kurz: roman erledigt das für mich 😄:
scp roman@${FWGW}:/conf/config.xml ${TMPDIR}/${FWGW}-config.xmlOPNsense speichert seine gesamte Konfiguration - von Interfaces über Benutzer bis hin zu IDS-Einstellungen - in einer einzigen XML-Datei unter /conf/config.xml. Das ermöglicht es, mit xmlstarlet gezielt einzelne Konfigurationselemente abzufragen, ohne auf der Appliance selbst komplexe Skripte ausführen zu müssen.

Betriebszeit und Systemstabilität
Die Uptime einer Firewall ist ein oft unterschätzter Indikator. Eine hohe Betriebszeit spricht für Stabilität und ordnungsgemäßen Betrieb. Eine auffällig kurze Betriebszeit hingegen kann auf einen ungeplanten Neustart, eine Wartungsmaßnahme oder - im schlimmsten Fall - auf eine Manipulation hinweisen.
UPTIME=$(ssh roman@${FWGW} "uptime | sed -e 's/.*. up //;s/ day.*//'")Der Wert landet direkt im LaTeX-Report und wird fett hervorgehoben. Wer den Report regelmäßig liest, bemerkt sofort, wenn der Zähler unerwartet zurückgesetzt wurde - auch wenn kein Wartungsfenster geplant war.

CPU-Last aus RRD-Datenbanken
OPNsense verwendet RRDtool zur kontinuierlichen Aufzeichnung von Systemmetriken. Die RRD-Datenbank für die CPU-Last liegt auf der Appliance unter /var/db/rrd/system-processor.rrd. Das Skript transferiert diese Datenbank per SSH und rrdtool dump | rrdtool restore auf den Report-Server und extrahiert die Rohdaten für die anschließende Visualisierung.
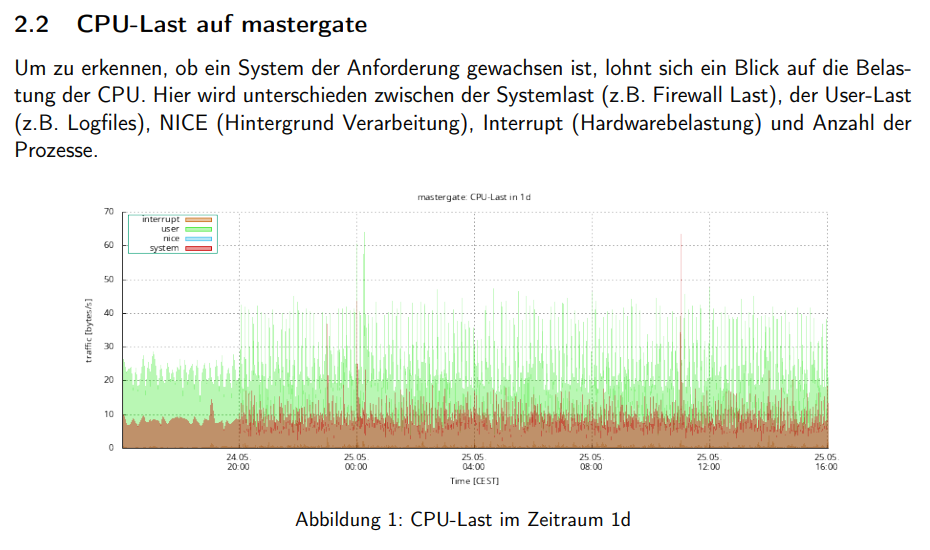
Aufgezeichnet werden vier CPU-Kategorien: user (Prozesse im User-Space, z.B. Logfile-Verarbeitung), system (Kernel-Prozesse, also die eigentliche Firewall-Last), nice (Hintergrundprozesse mit niedrigerer Priorität) und interrupt (Hardware-Interrupts). Diese Unterscheidung ist relevant, weil ein System unter Angriff typischerweise eine stark erhöhte interrupt- oder system-Last zeigt, während eine hohe user-Last auf intensive Log-Verarbeitung oder aktive Dienste hindeutet.
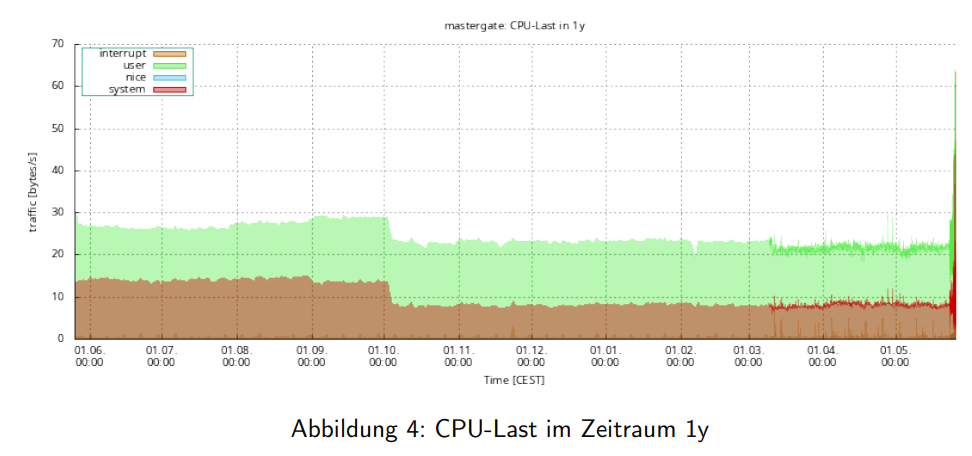
Die Visualisierung erfolgt für vier Zeiträume: 1 Tag, 1 Woche, 1 Monat und 1 Jahr. Dieser Mehrfach-Zeitraum-Ansatz ist kein Zufall - er ermöglicht gleichzeitig die Beurteilung von Tagesspitzen und langfristigen Trends.
Netzwerk-Interfaces und externe Erreichbarkeit
Über xmlstarlet wird die Liste aller konfigurierten Interfaces aus der config.xml extrahiert und um die tatsächlich laufende Konfiguration via ifconfig ergänzt. Das Ergebnis ist eine strukturierte Übersicht: logischer Interface-Name, BSD-Gerätename und virtuelles Interface.
Zusätzlich wird die externe IP-Adresse ermittelt und mit einem traceroute kommentiert. Bei Mobilfunk-Providern, die Carrier-Grade NAT einsetzen, weicht die externe IP der Firewall von der öffentlich sichtbaren IP ab - ein Detail, das bei der Fehlersuche und bei der Beurteilung der Erreichbarkeit relevant ist.
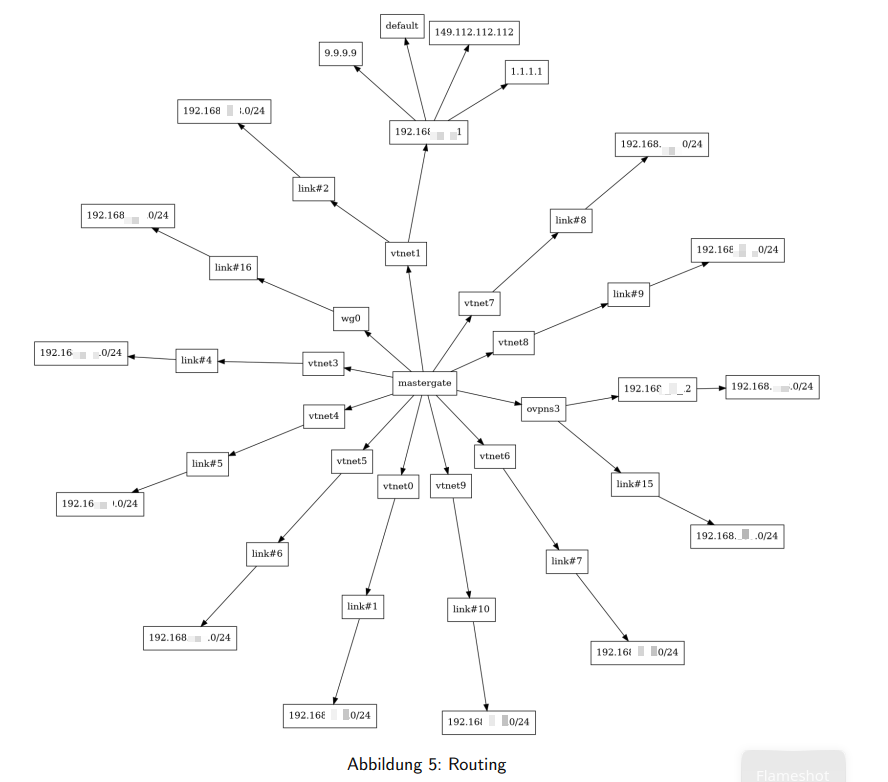
Die Routing-Tabelle wird als grafische Darstellung in den Report aufgenommen. In früheren Versionen des Skripts wurde hierfür Graphviz mit neato eingesetzt, das aus einer generierten DOT-Datei direkt ein PNG erzeugte. In der aktuellen Version ist die Visualisierung in reines LaTeX/TikZ überführt worden - dazu weiter unten mehr.
Benutzer und persistente Backdoors
Dieser Abschnitt ist einer der sicherheitstechnisch wertvollsten und gleichzeitig unspektakulärsten Teile des Reports. Das Skript extrahiert alle auf der Appliance angelegten Benutzer direkt aus der config.xml:
xmlstarlet sel -t -m "opnsense/system/user" -v "name" -o ";" -v "descr" -n \
${TMPDIR}/${FWGW}-config.xmlZusätzlich werden Shell-Befehle ausgelesen, die beim Systemstart ausgeführt werden (shellcmd via pfSsh.php, da ich im Script erkenne, ob es auf einer pfsense oder OPNsense läuft), sowie alle konfigurierten Cron-Jobs. Allein diese drei Checks decken die häufigsten Persistenzmechanismen ab, die ein Angreifer nach einer erfolgreichen Kompromittierung einrichten würde. Eine unerwartete Änderung in dieser Liste - ein neuer Benutzer, ein neuer Startup-Befehl, ein neuer nächtlicher Cron-Job - fällt beim wöchentlichen Vergleich sofort auf. Das ist kein theoretisches Szenario, sondern eines der ersten Dinge, die nach einer Kompromittierung passieren.
Bandbreiten-Analyse - WAN und interne Interfaces
Das Kapitel zur Bandbreite ist in externe WAN-Interfaces und interne Interfaces aufgeteilt. Für jedes Interface werden die RRD-Daten von der Appliance geholt und für alle vier Zeiträume ausgewertet. Auch hier liegt der Wert im Trend: Einzelne Tagesspitzen sind für Grafana und Prometheus interessant. Ob der Gesamtdurchsatz eines Standorts über das Jahr gesehen um 40% gewachsen ist und der bestehende Leitungsvertrag damit absehbar an seine Grenzen stoßen wird, ist eine Information, die aus dem Kontext des wöchentlichen Reports hervorgeht - nicht aus einem Dashboard, das niemand rückblickend analysiert.
Für WAN-Interfaces ist zusätzlich der blocked-Traffic interessant. Stetig wachsender blockierter eingehender Traffic kann auf einen gezielten Scan oder einen beginnenden DDoS-Angriff hindeuten, der noch unterhalb der Alarmschwelle liegt - ein schleichender Anstieg über Wochen, den ein Realtime-Dashboard kaum auffällig macht.
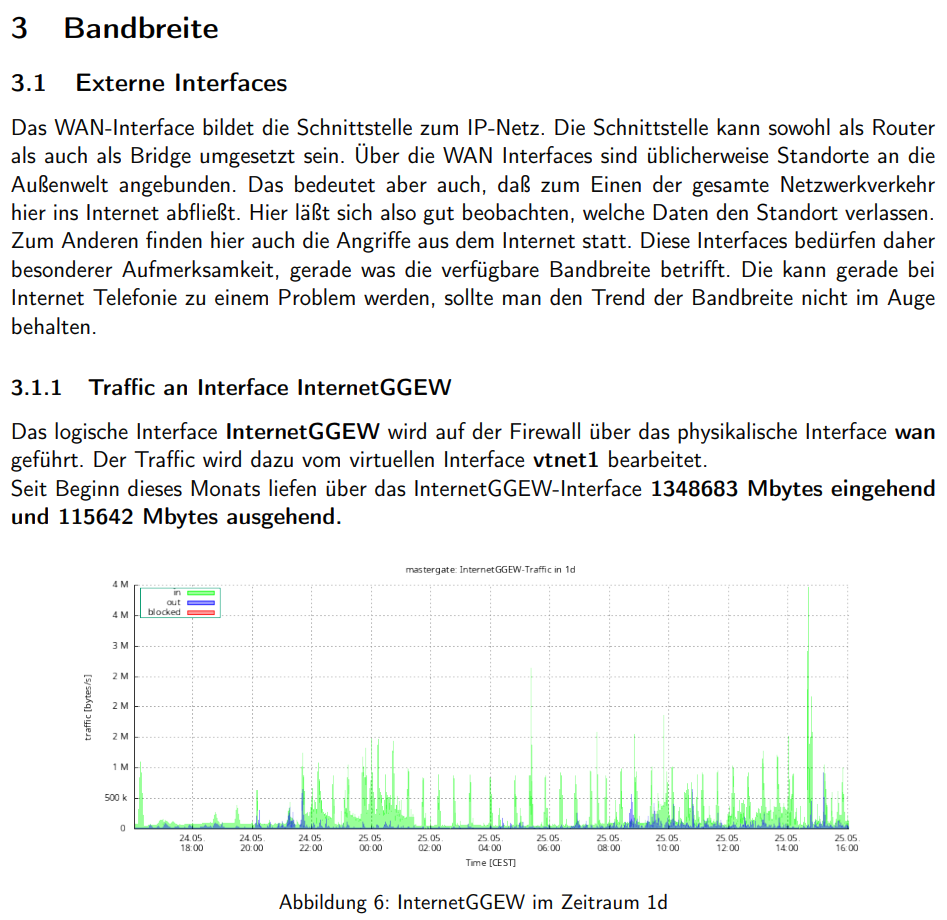
Der Monats-Traffic-Summary ist ebenfalls Teil des Reports:
ssh roman@${FWGW} "rrdtool fetch /var/db/rrd/${IFACE}-traffic.rrd AVERAGE -r 3600 \
-s \"00 $(date '+%m/01/%Y')\" -e now" | grep -v nan | \
awk '{ sum1 += $2/(1024*1024); sum2 += $3/(1024*1024) } \
END { printf "%u Mbytes eingehend und %u Mbytes ausgehend.\n", sum1*3600, sum2*3600; }'Diese eine Zeile gibt den akkumulierten Datendurchsatz seit Monatsbeginn aus. Im Kontext eines Kundengesprächs über Leitungskosten oder Flatrate-Grenzen ist das ein handfestes Argument.
Suricata-IDS-Auswertung - das Herzstück des Reports
Der umfangreichste und technisch interessanteste Abschnitt ist die Auswertung der Suricata-Logs. Suricata schreibt seine Events in eine strukturierte JSON-Logdatei (eve.json), die mit jq sehr effizient verarbeitet werden kann. Das Skript unterstützt daneben auch Snort-Logs im CSV-Format, sofern Snort auf der Appliance aktiv ist - die Auswertungslogik ist dabei ähnlich, die Datenstruktur aber eine andere.
Das Skript sammelt zunächst alle aktuellen Eve-Log-Dateien per SSH und komprimiert den Transfer, um Bandbreite zu sparen:
ssh roman@${FWGW} "cat \$(find /var/log/suricata/ -name 'eve*' -mtime -40 | tail -r) \
| gzip" | gzip -d > ${TMPDIR}/${FWGW}-suricata.logAus den gesammelten Daten werden pro Interface zwei Auswertungen erstellt.
Top Attacker listet die Quell-IP-Adressen auf, die am häufigsten in Alerts aufgetaucht sind, sortiert nach Häufigkeit. Dieser Liste ist zu entnehmen, ob ein einzelner Angreifer besonders persistent ist oder ob der Angriff von einer breiten IP-Verteilung kommt - letzteres ist typisch für verteilte Scanner-Botnets, während eine einzelne persistente IP auf gezieltes Interesse hindeutet.

Alerts nach Signatur zeigt die häufigsten Suricata-Signaturen, ebenfalls nach Häufigkeit sortiert. Hier zeigt sich, welche Angriffskategorien dominant sind: handelt es sich um Port-Scans (ET SCAN), um bekannte Exploit-Versuche (ET EXPLOIT), um Policy-Verletzungen (ET POLICY) oder um Command-and-Control-Kommunikation (ET TROJAN)? Diese Kategorisierung ist für ein faktenbasiertes Gespräch mit dem Kunden über die aktuelle Bedrohungslage unverzichtbar.
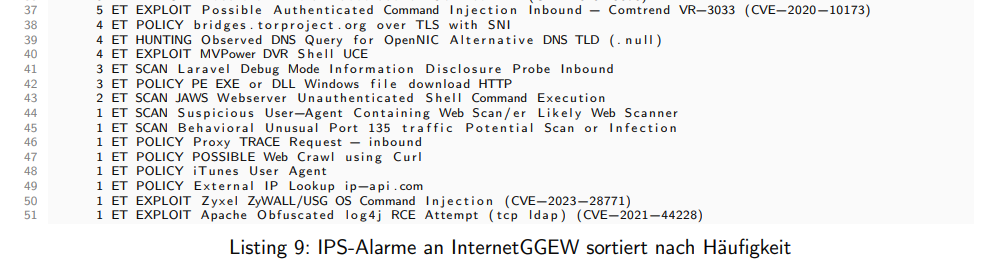
Grafiken direkt aus LaTeX - pgfplots
In früheren Versionen des Skripts wurde Gnuplot für die Grafikerstellung eingesetzt. Gnuplot ist mächtig, erzeugt aber externe PNG-Dateien, die in den LaTeX-Report eingebunden werden. Das bedeutet zwei Werkzeugketten, zwei Fehlerquellen und eine Abhängigkeit von einem externen Binary, das auf dem Report-Server installiert sein muss. Fällt die PNG-Erzeugung lautlos fehl, enthält der Report ein leeres Bild oder bricht bei der Erstellung ab.
Die aktuelle Version des Skripts erzeugt Grafiken direkt in LaTeX, mithilfe von pgfplots und TikZ. Das Prinzip ist elegant: Anstatt Gnuplot ein Bild rendern zu lassen, das dann eingebettet wird, schreibt das Skript direkt LaTeX-Code in den Report, den pdflatex beim Kompilieren selbst in eine Vektorgrafik umwandelt. Keine externe Abhängigkeit, keine Zwischendateien, kein möglicher Größenfehler bei PNG-Auflösungen.
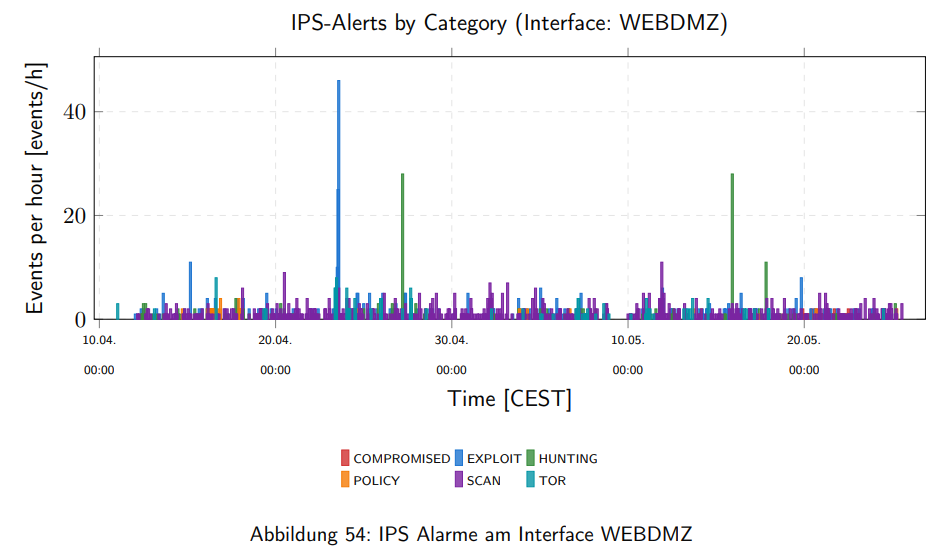
Am Beispiel der Suricata-Kategorienauswertung zeigt sich, wie das in der Praxis funktioniert.
Schritt 1 - Kategorien dynamisch ermitteln: Aus den Eve-Log-Daten werden alle vorhandenen Alarmdaten-Kategorien (ET SCAN, ET POLICY, ET EXPLOIT usw.) per grep und awk extrahiert. Das ist wichtig, weil die Kategorien je nach Suricata-Regelwerk und aktueller Bedrohungslage variieren:
CATS=$(grep "$IFCONFIG" "${TMPDIR}/${FWGW}-suricata.log" | \
grep -o '"signature":"ET [^ ]*' | awk '{print $2}' | sort -u)Schritt 2 - Koordinaten erzeugen: Für jede Kategorie werden die Ereignisse nach Stunde gezählt und als pgfplots-Koordinatenpaare formatiert. jq extrahiert den Zeitstempel, sed kürzt ihn auf Stunden-Granularität, uniq -c zählt die Ereignisse pro Stunde:
COORDS=$(grep "$IFCONFIG" "${TMPDIR}/${FWGW}-suricata.log" | \
grep "\"signature\":\"ET $CAT" | \
jq -r .timestamp | \
sed -e 's/:.*//; s/T/ /; s/$/:00/' | \
sort | uniq -c | \
awk '{print "(" $2 " " $3 ", " $1 ")"}' | tr '\n' ' ')Das Ergebnis ist eine Folge von Koordinatenpaaren im Format (2026-05-19 14:00, 42), die pgfplots direkt als Zeitreihe interpretieren kann.
Schritt 3 - Farben dynamisch zuweisen: Da die Anzahl der Kategorien pro Interface variiert, verwaltet das Skript eine Farbpalette und weist jeder Kategorie dynamisch eine Farbe zu - mit Modulo-Arithmetik, damit auch bei mehr als 10 Kategorien kein Array-Overflow passiert:
COLORS=("#D32F2F" "#1976D2" "#388E3C" "#F57C00" "#7B1FA2" \
"#0097A7" "#5D4037" "#C2185B" "#616161" "#FBC02D")
CURRENT_COLOR=${COLORS[$((IDX % NUM_COLORS))]}
COLOR_HEX=${CURRENT_COLOR#\#}Im generierten LaTeX-Code landet das als \definecolor{catcolor0}{HTML}{D32F2F}.
Schritt 4 - pgfplots-Diagramm schreiben: Das Skript schreibt den vollständigen pgfplots-Code direkt in die .tex-Datei. Die Besonderheit: pgfplots unterstützt Datums-Koordinaten nativ via date coordinates in=x und date ZERO, was die korrekte Darstellung von Zeitreihen ohne externe Werkzeuge ermöglicht. Das date ZERO ist dabei das Referenzdatum für die interne Koordinatenberechnung und wird dynamisch aus dem ersten Log-Eintrag ermittelt:
\begin{axis}[
width=\textwidth, height=8.0cm,
date coordinates in=x,
date ZERO={2026-05-01},
xticklabel={\day.\month.\\ \hour:\minute},
ybar, bar width=1.0pt,
ymin=0,
legend to name={leg-WAN},
legend style={legend columns=3, font=\tiny},
]
\addplot[draw=catcolor0, fill=catcolor0, fill opacity=0.8] coordinates {
(2026-05-19 14:00, 42) (2026-05-19 15:00, 17) ...
};
\addlegendentry{SCAN}Die Legende wird via legend to name vom Diagramm getrennt und separat platziert - das hält das Diagramm selbst sauber und vermeidet Überlagerungen bei vielen Kategorien.
Ein praktisches Detail im Fehlerfall: Falls eine Kategorie im abgefragten Zeitraum keine Daten liefert, überspringt das Skript sie kommentarlos. Und falls das gesamte Diagramm leer wäre - weil der Report-Zeitraum keine Suricata-Events enthält - erscheint stattdessen ein LaTeX-Block mit dem Hinweis "Keine Daten für diesen Zeitraum vorhanden." Kein Absturz, kein leeres Bild, keine Fehlermeldung im PDF.
Der eigentliche Wert für den Kunden - was die meisten übersehen
Bisher wurde beschrieben, was der Report enthält. Nun zur eigentlich wichtigen Frage: Warum ist er für den Kunden wertvoll, obwohl doch alles schon irgendwo in einem Dashboard steht?
Vergleichbarkeit über Zeit ist der vielleicht unterschätzteste Aspekt. Ein Grafana-Dashboard zeigt den aktuellen Stand. Ein Ordner mit 52 PDF-Reports zeigt das Jahr. In diesem Ordner lässt sich nachschlagen, wann genau ein bestimmter Angreifertyp erstmals aufgetaucht ist, wann die CPU-Last begonnen hat zu steigen und wann der erste unbekannte Benutzer auf der Appliance erschienen ist. Das ist forensisch wertvoll - und es funktioniert auch dann noch, wenn das Monitoring-System selbst kompromittiert oder ausgefallen ist.
Vertrauen als messbares Produkt ist ein weiterer Punkt, mit dem viele IT-Dienstleister kämpfen. "Nichts ist passiert" ist schwer zu verkaufen. Ein wöchentlicher Report, der zeigt, wie viele Angriffsversuche abgewehrt wurden, wie viele Suricata-Alarme ausgelöst wurden und welche IPs dabei besonders aktiv waren, macht Sicherheit sichtbar und greifbar. Der Kunde sieht, dass etwas passiert - und dass jemand hinschaut. Das rechtfertigt das Betreuungsbudget auf eine Art, die kein SLA-Dokument je leisten könnte.
Compliance und Versicherbarkeit gewinnen an Bedeutung. Die Cyber-Versicherungslandschaft hat sich deutlich verschärft. Versicherer fragen zunehmend nach Nachweisen, dass Sicherheitsmaßnahmen nicht nur vorhanden, sondern auch aktiv überwacht werden. Ein regelmäßiger, datierter Bericht, der Systemzustand und Sicherheitsereignisse dokumentiert, ist ein starkes Argument im Schadensfall - und unter Umständen die Voraussetzung dafür, dass der Versicherer überhaupt leistet.
Der Blick auf die Konfiguration ist vielleicht der am häufigsten übersehene Punkt. Suricata und Wazuh überwachen Netzwerkverkehr und Systemereignisse. Sie überwachen nicht, welche Benutzer auf der Firewall selbst angelegt sind. Wer aber jede Woche eine Liste der Firewall-Benutzer, Autostart-Befehle und Cron-Jobs etc. liest, bemerkt sofort, wenn dort plötzlich ein backup_user auftaucht, der letzte Woche noch nicht da war. Das ist einer der ersten Schritte nach einer erfolgreichen Kompromittierung - und eine der am wenigsten automatisch überwachten Angriffsflächen.
Bandwidth-Planung als Nebenprodukt schließt den praktischen Wert ab. Der Jahresverlauf der Bandbreite, wie er in den Reports dokumentiert wird, ist die Grundlage für ein fundiertes Gespräch mit dem Kunden über Leitungsupgrades oder Vertragswechsel. Ohne diese Daten ist eine solche Empfehlung eine Vermutung. Mit ihnen ist es ein belegtes Argument.
Voraussetzungen und Betrieb
Das Skript läuft auf einem Linux-Server, der per SSH Zugriff auf die OPNsense-Appliances hat. Auf dem Report-Server werden folgende Werkzeuge benötigt:
# Debian/Ubuntu
apt install rrdtool xmlstarlet jq texlive-full openssh-clienttexlive-full klingt nach Overkill, ist aber der einfachste Weg, alle benötigten Pakete - darunter pgfplots, tikz, listings, fancyhdr und ifsym - verfügbar zu machen. Wer Plattenplatz sparen möchte, kann mit texlive-latex-extra und gezielten Nachinstallationen arbeiten, spart damit aber vor allem Nerven.
Das fertige PDF wird per SCP auf einen Webserver übertragen und eine Push-Benachrichtigung via selbstgehosteter ntfy-Instanz verschickt:
curl -u "$MM_API_USER":"$MM_API_PASS" \
-H "Title: Firewallreport: ${FWGW}" \
-H "Priority: 2" \
-H "Tag: fire" \
-d "Firewall-Report unter https://www.firmendomain.tld/reports/${FWGW}-report.pdf" \
https://ntfy.meister-security.de/reportsDie Push-API folgt dem ntfy-Protokoll, sodass der Report auf dem Smartphone des Administrators landet, sobald er fertig erzeugt wurde - ohne E-Mail-Relay, ohne externen Dienst. Ein weiterer Security-Aspekt: Die sensiblen Daten liegen in einem geschützten Kunden-Bereich, von dem sich der Kunde den Bericht herunterladen kann. So werden sie nicht bei Microsoft (Outlook) oder Google ungewollt weiterverarbeitet.

Das Skript wird via Cron in einem definierten Intervall aufgerufen, wobei CRONINTERVAL steuert, welchen Zeitraum die IDS-Auswertung abdeckt. Der Report-Server selbst benötigt keine permanente Verbindung zur Appliance - er öffnet beim Skriptaufruf eine SSH-Session, holt alle Daten, schließt die Verbindung und kompiliert das PDF lokal. Die Firewall bemerkt den Report-Prozess kaum.
Fazit
Ein automatisierter Firewall-Report ist kein Ersatz für Echtzeit-Monitoring - er ist dessen Gedächtnis und Stimme nach außen. Wo Dashboards den Moment zeigen, zeigt der Report den Trend; wo Alerting auf Ereignisse reagiert, schafft der Report Dokumentation und Nachweisbarkeit. Besonders der Blick auf Benutzerlisten, Autostart-Befehle und andere Prozesse auf der Firewall selbst liefert eine Sicherheitsperspektive, die kein SIEM-Alert abdeckt - und der Kunde bekommt jede Woche ein greifbares Zeichen dafür, dass jemand aktiv hinschaut.